Mietitkö, mitä Postgresql-skeemat ovat ja miksi ne ovat tärkeitä ja miten voit käyttää skeemoja tehdessäsi tietokantatoteutuksistasi vankempia ja ylläpidettävämpiä? Tässä artikkelissa esitellään skeemojen perusteet Postgresql:ssä ja näytetään, miten niitä luodaan muutamien perusesimerkkien avulla. Tulevissa artikkeleissa syvennytään esimerkkeihin siitä, miten skeemoja voidaan turvata ja käyttää todellisissa sovelluksissa.
Aluksi mahdollisten terminologisten epäselvyyksien selvittämiseksi ymmärretään, että Postgresql-maailmassa termi ”skeema” on ehkä hieman valitettavasti ylikuormitettu. Laajemmassa relaatiotietokannan hallintajärjestelmien (RDBMS) yhteydessä termi ”skeema” voidaan ymmärtää viittaamaan tietokannan yleiseen loogiseen tai fyysiseen suunnitteluun eli kaikkien niiden taulujen, sarakkeiden, näkymien ja muiden objektien määrittelyyn, jotka muodostavat tietokannan määritelmän. Tässä laajemmassa yhteydessä skeema saatetaan ilmaista ER-kaaviossa (entity-relationship) tai DDL-lausekkeiden (data definition language) käsikirjoituksessa, jota käytetään sovellustietokannan luomiseen.
Postgresql-maailmassa termi ”skeema” saatetaan ymmärtää paremmin ”nimiavaruudeksi”. Itse asiassa Postgresql-järjestelmän taulukoissa skeemat tallennetaan taulukon sarakkeisiin nimeltä ”nimiavaruus”, mikä on IMHO tarkempi terminologia. Käytännössä aina kun näen ”skeeman” Postgresql:n yhteydessä, tulkitsen sen hiljaa uudelleen sanomalla ”nimiavaruus”.
Mutta saatat kysyä: ”Mikä on nimiavaruus?”. Yleisesti ottaen nimiavaruus on melko joustava keino organisoida ja tunnistaa tietoa nimellä. Kuvitellaan esimerkiksi kaksi naapuritaloutta, Smithit, Alice ja Bob, ja Jonesit, Bob ja Cathy (vrt. kuva 1). Jos käyttäisimme vain etunimiä, saattaisi tulla sekavaksi, kumpaa henkilöä tarkoitamme puhuessamme Bobista. Mutta lisäämällä sukunimen, Smithin tai Jonesin, tunnistamme yksiselitteisesti, kumpaa henkilöä tarkoitamme.
Usein nimiavaruudet järjestetään sisäkkäiseen hierarkiaan. Tämä mahdollistaa valtavien tietomäärien tehokkaan luokittelun hyvin hienojakoiseen rakenteeseen, kuten esimerkiksi internetin verkkotunnusjärjestelmässä. Ylimmällä tasolla ”.com”, ”.net”, ”.org”, ”.edu” jne. määrittelevät laajat nimiavaruudet, joiden sisällä rekisteröidään nimiä tietyille yksiköille, joten esimerkiksi ”severalnines.com” ja ”postgresql.org” on määritelty yksiselitteisesti. Molempien alla on kuitenkin useita yhteisiä aladomeeneja, kuten esimerkiksi ”www”, ”mail” ja ”ftp”, jotka yksinään ovat päällekkäisiä, mutta kunkin nimiavaruuden sisällä ovat ainutlaatuisia.
Postgresql-skeemat palvelevat tätä samaa järjestämis- ja tunnistamistarkoitusta, mutta toisin kuin toisessa edellä mainitussa esimerkissä, Postgresql-skeemoja ei voi sijoittaa hierarkiassa. Vaikka tietokanta voi sisältää useita skeemoja, niitä on aina vain yksi taso, joten tietokannan sisällä skeemojen nimien on oltava yksilöllisiä. Lisäksi jokaisen tietokannan on sisällettävä vähintään yksi skeema. Aina kun uusi tietokanta luodaan, luodaan oletusskeema nimeltä ”public”. Skeeman sisältöön kuuluvat kaikki muut tietokantaobjektit, kuten taulukot, näkymät, tallennetut proseduurit, käynnistimet jne. Havainnollistamista varten katso kuvaa 2, joka esittää matrjoska-nuken kaltaisen pesäkkeen, joka osoittaa, miten skeemat sopivat Postgresql-tietokannan rakenteeseen.
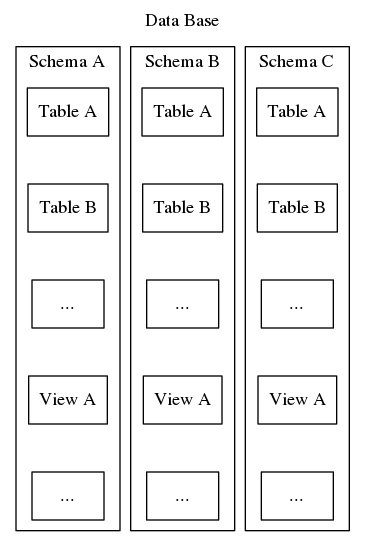
Sen lisäksi, että skeemat yksinkertaisesti järjestävät tietokantaobjekteja loogisiin ryhmiin, jotta ne olisivat helpommin hallittavissa, skeemojen käytännöllisenä tarkoituksena on välttää nimikolareita. Eräässä toimintamallissa kullekin tietokantakäyttäjälle määritellään oma skeema, jotta saadaan aikaan jonkinasteinen eristys, tila, jossa käyttäjät voivat määritellä omat taulunsa ja näkymänsä häiritsemättä toisiaan. Toinen lähestymistapa on asentaa kolmannen osapuolen työkaluja tai tietokannan laajennuksia yksittäisiin skeemoihin, jotta kaikki toisiinsa liittyvät komponentit pysyvät loogisesti yhdessä. Tämän sarjan myöhemmässä artikkelissa esitellään yksityiskohtaisesti uudenlainen lähestymistapa vankkaan sovellussuunnitteluun, jossa käytetään skeemoja keinona rajoittaa tietokannan fyysisen suunnittelun paljastumista ja sen sijaan esitellään käyttöliittymä, joka ratkaisee synteettiset avaimet ja helpottaa pitkäaikaista ylläpitoa ja konfiguraatioiden hallintaa järjestelmätarpeiden kehittyessä.
Tehdään vähän koodia!
Yksinkertaisin komento skeeman luomiseksi tietokantaan on
CREATE SCHEMA hollywood;Tämä komento vaatii create-oikeudet tietokannassa, ja äskettäin luodun skeeman ”hollywood” omistaa komennon kutsuva käyttäjä. Monimutkaisempi kutsu voi sisältää valinnaisia elementtejä, jotka määrittelevät eri omistajan, ja se voi jopa sisältää DDL-lausekkeita, joilla tietokantaobjekteja instanttisoidaan skeeman sisällä, kaikki yhdessä komennossa!
Yleinen muoto on
CREATE SCHEMA schemaname ], jossa ”username” on se, kuka omistaa skeeman, ja ”schema_elementti” voi olla jokin tietyistä DDL-komennoista (tarkemmat yksityiskohdat löytyvät Postgresqlin dokumentaatiosta). AUTHORIZATION-vaihtoehdon käyttäminen vaatii superkäyttäjän oikeudet.
Siten esimerkiksi luodaksesi skeeman nimeltä ”hollywood”, joka sisältää taulun nimeltä ”films” ja näkymän nimeltä ”winners”, voit tehdä yhdellä komennolla
CREATE SCHEMA hollywood CREATE TABLE films (title text, release date, awards text) CREATE VIEW winners AS SELECT title, release FROM films WHERE awards IS NOT NULL;Lisätietokantaobjekteja voidaan myöhemmin luoda suoraan, esimerkiksi lisätaulu lisättäisiin skeemaan komennolla
CREATE TABLE hollywood.actors (name text, dob date, gender text);Huomaa yllä olevassa esimerkissä taulun nimen etuliite skeeman nimen kanssa. Tämä on tarpeen, koska oletusarvoisesti, eli ilman nimenomaista skeemamäärittelyä, uudet tietokantaobjektit luodaan minkä tahansa nykyisen skeeman sisällä, jota käsittelemme seuraavaksi.
Muistakaa, että edellä olevassa ensimmäisessä nimiavaruusesimerkissä meillä oli kaksi henkilöä nimeltä Bob, ja kuvailimme, miten heidät erotetaan toisistaan tai erotetaan toisistaan sisällyttämällä sukunimi. Mutta jokaisessa Smithin ja Jonesin taloudessa erikseen kukin perhe ymmärtää ”Bobin” viittaavan siihen, joka kuuluu kyseiseen talouteen. Niinpä esimerkiksi kunkin kotitalouden kontekstissa Alicen ei tarvitse puhutella miestään Bob Jonesina eikä Cathyn tarvitse viitata mieheensä Bob Smithinä: he voivat kumpikin vain sanoa ”Bob”.
Postgresql:n nykyinen skeema on ikään kuin kotitalous yllä olevassa esimerkissä. Nykyisessä skeemassa oleviin objekteihin voidaan viitata kvalifioimattomasti, mutta muissa skeemoissa oleviin samannimisiin objekteihin viittaaminen edellyttää nimen kvalifiointia asettamalla skeeman nimi etuliitteeksi kuten edellä.
Nykyinen skeema johdetaan määritysparametrista ”search_path”. Tämä parametri tallentaa pilkulla erotetun luettelon skeeman nimistä, ja sitä voidaan tarkastella komennolla
SHOW search_path;tai asettaa uusi arvo komennolla
SET search_path TO schema ;Luettelon ensimmäinen skeemanimi on ”nykyinen skeema”, ja siihen luodaan uusia objekteja, jos se on määritetty ilman skeemanimen karsintaa.
Skeemanimien pilkulla erotetun luettelon avulla määritetään myös hakujärjestys, jonka avulla järjestelmä etsii olemassa olevat, karsimattomat nimetyt objektit. Jos esimerkiksi palataan takaisin Smithin ja Jonesin naapurustoon, pakettilähetys, joka on osoitettu vain ”Bobille”, edellyttäisi käyntiä jokaisessa taloudessa, kunnes ensimmäinen ”Bob”-niminen asukas löydetään. Huomaa, että tämä ei välttämättä ole tarkoitettu vastaanottaja. Sama logiikka pätee Postgresql:ään. Järjestelmä etsii tauluja, näkymiä ja muita objekteja skeemojen sisältä hakupolun mukaisessa järjestyksessä, ja sitten käytetään ensimmäistä löydettyä nimeä vastaavaa objektia. Kaavamääriteltyjä nimettyjä objekteja käytetään suoraan ilman viittausta search_pathiin.
Vakiokokoonpanossa search_path-konfiguraatiomuuttujan kysely paljastaa tämän arvon
SHOW search_path; Search_path-------------- "$user", publicJärjestelmä tulkitsee edellä esitetyn ensimmäisen arvon senhetkiseksi kirjautuneeksi käyttäjän nimeksi, ja se sopii aiemmin mainittuun käyttötapaukseen, jossa kullekin käyttäjälle on varattu käyttäjälle oma nimetty kaavio työtilaa varten erillään toisista käyttäjistä. Jos tällaista käyttäjälle nimettyä skeemaa ei ole luotu, kyseinen merkintä jätetään huomiotta ja ”julkisesta” skeemasta tulee nykyinen skeema, johon uusia objekteja luodaan.
Takaisin aiempaan esimerkkiin ”hollywood.actors”-taulun luomisesta: jos emme olisi määritelleet taulun nimeä skeeman nimellä, taulukko olisi luotu julkiseen skeemaan. Jos ennakoimme kaikkien objektien luomista tietyssä skeemassa, saattaisi olla kätevää asettaa search_path-muuttuja esimerkiksi seuraavasti:
SET search_path TO hollywood,public;Tietokantaobjektien luomisessa tai käyttämisessä on helpompaa käyttää lyhennettä, jossa tietokantaobjekteja luodaan kirjoittamalla määrittelemättömiä nimiä.
On olemassa myös järjestelmätietofunktio, joka palauttaa nykyisen skeeman kyselyllä
select current_schema();Kirjoitusasun lihavoidessa skeeman omistaja voi muuttaa nimeä, jos käyttäjällä on myös tietokannan luontioikeudet,
ALTER SCHEMA old_name RENAME TO new_name;Viimeiseksi, skeeman poistaminen tietokannasta, on olemassa drop-komento
DROP SCHEMA schema_name;DROP-komento epäonnistuu, jos skeema sisältää objekteja, joten ne on poistettava ensin, tai voit valinnaisesti poistaa rekursiivisesti skeeman koko sisällön CASCADE-valinnalla
DROP SCHEMA schema_name CASCADE;Näillä perusteilla pääset alkuun skeemojen ymmärtämisessä!