Revised:
Kertoivatko koehenkilöt totuuden?
Itseraportointitietojen luotettavuus on kyselytutkimuksen akilleenkantapää. Esimerkiksi mielipidetutkimusten mukaan yli 40prosenttia amerikkalaisista käy viikoittain kirkossa. Hadaway ja Marlar (2005) päättelivät kuitenkin kirkossakäyntitietoja tutkimalla, että todellinen kirkossakäynti oli alle 22 prosenttia. Seth Stephens-Davidowitz (2017) löysi uraauurtavassa teoksessaan ”Everybody lies” (Kaikki valehtelevat) runsaasti todisteita siitä, että useimmat ihmiset eivät tee sitä, mitä sanovat, eivätkä sano sitä, mitä tekevät. Esimerkiksi vastauksena kyselyihin useimmat äänestäjät ilmoittivat, ettei ehdokkaan etnisellä alkuperällä ole merkitystä. Tarkistamalla hakusanoja Googlessa Sephens-Davidowitz havaitsi kuitenkin päinvastaista.Erityisesti, kun Googlen käyttäjät kirjoittivat sanan ”Obama”, he yhdistivät hänen nimensä aina joihinkin rotuun liittyviin sanoihin.
Verkkopohjaista opetusta koskevaa tutkimusta varten voidaan hankkia verkkokäyttäytymistietoja analysoimalla käyttäjän käyttölokia, asettamalla evästeitä tai lataamalla välimuisti. Näiden vaihtoehtojen soveltuvuus voi kuitenkin olla rajallinen. Esimerkiksi käyttäjän käyttölokin avulla ei voida jäljittää käyttäjiä, jotka seuraavat linkkejä toisille verkkosivustoille. Lisäksi evästeiden tai välimuistin käyttö voi aiheuttaa ongelmia yksityisyyden suojaan. Näissä tilanteissa käytetään kyselytutkimuksilla kerättyjä itse ilmoitettuja tietoja. Tämä herättää kysymyksen: Kuinka tarkkoja itse ilmoitetut tiedot ovat? Cook ja Campbell (1979) ovat huomauttaneet, että tutkittavat a) pyrkivät raportoimaan sen, mitä he uskovat tutkijan odottavan näkevän, tai b) raportoivat sen, mikä kuvastaa myönteisesti heidän omia kykyjään, tietojaan, uskomuksiaan tai mielipiteitään. Toinen tällaiseen aineistoon liittyvä huolenaihe liittyy siihen, pystyvätkö koehenkilöt muistamaan tarkasti aiemmat käyttäytymisensä. Psykologit ovat varoittaneet, että ihmisen muisti on virheellinen (Loftus, 2016; Schacter, 1999). Joskus ihmiset ”muistavat” tapahtumia, joita ei koskaan tapahtunut. Näin ollen itse raportoitujen tietojen luotettavuus on kyseenalainen.Vaikka tilastolliset ohjelmistopaketit kykenevät laskemaan lukuja jopa 16-32 desimaalin tarkkuudella, tämä tarkkuus on merkityksetön, jos tiedot eivät voi olla tarkkoja edes kokonaislukujen tasolla. Varsin monet tutkijat ovat varoittaneet tutkijoita siitä, kuinka mittausvirhe voi lamauttaa tilastollisen analyysin (Blalock, 1974), ja ehdottaneet, että hyvä tutkimuskäytäntö edellyttää kerättyjen tietojen laadun tarkastelua (Fetter,Stowe, & Owings, 1984).
Vääristymä ja varianssi
Mittausvirheisiin sisältyy kaksi osatekijää, nimittäin vääristymä (bias) ja vaihteluvirhe (variance error)
vääristyneisyydestä ja vaihteluvirheestä
Vääristyneisyydellä (bias) tarkoitetaan systemaattista virhettä,sillä se on taipuvainen sysäämään raportoitavan pistemäärän johonkin äärimmäiseen ääripäähään. Esimerkiksi useissa älykkyysosamäärätestien versioissa on todettu olevan vinoutumia muita kuin valkoihoisia kohtaan. Se tarkoittaa, että mustat ja latinalaisamerikkalaiset saavat yleensä alhaisemmat pisteet riippumatta heidän todellisesta älykkyydestään. Muuttuva virhe, joka tunnetaan myös nimellä varianssi, on yleensä satunnainen. Toisin sanoen ilmoitetut pisteet voivat olla joko todellisten pisteiden ylä- tai alapuolella (Salvucci, Walter, Conley, Fink, & Saba, 1997).
Näistä kahdesta mittausvirhetyypistä tehdyillä havainnoilla on erilaisia seurauksia. Esimerkiksi tutkimuksessa, jossa verrattiin itse ilmoitettuja tietoja pituudesta ja painosta suoraan mitattuihin tietoihin (Hart & Tomazic, 1999), havaittiin, että koehenkilöillä on taipumus ilmoittaa pituuttaan liikaa mutta painoaan liian vähän. On selvää, että tällainen virhemalli on pikemminkin harhaa kuin varianssia. Mahdollinen selitys tälle vääristymälle on se, että useimmat ihmiset haluavat antaa itsestään paremman fyysisen kuvan muille. Jos mittausvirhe on kuitenkin satunnainen, selitys voi olla monimutkaisempi.
Voidaan väittää, että muuttujan virheet, jotka ovat luonteeltaan satunnaisia, kumoaisivat toisensa eivätkä siten olisi uhka tutkimukselle. Esimerkiksi ensimmäinen käyttäjä voi yliarvioida Internet-aktiviteettinsa 10 prosenttia, mutta toinen käyttäjä voi aliarvioida omansa 10 prosenttia. Tässä tapauksessa keskiarvo saattaa silti olla oikea. Yli- ja aliarviointi kuitenkin lisää jakauman vaihtelua. Monissa parametrisissa testeissä käytetään virheterminä ryhmän sisäistä vaihtelua. Suurentunut vaihtelu vaikuttaisi varmasti testin merkitsevyyteen. Jotkin tekstit saattavat vahvistaa edellä mainittua väärää käsitystä. Esimerkiksi Deese (1972) sanoi,
Statistinen teoria kertoo meille, että havaintojen luotettavuus on verrannollinen niiden lukumäärän neliöjuureen. Mitä enemmän havaintoja on, sitä enemmän on satunnaisvaikutuksia. Ja tilastollisen teorian mukaan mitä enemmän satunnaisvirheitä on, sitä todennäköisemmin ne kumoavat toisensa ja tuottavat normaalijakauman (s.55).
Ensiksikin on totta, että otoskoon kasvaessa jakauman varianssi pienenee, se ei kuitenkaan takaa, että jakauman muoto lähestyisi normaalia. Toiseksi, reliabiliteetti (tietojen laatu) olisi pikemminkin sidottava mittaukseen kuin otoskoon määrittelyyn. Suuri otoskoko, jossa on paljon mittausvirheitä, jopa satunnaisvirheitä, paisuttaisi parametristen testien virhetermiä.
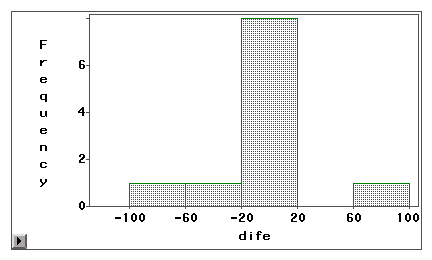
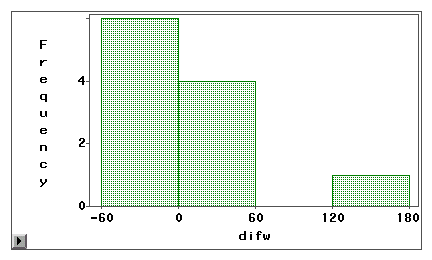
Varsi- ja lehtikuvion tai histogrammin avulla voidaan visuaalisesti tutkia, johtuuko mittausvirhe systemaattisesta harhasta vai satunnaisvaihtelusta. Seuraavassa esimerkissä kahta Internetin käyttötapaa (Web-selailu ja sähköposti) mitataan sekä itse ilmoitetulla kyselyllä että lokikirjalla. Erotuspisteet (mittaus 1 – mittaus 2) on piirretty seuraaviin histogrammeihin.
Ensimmäisestä kuvaajasta käy ilmi, että useimmat erotuspisteet keskittyvät nollan ympärille. Ali- ja yliraportointi näkyy molempien päiden lähellä, mikä viittaa siihen, että mittausvirhe on pikemminkin satunnaisvirhe kuin systemaattinen harha.
Toisesta kuvaajasta käy selvästi ilmi, että mittausvirheiden määrä on suuri, koska hyvin harvat eroarvot ovat nollan ympärillä. Lisäksi jakauma on negatiivisesti vino, ja tällöin virhe on harhaa eikä varianssia.
Miten luotettava muistimme on?
Schacter (1999) varoitti, että ihmisen muisti on erehtyväinen. Muistissamme on seitsemän virhettä:
- Ohimenevyys: Tiedon saatavuuden väheneminen ajan myötä.
- Hajamielisyys: Tarkkaamaton tai pinnallinen prosessointi, joka edistää heikkoa muistia.
- Estäminen: Muistiin tallennetun tiedon tilapäinen saavuttamattomuus.
- Virheellinen attribuutio Muistijäljen tai ajatuksen liittäminen väärään lähteeseen.
- Suggestiivisuus: Muistot, jotka istutetaan johdattelevien kysymysten tai odotusten seurauksena.
- Ennakkoluuloisuus: Takautuvat vääristymät ja tiedostamattomat vaikutteet, jotka liittyvät nykyisiin tietoihin ja uskomuksiin.
- Pysyvyys: Patologiset muistot – tiedot tai tapahtumat, joita emme voi unohtaa, vaikka toivoisimme voivamme.
 |
”Minulla ei ole enää muistoja näistä. En muista allekirjoittaneeni Whitewaterin asiakirjaa. En muista, miksi asiakirja katosi, mutta ilmestyi myöhemmin. En muista mitään.” ”Muistan laskeutuneeni (Bosniaan) tarkka-ampujien tulituksessa. Lentokentällä piti olla jonkinlainen tervetuloseremonia, mutta sen sijaan me vain juoksimme pää alaspäin päästaksemme ajoneuvoihin päästaksemme tukikohtaamme.” Tutkinnan aikana, joka koski salaisten tietojen lähettämistä henkilökohtaisen sähköpostipalvelimen kautta, Clinton kertoi FBI:lle, ettei hän 39 kertaa ”muistanut” tai ”muistanut” mitään. Varoitus: Uusi tietokonevirus nimeltä ”Clinton” on löydetty. Jos tietokone on saanut tartunnan, se avaa usein tämän viestin ”muisti loppu”, vaikka siinä olisi riittävästi RAM-muistia. |
| K: ”Jos Vernon Jordon on kertonut meille, että teillä on poikkeuksellinen muisti,yksi parhaista muistista, jonka hän on koskaan nähnyt poliitikolla, haluaisitteko kiistää tämän?”.”
A: ”Minulla on hyvä muisti…Mutta en muista, olinko yksin Monica Lewinskyn kanssa vai en. Howcould I keep track of so many women in my life?” Q: Miksi Clinton suositteli Lewinskyä Revlonin töihin? A: Hän tiesi, että nainen olisi hyvä keksimään asioita. |
 |
On tärkeää huomata, että joskus muistimme luotettavuus on sidoksissa lopputuloksen toivottavuuteen. Kun esimerkiksi lääketieteen tutkija yrittää kerätä asiaankuuluvia tietoja äideiltä, joiden vauvat ovat terveitä, ja äideiltä, joiden lapset ovat epämuodostuneita, jälkimmäisten tiedot ovat yleensä tarkempia kuin ensin mainittujen. Tämä johtuu siitä, että epämuodostuneiden vauvojen äidit ovat käyneet huolellisesti läpi kaikki raskauden aikana ilmenneet sairaudet, kaikki käytetyt lääkkeet ja kaikki tragediaan suoraan tai etäisesti liittyvät yksityiskohdat yrittäessään löytää selityksen. Sitä vastoin terveiden vauvojen äidit eivät kiinnitä paljon huomiota edellisiin tietoihin (Aschengrau & SeageIII, 2008). GPA:n paisuttelu on toinen esimerkki siitä, miten haluttomuusvaikuttaa muistin tarkkuuteen ja tietojen eheyteen. Joissakin tilanteissa GPA:n paisuttamisessa on sukupuolten välisiä eroja. Caskie etal. suorittamassa tutkimuksessa. (2014) tekemässä tutkimuksessa havaittiin, että alemman GPA-arvosanan saaneiden yliopisto-opiskelijoiden ryhmässä naiset ilmoittivat todellista korkeamman GPA-arvosanan todennäköisemmin kuin miehet.
Muistivirheiden ongelman torjumiseksi jotkut tutkijat ehdottivat, että kerättäisiin tietoa, joka liittyisi osallistujan hetkelliseen ajatukseen tai tunteeseen, sen sijaan, että pyydettäisiin häntä muistelemaan kaukaisia tapahtumia (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Seuraavat esimerkit ovat vuoden 2018 Programme forInternational Student Assessment -kyselytutkimuskohteita: ”Kohdeltiinko sinua eilen koko päivän kunnioittavasti?” ”Hymyilitkö tai nauroitko paljon eilen?” ”Opitko tai teitkö eilen jotain mielenkiintoista?” (Taloudellisen yhteistyön ja kehityksen järjestö, 2017). Vastaus riippuu kuitenkin siitä, mitä osallistujalle tapahtui kyseisellä hetkellä, mikä ei välttämättä ole tyypillistä. Erityisesti, vaikka vastaaja ei hymyillyt tai nauranut paljon eilen, se ei välttämättä tarkoita, että vastaaja on aina onneton.
Mitä tehdään?
Jotkut tutkijat hylkäävät itse raportoitujen tietojen käytön niiden väitetyn heikon laadun vuoksi. Kun esimerkiksi eräs tutkijaryhmä tutki, johtaako korkea uskonnollisuus siihen, että Yhdysvalloissa noudatetaan vähemmän shelter-in-placed-ohjeita COVID19-pandemian aikana, he käyttivät 10 000 asukasta kohti laskettua seurakuntien lukumäärää alueen uskonnollisuutta kuvaavana mittarina sen sijaan, että he olisivat käyttäneet itseraportoitua uskonnollisuutta, jolla on taipumus heijastaa sosiaalista suotavuutta (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Chan (2009) kuitenkin väitti, että itse raportoitujen tietojen niin sanottu huono laatu ei ole muuta kuin urbaani legenda. Sosiaalisen suotavuuden ohjaamina vastaajat saattavat antaa tutkijoille epätarkkoja tietoja joissakin tilanteissa, mutta näin ei tapahdu koko ajan. On esimerkiksi epätodennäköistä, että vastaajat valehtelisivat demografisista tiedoistaan, kuten sukupuolesta ja etnisestä alkuperästä. Toiseksi, vaikka on totta, että vastaajilla on taipumus väärentää vastauksiaan kokeellisissa tutkimuksissa, tämä ongelma ei ole yhtä vakava kenttätutkimuksissa ja naturalistisissa ympäristöissä käytetyissä mittauksissa. Lisäksi erilaisista psykologisista konstruktioista on olemassa lukuisia vakiintuneita itseraportoituja mittareita, jotka ovat saaneet näyttöä konstruktion validiteetista sekä konvergentin että diskriminantin validoinnin avulla. Esimerkiksi Big-five-persoonallisuuspiirteet, proaktiivinen persoonallisuus, affektiivisuus, itsetehokkuus, tavoiteorientaatiot, koettu organisaation tuki ja monet muut.Epidemiologian alalla Khoury, James ja Erickson (1994) väittivät, että recall biasin vaikutus on yliarvioitu. Heidän päätelmäänsä ei ehkä kuitenkaan voida soveltaa hyvin muille aloille, kuten kasvatustieteeseen ja psykologiaan.Tietojen epätarkkuuden uhasta huolimatta tutkijan on mahdotonta seurata jokaista koehenkilöä videokameran kanssa ja nauhoittaa kaikki heidän tekemisensä. Tutkija voi kuitenkin käyttää osajoukkoa koehenkilöistä saadakseen havainnoituja tietoja, kuten käyttöpäiväkirjaa tai päivittäistä verkkokäyttäytymispäiväkirjaa. Tuloksia verrataan sitten kaikkien koehenkilöiden itse ilmoittamiin tietoihin mittausvirheen arvioimiseksi.Esimerkiksi
- Kun tutkimusloki on tutkijan käytettävissä, hän voi pyytää koehenkilöitä ilmoittamaan, kuinka usein he käyttävät verkkopalvelinta.Koehenkilöille ei pitäisi kertoa, että verkkopalvelimen ylläpitäjä on tallentanut heidän Internet-toimintansa, koska tämä voi vaikuttaa osallistujien käyttäytymiseen.
- Tutkija voi pyytää osajoukkoa käyttäjistä pitämään päiväkirjaa Internet-toiminnoistaan kuukauden ajan. Tämän jälkeen samoja käyttäjiä pyydetään täyttämään kysely heidän internetin käyttöään koskien.
Joku voi väittää, että lokikirjaan perustuva lähestymistapa on liian vaativa. Monissa tieteellisissä tutkimuksissa koehenkilöiltä pyydetäänkin paljon enemmän. Kun tutkijat esimerkiksi tutkivat, miten syvä uni pitkien avaruusmatkojen aikana vaikuttaisi ihmisten terveyteen, osallistujia pyydettiin makaamaan sängyssä kuukauden ajan. Tutkimuksessa, joka koski sitä, miten suljettu ympäristö vaikuttaa ihmisen psykologiaan avaruusmatkojen aikana, koehenkilöt suljettiin huoneeseen yksitellen kuukaudeksi. Tieteellisten totuuksien etsiminen on kallista.
Kun eri tietolähteitä on kerätty, voidaan analysoida lokitietojen ja itse raportoitujen tietojen välistä ristiriitaa tietojen luotettavuuden arvioimiseksi. Ensisilmäyksellä tämä lähestymistapa näyttää test-retestluotettavuudelta, mutta sitä se ei ole. Ensinnäkin testin ja uusintatestin luotettavuudessa kahdessa tai useammassa tilanteessa käytetyn mittarin pitäisi olla sama. Toiseksi, kun testi-uusintaluotettavuus on alhainen, virheiden lähde on laitteen sisällä. Kun virhelähde on kuitenkin mittarin ulkopuolinen, kuten inhimilliset virheet, arvioijien välinen luotettavuus on tarkoituksenmukaisempi.
Yllä ehdotettu menettely voidaan käsitteellistää tietojen välisen luotettavuuden mittaamiseksi, joka muistuttaa arvioijien välisen luotettavuuden ja toistettujen mittausten mittaamista. On olemassa neljä tapaa arvioida arvioijien välistä luotettavuutta, nimittäin Kappa-kerroin, epäjohdonmukaisuusindeksi, toistettujen mittausten ANOVA ja regressioanalyysi. Seuraavassa luvussa kuvataan, miten näitä arvioijien välisen luotettavuuden mittauksia voidaan käyttää tietojen välisen luotettavuuden mittauksina.
Kappa-kerroin
Psykologisessa ja kasvatustieteellisessä tutkimuksessa ei ole epätavallista käyttää kahta tai useampaa arvioijaa teemamittausprosessissa, kun arviointiin liittyy subjektiivisia arvioita (esim. esseiden arvostelu). Arvioijien välistä luotettavuutta, jota mitataan Kappa-kertoimella, käytetään osoittamaan tietojen luotettavuutta.Esimerkiksi kaksi tai useampi arvioija arvioi osallistujien suoritukset ”mestariksi” tai ”ei-mestariksi” (1 tai 0). Näin ollen tämä mittari lasketaan yleensä kategoristen tietojen analyysimenetelmissä, kuten PROC FREQ SAS:ssa, ”sopimuksen mittaaminen” SPSS:ssä tai online-Kappa-laskurilla (Lowry, 2016). Alla oleva kuva on kuvakaappausVassarstatsin verkkolaskurista.
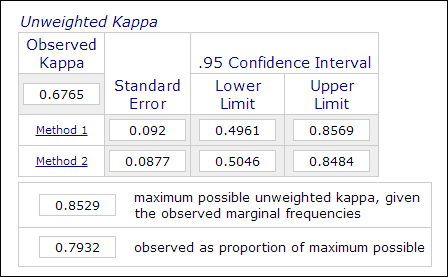
On tärkeää huomata, että vaikka 60 prosenttia kahdesta aineistosta olisikin yhteneviä, se ei tarkoita, että mittaukset ovat luotettavia.koska lopputulos on dikotominen, kahden mittauksen yhtenevyyden mahdollisuus on 50 prosenttia. Kappa-kerroin ottaa tämän huomioon ja vaatii korkeampaa vastaavuusastetta yhdenmukaisuuden saavuttamiseksi.
Verkkopohjaisen opetuksen yhteydessä jokainen itse ilmoitetun verkkosivuston käytön luokka voidaan koodata uudelleen binäärimuuttujaksi. Esimerkiksi, kun kysymys yksi on ”kuinka usein käytät telnetiä”, mahdolliset kategoriset vastaukset ovat ”a: päivittäin”, ”b: kolmesta viiteen kertaa viikossa”, ”c: kolme-viisi kertaa kuukaudessa”, ”d: harvoin” ja ”e: ei koskaan”. Tässä tapauksessa viisi luokkaa voidaan koodata viideksi muuttujaksi: Q1A, Q1B, Q1C, Q1D ja Q1E. Tämän jälkeen kaikki nämä binäärimuuttujat voidaan liittää R X 2 -taulukkoon, joka on esitetty seuraavassa taulukossa.Tämän tietorakenteen avulla vastaukset voidaan koodata arvoilla ”1” tai ”0”, ja siten luokittelusopimuksen mittaaminen on mahdollista. Yhteisymmärrys voidaan laskea Kappa-kertoimen avulla, ja näin voidaan arvioida tietojen luotettavuutta.
Henkilöt Pöytäkirjan tiedot Self-report data Subject 1 1 1 Subject 2 0 0 Subjekti 3 1 0 Subject 4 0 1 Index of Inconsistency
Toinen tapa laskea edellä mainitut kategoriset tiedot on Index ofInconsistency (IOI). Koska edellä olevassa esimerkissä on kaksi mittausta (lokitiedot ja itse ilmoitetut tiedot) ja viisi vastausvaihtoehtoa, muodostetaan 4 X 4 -taulukko. Ensimmäinen vaihe IOI:n laskemiseksi on jakaa RXC-taulukko useisiin 2X2-alataulukoihin. Esimerkiksi viimeistä vaihtoehtoa ”ei koskaan” käsitellään yhtenä luokkana ja kaikki loput luokitellaan toiseen luokkaan ”ei koskaan”, kuten seuraavassa taulukossa esitetään.
Self-raportoidut tiedot Log ei koskaan ei koskaan yhteensä ei koskaan a .
b a+b Ei koskaan c d c+d Yhteensä a+c b+d n=Summa(a-d) IOI:n prosenttiosuus lasketaan seuraavalla kaavalla:
IOI% = 100*(b+c)/ jossa p = (a+c)/n
Kun IOI on laskettu kullekin 2X2-osa-taulukolle, kaikkien indeksien keskiarvoa käytetään toimenpiteen epäjohdonmukaisuuden indikaattorina. Kriteeri, jolla arvioidaan, ovatko tiedot johdonmukaisia, on seuraava:
- IOI alle 20 on matala varianssi
- IOI välillä 20-50 on kohtalainen varianssi
- IOI yli 50 on suuri varianssi
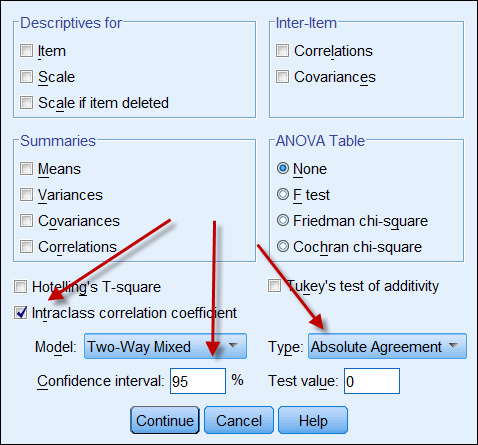
Tietojen luotettavuus ilmaistaan tällä yhtälöllä: Jos molemmat tietolähteet tuottavat jatkuvia tietoja, voidaan laskea luokan sisäinen korrelaatiokerroin, joka osoittaa tietojen luotettavuuden. Seuraavassa on kuvakaappaus SPSS:n ICC-vaihtoehdoista. Kohdassa Typethere on kaksi vaihtoehtoa: ”johdonmukaisuus” ja ”absoluuttinen yksimielisyys”. Jos valitaan ”johdonmukaisuus”, vaikka toinen numerosarja olisi johdonmukaisuuskorkea (esim. 9, 8, 9, 8, 8, 7…) ja toinen matala (esim. 4,3, 4, 4, 3, 2…), niiden voimakas korrelaatio antaa virheellisen vaikutelman siitä, että tiedot ovat yhdenmukaisia keskenään. Näin ollen on suositeltavaa valita ”absoluuttinen yhdenmukaisuus”.
toistetut mittaukset
Aineistojen välisen luotettavuuden mittaaminenvoidaan käsitteellistää ja toteuttaa myös toistettujen mittaustenANOVA:na. Toistettujen mittausten ANOVA:ssa samoille koehenkilöille tehdään mittauksia useita kertoja, kuten esitesti, välikoe ja jälkitesti. Tässä yhteydessä koehenkilöitä mitataan toistuvasti myös verkkokäyttäjälokin, lokikirjan ja itse raportoidun kyselyn avulla. Seuraavassa on SAS-koodi toistettujen mittausten ANOVA:lle:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
Yllä mainitussa ohjelmassa yhdeksän vapaaehtoisen käymien verkkosivustojen määrä kirjataan verkkokäyttäjälokiin, henkilökohtaiseen lokikirjaan ja itseraportoituun kyselyyn. Käyttäjiä käsitellään koehenkilöiden välisenä tekijänä, kun taas kolmea toimenpidettä pidetään toimenpiteiden välisenä tekijänä. Seuraavassa on tiivistetty tuotos:
Variaation lähde DF Keskiarvon neliö Väli-koehenkilö (käyttäjä) 8 10442.50 Väli-mitta (aika) 2 488.93 Jäännös 16 454.80 Yllä olevien tietojen perusteella luotettavuuskerroin voidaan laskea tällä kaavalla (Fisher, 1946; Horst, 1949):
r = MSbetween-measure – MSresidual —————————————————-.———- MSbetween-measure + (dfbetween-people X MSresidual) Pistetään luku kaavaan:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) Luotettavuusluku on noin 0,0008, mikä on erittäin alhainen. Siksi voimme mennä kotiin ja unohtaa tiedot. Onneksi kyseessä on vain hypoteettinen aineisto. Mutta entä jos se onkin todellinen aineisto? On oltava tarpeeksi kova luopumaan huonosta aineistosta sen sijaan, että julkaisee täysin epäluotettavia tuloksia.
Korrelaatio- ja regressioanalyysi
Korrelaatioanalyysi, jossa käytetään Pearsonin tuotehetkikerrointa, on hyvin yksinkertainen ja erityisen hyödyllinen silloin, kun kahden mittaustuloksen asteikot eivät ole samat. Esimerkiksi verkkopalvelimen loki voi seurata sivujen lukumäärää, kun taas itse raportoidut tiedot ovatLikert-asteikollisia (esim. Kuinka usein selaatte Internetiä). 5=erittäin usein,4=usein, 3=joskus, 2=harvoin, 5=ei koskaan). Tässä tapauksessa itse ilmoitettuja pistemääriä voidaan käyttää ennusteena, jota voidaan regressoida sivujen käytön suhteen.
Vastaava lähestymistapa on regressioanalyysi, jossa yhtä pistemäärää (esim. kyselytutkimuksen tiedot) käsitellään ennustajana, kun taas toista pistemäärää (esim. käyttäjän päivittäinen loki) pidetään riippuvaisena muuttujana. Jos käytetään useampaa kuin kahta mittaria, voidaan soveltaa moninkertaista regressiomallia, jolloin tarkemman tuloksen antavaa mittaria (esim. Web-käyttäjien verkkokäyttöloki) pidetään riippuvaisena muuttujana ja kaikkia muita mittareita (esim. käyttäjien päivittäinen verkkokäyttöloki, kyselytutkimuksen tiedot) pidetään riippumattomina muuttujina.
Viite
- Aschengrau, A., & Seage III, G. (2008). Epidemiologian perusteet kansanterveystyössä. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Toim.) Mittaaminen yhteiskuntatieteissä: Theories and strategies. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Itseraportoidun college GPA:n tarkkuus: Sukupuolesta johtuvat erot saavutustason ja akateemisen itsetehokkuuden mukaan. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Miksi siis kysyä minulta? Ovatko itseraportointitiedot todella niin huonoja? Teoksessa Charles E. Lance ja Robert J. Vandenberg (toim.), Tilastolliset ja metodologiset myytit ja urbaanilegendat: Doctrine,verity and fable in the organizational and social sciences (pp309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Kvasikokeilu: Design and analysis issues. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Kokemusnäytteenottomenetelmän pätevyys ja luotettavuus. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). Psykologia tieteenä ja taiteena. New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, August 10). Uskonto ja reaktiivisuus COVID-19mitigation-ohjeisiin. Amerikkalainen psykologi. Ennakkojulkaisu verkossa. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). High School and Beyond. Kansallinen pitkittäistutkimus 1980-luvulle, lukiolaisten vastausten laatu kyselylomakkeen kohtiin. (NCES 84-216), Washington, D. C., Yhdysvallat: U.S. Department of Education. Office of Educational Research and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). The incrementalvalidity of average state self-reports over global self-reports ofpersonality. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statistical methods for research workers (10. painos). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). Kuinka moniAmerikkalainen osallistuu jumalanpalvelukseen viikoittain? Vaihtoehtoinen lähestymistapa mittaamiseen? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 August). Antropometristen mittojen prosenttijakaumien vertailu kolmen aineiston välillä. Esitelmä Annual Joint Statistical Meeting -tapahtumassa, Baltimore, MD.
- Horst, P. (1949). A Generalized expression for the reliability of measures. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). On theuse of affected controls to address recall bias in case-control studiesof birth defects. Teratology, 49, 273-281.
- Loftus, E. (2016, April). Muistin fiktio. Paper presented at the Western Psychological Association Convention. Long Beach, CA.
- Lowry, R. (2016). Kappa yhteneväisyyden mittana kategorisessa lajittelussa. Haettu osoitteesta http://vassarstats.net/kappa.html
- Organisation for Economic Cooperation and Development. (2017). Hyvinvointikysely PISA 2018 -tutkimusta varten. Pariisi: Author. Haettu osoitteesta https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). Muistin seitsemän syntiä: Insights from psychology and cognitive neuroscience. American Psychology, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Mittausvirhetutkimukset kansallisessa koulutustilastokeskuksessa. Washington D. C: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Kaikki valehtelevat: Big data, new data, and what the Internet can tell us about who we really are. New York, NY: Dey Street Books.
 Siirry päävalikkoon
Siirry päävalikkoon Muut kurssitHakukone
|

Ota yhteyttä
|