Yllä oleva kuva on ehkä antanut sinulle riittävän käsityksen siitä, mistä tässä viestissä on kyse.
Tämä viesti käsittelee joitain tärkeitä fuzzy(ei täsmälleen yhtäläisiä, mutta lumpsum samoja merkkijonoja, vaikkapa RajKumar & Raj Kumar) merkkijonojen täsmäytysalgoritmeja, jotka sisältävät:
Hamming Distance
Levenstein Distance
Damerau Levenstein Distance
N-Gram-pohjainen merkkijonojen täsmäytys
BK Tree
Bitap-algoritmi
Mutta ensin pitäisi tietää, miksi sumea täsmäytys on tärkeää, kun otetaan huomioon reaalimaailman tilanne. Aina kun käyttäjä saa syöttää mitä tahansa tietoja, asiat voivat mennä todella sotkuisiksi kuten alla olevassa tapauksessa!!!
Let,
- Nimesi on ’Saurav Kumar Agarwal’.
- Olet saanut kirjastokortin (tietysti yksilöllisellä tunnisteella), joka on voimassa jokaiselle perheesi jäsenelle.
- Kävisit kirjastossa antaaksesi joitain kirjoja joka viikko. Mutta tätä varten sinun on ensin tehtävä merkintä kirjaston sisäänkäynnillä olevaan rekisteriin, johon kirjoitat tunnuksesi & nimen.
Nyt kirjastoviranomaiset päättävät analysoida tämän kirjastorekisterin tietoja saadakseen käsityksen kuukausittain käyvistä ainutlaatuisista lukijoista. Nyt tämä voidaan tehdä monista syistä (esim. pitäisikö tontin laajentamiseen ryhtyä vai ei, pitäisikö kirjojen määrää lisätä? jne.).
He suunnittelivat tekevänsä tämän laskemalla (yksilölliset nimet, kirjastotunnus) rekisteröidyt parit kuukaudessa. Joten jos meillä on
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Tämän pitäisi antaa meille 4 uniikkia lukijaa.
So far so good
He arvioivat, että tämä määrä on noin 10k-10.5k, mutta luvut nousivat ~50k:hon sen jälkeen, kun ne oli analysoitu täsmällisellä nimien merkkijonojen täsmäytyksellä.
wooohhh!!
Melko huono arvio, täytyy sanoa !!
Vai jäivätkö heiltä jokin temppu huomaamatta?
Syvällisemmän analyysin jälkeen tuli esiin merkittävä ongelma. Muista nimesi, ’Saurav Agarwal’. He löysivät joitakin merkintöjä, jotka johtavat 5 eri käyttäjään perhekirjastosi ID:ssä:
- Saurav K Aggrawal (huomaa kaksinkertainen ’g’, ’ra-ar’, Kumar muuttuu K:ksi)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Joitakin epäselvyyksiä on olemassa, sillä kirjastoviranomaiset eivät tiedä
- Miten moni käy kirjastossasi perheestäsi? edustavatko nämä viisi nimeä yhtä lukijaa, kahta vai kolmea eri lukijaa. Kutsu sitä valvomattomaksi ongelmaksi, jossa meillä on merkkijono, joka edustaa standardoimattomia nimiä, mutta niiden standardoituja nimiä ei tunneta (esim. Saurav Agarwal: Saurav Kumar Agarwal ei ole tiedossa)
- Pitäisikö kaikki ne yhdistää ’Saurav Kumar Agarwal’-nimeksi? ei voi sanoa, koska SK Agarwal voi olla Shivam Kumar Agarwal (vaikkapa isäsi nimi). Lisäksi ainoa Agarwal voi olla kuka tahansa perheenjäsen.
Kaksi viimeistä tapausta (SK Agarwal & Agarwal) vaatisivat joitain lisätietoja (kuten sukupuoli, syntymäaika, myönnetyt kirjat), jotka syötetään jollekin ML-algoritmille lukijan todellisen nimen määrittämiseksi & pitäisi jättää toistaiseksi. Jos saamme merkkijonon, jossa on hyväksyttävä virheprosentti (esimerkiksi yksi kirjain väärin ), pidämme sitä vastaavana. Tutkitaan siis →
Hammingin etäisyys on ilmeisin kahden samanpituisen merkkijonon välille laskettu etäisyys, joka antaa niiden merkkien lukumäärän, jotka eivät vastaa tiettyä indeksiä. Esimerkiksi: ’Bat’ & ’Bet’ on hamming-etäisyys 1 indeksin 1 kohdalla, ’a’ ei vastaa ’e’
Levenstein Distance/ Edit Distance
Oletan, että tunnet Levensteinin etäisyyden & Rekursio. Jos et, lue tämä. Alla oleva selitys on enemmänkin tiivistetty versio Levensteinin etäisyydestä.
Let ’x’=pituus(Str1) & ’y’=pituus(Str2) koko tämän postauksen ajan.
Levensteinin etäisyys laskee vähimmäismäärän muokkauksia, joita tarvitaan, jotta ’Str1’ voidaan muuntaa ’Str2:ksi’ suorittamalla joko lisäys-, poisto- tai korvausmerkit. Näin ollen ’Cat’ & ’Bat’ on muokkausetäisyys ’1’ (Korvaa ’C’ ’B:llä’), kun taas ’Ceat’ & ’Bat’, se olisi 2 (Korvaa ’C’ ’B:llä’; Poista ’e’).
Algoritmista puhuttaessa siinä on pääosin 5 vaihetta
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
Aloitamme merkkijonojen lukemisen 1. merkistä
- Jos str1:n indeksissä ’x’ oleva merkki täsmää str2:n indeksissä ’y’ olevan merkin kanssa, muokkausta ei tarvita & lasketaan muokkausetäisyys kutsumalla
LevensteinDistance(str1,str2)
- Jos ne eivät täsmää, tiedämme, että muokkausta tarvitaan. Lisäämme siis +1 nykyiseen edit_etäisyyteen & laskee rekursiivisesti edit_etäisyyden kolmelle ehdolle & ottaa kolmesta pienimmän:
Levenstein(str1,str2) →insertion in str2.
Levenstein(str1,str2) →poisto str2:ssa
Levenstein(str1,str2)→korvaus str2:ssa
- Jos jostain merkkijonosta loppuu merkit rekursion aikana, toisen merkkijonon jäljellä olevien merkkien pituus lisätään muokkausetäisyyteen (kaksi ensimmäistä if-lausetta)
Demerau-Levensteinin etäisyys
Harkitaan ’abcd’ & ’acbd’. Jos menemme Levensteinin etäisyyden mukaan, tämä olisi (korvaa ’b’-’c’ & ’c’-’b’ indeksipaikoilla 2 & 3 str2:ssa) Mutta jos katsot tarkkaan, molemmat merkit on vaihdettu kuten str1:ssä & jos otamme käyttöön uuden operaation ’Swap’ ’lisäyksen’, ’poiston’ & ’korvauksen’ rinnalle, tämä ongelma voidaan ratkaista. Tämä käyttöönotto voi auttaa meitä ratkaisemaan ongelmat kuten ’Agarwal’ & ’Agrawal’.
Tämä operaatio lisätään alla olevalla pseudokoodilla
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Suoritetaan ylläoleva operaatio ’abcd’ & ’acbd’:lle, jossa oletetaan
initial_x=1 & initial_y=1 (Aloitetaan indeksointi 1:stä &, ei 0:sta molemmille merkkijonoille).
nykyinen x=3 & y=3 siis str1 & str2 kohdissa ’c’ (abcd) & ’b’ (acbd) vastaavasti.
Ylärajat mukaan lukien alla mainittu viipalointioperaatio. Näin ollen ’qwerty’ tarkoittaa ’qwer’.
- last_matching_index_y on str2:n viimeinen_indeksi, joka täsmää str1:n kanssa eli 2, koska ’c’ ’acbd:ssä (indeksi 2)täsmää ’c:n’ kanssa ’abcd:ssä’.
- last_matching_index_x on str1:n viimeinen_indeksi, joka täsmää str2:n kanssa i.e 2, koska ’b’ kohdassa ’abcd’ (indeksi 2)täsmää ’b’ kohtaan ’acbd’.
- Yllä olevan pseudokoodin mukaan DemarauLevenstein(’abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(’a’,’a’)=1+0+0+0+0=1. Tämä olisi ollut 2, jos olisimme noudattaneet Levenstein Distance
N-Gram
N-grammi ei periaatteessa ole mitään muuta kuin joukko arvoja, jotka luodaan merkkijonosta parittamalla peräkkäin esiintyvät ’n’ merkkiä/sanaa. Esimerkiksi: n-grammi n=2:lla ’abcd’ on ’ab’,’bc’,’cd’.
Nyt näitä n-grammeja voidaan tuottaa merkkijonoille, joiden samankaltaisuutta halutaan mitata & samankaltaisuuden mittaamiseen voidaan käyttää erilaisia mittareita.
Olkoon ’abcd’ & ’acbd’ 2 sovitettavaa merkkijonoa.
n-grammeja n=2:lle
’abcd’=ab,bc,cd
’acbd’=ac,cb,bd
Komponenttiyhteensopivuus (qgrammia)
Tarkalleen täsmälleen sopivien n-grammien lukumäärää kahdelle merkkijonolle. Tässä se olisi 0
Cosine Similarity
Pistepotentiaalin laskeminen sen jälkeen, kun merkkijonoille generoidut n-grammat on muunnettu vektoreiksi
Component match (järjestystä ei oteta huomioon)
N-grammien komponenttien yhteensovittaminen ottamatta huomioon niiden sisällä olevien elementtien järjestystä, ts. bc=cb.
On olemassa monia muitakin tällaisia mittareita, kuten Jaccard-etäisyys, Tversky-indeksi jne. joita ei ole käsitelty tässä.
BK-puu
BK-puu kuuluu nopeimpiin algoritmeihin, joilla löydetään samankaltaiset merkkijonot (merkkijonojen joukosta) tietylle merkkijonolle. BK-puu käyttää
- Levensteinin etäisyyttä
- Kolmion epätasa-arvoa (käsitellään tämän osion lopussa)
selvittääkseen samankaltaiset merkkijonot (& ei vain yhtä parasta merkkijonoa).
BK-puu luodaan käyttämällä sanavarastoa käytettävissä olevasta sanakirjasta. Sanotaan, että meillä on sanakirja D={Book, Books, Cake, Boo, Boon, Cook, Cape, Cart}
BK-puu luodaan
- Valitaan juurisolmu (voi olla mikä tahansa sana). Olkoon se ’Kirjat’
- Käy läpi jokainen sana W sanakirjassa D, laske sen Levensteinin etäisyys juurisolmuun ja tee sanasta W juuren lapsi, jos vanhemmalle sanalle ei ole olemassa lasta, jolla olisi sama Levensteinin etäisyys. Kirjojen lisääminen & Kakku.
Levenstein(Kirjat,Kirja)=1 & Levenstein(Kirjat,Kakku)=4. Koska ’Kirjalle’ ei löytynyt lasta, jolla olisi sama etäisyys, tee niistä uusia lapsia juurelle.
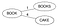
- Jos vanhemmalle P löytyy lapsi, jolla on sama Levenstein-etäisyys, tarkastellaan nyt kyseistä lasta sanan W vanhemmaksi P1, lasketaan Levenstein(parent, word) ja jos vanhemmalle P1 ei ole olemassa lasta, jolla olisi sama etäisyys, tehdään sanasta W uusi lapsi sanalle P1, muuten jatketaan puun alaspäin.
Harkitse Boon lisäämistä. Levenstein(Kirja, Boo)=1 mutta on jo olemassa lapsi, jolla on sama eli Kirjat. Lasketaan siis nyt Levenstein(Kirjat, Boo)=2. Koska Booksille ei ole olemassa lasta, jolla olisi sama etäisyys, tee Boo Booksin lapseksi.

Samoin, lisätään kaikki sanakirjan sanat BK-puuhun

Kun BK-puu on laadittu, samankaltaisten sanojen etsimistä varten tietylle sanalle (Kyselysanalle) on asetettava toleranssin kynnysarvo (tolerance_threshold), sanotaanko ’t’.
- Tämä on suurin edit_distance, jonka otamme huomioon minkä tahansa solmun & query_word välisen samankaltaisuuden määrittämiseksi. Kaikki tätä suurempi hylätään.
- Tulee myös ottaa huomioon vain ne vanhemman solmun lapset vertailussa Queryn kanssa, joissa Levenstein(Child, Parent) on sisällä
miksi? keskustellaan tästä pian
- Jos tämä ehto on totta lapsen kohdalla, laskemme vain Levenstein(Child, Query), jota pidetään samanlaisena kuin Queryä, jos
Levenshtein(Child, Query)≤t.
- Siten emme laske Levensteinin etäisyyttä kaikille sanakirjan solmuille/sanoille, joissa on kyselysana &, joten säästämme paljon aikaa, kun sanavarasto on valtava
Siten, Lapsi on samanlainen kuin Kysely, jos
- Levenstein(Vanhempi, Kysely)-t ≤ Levenstein(Lapsi,Vanhempi) ≤ Levenstein(Vanhempi,Kysely)+t
- Levenstein(Lapsi,Kysely)≤t
Käydään nopeasti läpi esimerkki. Olkoon ’t’=1
Sana, jolle haluamme löytää samankaltaisia sanoja, on ’Care’ (kyselysana)
- Levenstein(Kirja,Care)=4. Koska 4>1, ’Book’ hylätään. Nyt tarkastelemme vain niitä ’Book’:n lapsia, joiden LevisteinDistance(Child,’Book’) on välillä 3(4-1) & 5(4+1). Hylkäämme siis ’Kirjan’ & kaikki sen lapset, koska 1 ei kuulu rajajoukkoon
- Koska Levenstein(Kakku, Kirja)=4, joka on välillä 3 & 5, tarkistamme Levenstein(Kakku, Huolenpito)=1, joka on ≤1, siis samanlainen sana.
- Sovittamalla rajat uudelleen, Kakun lapsille tulee 0(1-1) & 2(1+1)
- Koska molemmilla Kapu & Kärryllä on Levenstein(Lapsi, Vanhempi)=1 & 2 vastaavasti, molemmat ovat oikeutettuja tulemaan testatuksi ’Huolenpidon’ avulla.
- Koska Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, vain Cape katsotaan samankaltaiseksi sanaksi kuin ’Care’.
Siten löysimme 2 sanaa, jotka ovat samankaltaisia kuin ’Care’: Cake & Cape
Mutta millä perusteella päätämme rajoista
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
minkä tahansa lapsisolmun osalta?
Tämä seuraa kolmion epätasa-arvosta, joka sanoo
Etäisyys (A,B) + Etäisyys(B,C)≥Etäisyys(A,C) missä A,B,C ovat kolmion sivut.
Miten tämä ajatus auttaa meitä pääsemään näihin rajoihin, katsotaanpa:
Tulkoon Query,=Q Parent=P & Lapsi=C muodostaen kolmion, jossa on reunan pituutena Levensteinin etäisyys. Olkoon ’t’ toleranssi_raja. Silloin, Ylläolevan epätasa-arvon
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Taas kolmion epätasa-arvon,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Bitap-algoritmi
Se on myös erittäin nopea algoritmi, jota voidaan käyttää sumeiden merkkijonojen täsmäytykseen melko tehokkaasti. Tämä johtuu siitä, että se käyttää bittioperaatioita & koska ne ovat melko nopeita, algoritmi on tunnettu nopeudestaan. Tuhlaamatta yhtään mitään, aloitetaan:
Asettakaavio S0=’abababc’ on merkkijonon S1=’abdababababc’ kanssa sovitettava kuvio.
Aluksi,
- Löydetään kaikki S1:ssä olevat yksilölliset merkit & S0:n merkit, jotka ovat a,b,c,d
- muodostetaan bittikuviot jokaiselle merkille. Miten?

- Käännä etsittävä kuvio S0 päinvastaiseksi
- Merkin x bittikuvion saamiseksi merkin x kohdalle laitetaan 0 sinne, missä se esiintyy kuviossa muuten 1. T:ssä ’a’ esiintyy 3. & 5. paikassa, sijoitimme 0 näihin paikkoihin & loput 1.
Muodostetaan samalla tavalla kaikki muutkin bittikuviot sanakirjan eri merkeille.
S0=ababc S1=abdababababc
- Vastaanotamme alkutilaksi bittikuvion pituudeltaan(S0), jossa on kaikki 1:t. Meidän tapauksessamme se olisi 11111 (tila S).
- Kun aloitamme etsimisen S1:stä ja käymme läpi minkä tahansa merkin,
siirrämme 0:n alimpaan bittiin eli viidenteen bittiin oikealta S:ssä &
OR-operaatio S:lle ja T:lle.
Siten, kun kohtaamme 1. ’a’-merkin S1:ssä, me
- siirrämme vasemmalle 0:n S:ssä alimmassa bitissä muodostaaksemme 11111 →11110
- 11010 | 11110=11110
Nyt, kun siirrymme 2. merkkiin ’b’
- siirrämme 0:n S:ään i.e muotoon 11110 →11100
- S |T=11100 | 10101=11101
Kun ’d’ kohdataan
- Vaihda 0 S:ään muotoon 11101 →11010
- S |T=11010 |11111=11111
Huomaa, että koska ’d’ ei ole S0:ssa, S-tila S nollautuu. Kun käyt läpi koko S1:n, saat alla olevat tilat jokaisen merkin kohdalla

Miten tiedän, löysinkö yhtään epäselvää/täydellistä vastaavuutta?
- Jos 0 saavuttaa State S:n bittikuvion ylimmän bitin (kuten viimeisessä merkissä ’c’), sinulla on täysi täsmääminen
- Fuzz-matchia varten havainnoi 0:ta State S:n eri kohdissa. Jos 0 on 4. sijalla, löysimme 4/5 merkkiä samassa järjestyksessä kuin S0:ssa. Vastaavasti 0:n ollessa muissa paikoissa.
Yksi asia, jonka olet ehkä huomannut, on se, että kaikki nämä algoritmit toimivat merkkijonojen kirjoitusasun samankaltaisuuden perusteella. Voiko sumealle yhteensovittamiselle olla muita kriteerejä? Kyllä,
Fonetiikka
Käsittelemme seuraavaksi fonetiikkaan(äännepohjaiset, kuten Saurav & Sourav, pitäisi olla tarkka vastine fonetiikassa) perustuvia fuzz match -algoritmeja !!!
- Dimension Reduction (3 osaa)
- NLP Algorithms(5 osaa)
- Reinforcement Learning Basics (5 osaa)
- Starting off with Time-Series (7 osaa)
- Object Detection using YOLO (3 osaa)
- Tensorflow aloittelijoille (käsitteet + esimerkit) (4 osaa)
- Aikasarjojen esikäsittely (koodeineen)
- Data-analytiikka aloittelijoille
- Tilastotiede aloittelijoille (4 osaa)