Menetelmä 1, huono: ORDER BY NEWID()
Helppo kirjoittaa, mutta se toimii kuin kuuma, kuuma roska, koska se skannaa koko klusteroidun indeksin ja laskee NEWID() jokaiselle riville:
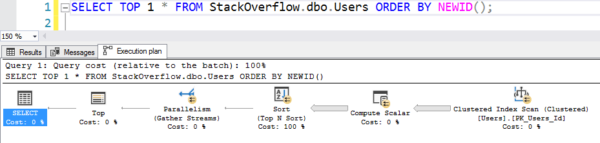
Suunnitelma, jossa on skannaus
Se kesti 6 sekuntia koneellani, kun se kulki rinnakkain useiden säikeiden välillä ja käytti kymmeniä sekunteja CPU:n aikaa kaikkeen tuohon tietokoneen laskutoimitukseen ja lajitteluun. (Eikä Users-taulukko ole edes 1GB.)
Metodi 2, parempi mutta outo: TABLESAMPLE
Tämä tuli markkinoille vuonna 2005, ja siinä on paljon ongelmia. Se tavallaan valitsee satunnaisen sivun ja palauttaa sitten joukon rivejä kyseiseltä sivulta. Ensimmäinen rivi on tavallaan satunnainen, mutta loput eivät.
Transakt-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
Suunnitelma näyttää siltä, että se tekee taulukon skannauksen, mutta se tekee vain 7 loogista lukua:
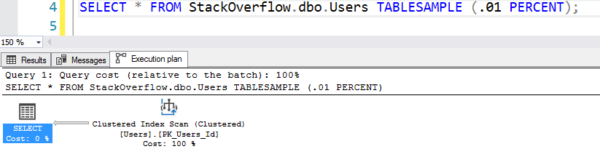
Suunnitelma väärennetyllä skannauksella
Mutta tässä ovat tulokset – näet, että se hyppää satunnaiselle 8K-sivulle ja alkaa sitten lukea rivejä järjestyksessä. Ne eivät ole oikeasti satunnaisia rivejä.
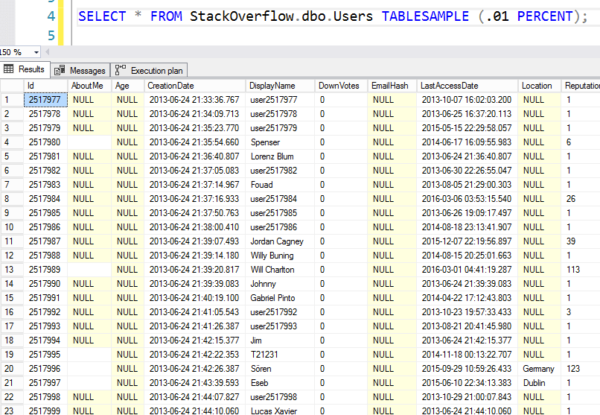
Satunnaisia kuin mafian lottonumerot
Voit sen sijaan käyttää ROWS-näytteenottokokoa, mutta se antaa melko outoja tuloksia. Esimerkiksi Stack Overflow Users -taulukossa, kun sanoin TABLESAMPLE (50 ROWS), sain itse asiassa takaisin 75 riviä. Tämä johtuu siitä, että SQL Server muuntaa rivikoon sen sijaan prosentuaaliseksi.
Metodi 3, paras, mutta vaatii koodia: Satunnainen ensisijainen avain
Saa taulukon ylin ID-kenttä, luo satunnaisluku ja etsi tämä ID. Tässä lajittelemme ID:n mukaan, koska haluamme löytää ylimmän tietueen, joka on todella olemassa (kun taas satunnaisluku on saatettu poistaa.) Melko nopea, mutta sopii vain yhdelle satunnaiselle riville. Jos haluaisit 10 riviä, sinun pitäisi kutsua tällaista koodia 10 kertaa (tai luoda 10 satunnaislukua ja käyttää IN-lauseketta.)
Toteutussuunnitelma näyttää klusteroidun indeksiskannauksen, mutta se nappaa vain yhden rivin – puhumme vain 6 loogisesta lukukerrasta kaikelle, mitä näet tässä, ja se päättyy lähes välittömästi:

Suunnitelma, joka voi
Tässä on yksi hankaluus kohdallaan: jos Id:ssä on negatiivisia numeroita, se ei toimi odotetulla tavalla. (Sanotaan esimerkiksi, että aloitat Ident-kentän -1:stä ja astut -1:stä aina alaspäin, kuten moraalini.)
Menetelmä 4, OFFSET-FETCH (2012+)
Daniel Hutmacher lisäsi tämän kommenteissa:
Ja sanoi: ”Mutta se toimii kunnolla vain klusteroidun indeksin kanssa. Arvelen sen johtuvan siitä, että se etsii (@rows) rivit kasasta sen sijaan, että se tekisi indeksin haun.”
Bonus Track #1: Watch Us Discussing This
Oletko koskaan miettinyt, millaista on olla yrityksemme keskusteluhuoneessa? Tästä 10 minuutin Slack-keskustelusta saat aika hyvän käsityksen:
Spoilerihälytys: ei ollut. Otin vain kuvakaappauksia.
Bonus Track #2: Mitch Wheat Digs Deeper
Tahdotko syvällisen analyysin useiden eri tekniikoiden satunnaisuudesta? Mitch Wheat sukeltaa todella syvälle graafien kera!