- Introduction
- Tavoite
- A. Suodatusmenetelmät
- Chi-neliö-testi
- Fisherin pistemäärä
- Korrelaatiokerroin
- Varianssikynnys
- Mean Absolute Difference (MAD)
- Hajontasuhde
- B. Kääremenetelmät:
- Forward Feature Selection
- Backward Feature Elimination
- Tyhjentävä ominaisuuksien valinta
- Rekursiivinen ominaisuuksien eliminointi
- C. Sulautetut menetelmät:
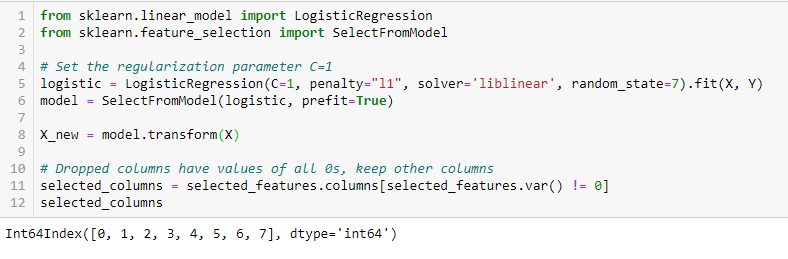
- LASSO Regularisointi (L1)
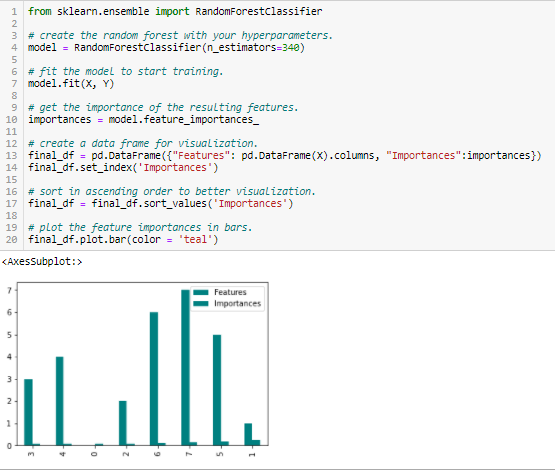
- Random Forest Importance
- Johtopäätös
Introduction
Koneoppimismallia rakennettaessa tosielämässä on lähes harvinaista, että kaikki tietokokonaisuuden muuttujat ovat hyödyllisiä mallin rakentamisessa. Turhien muuttujien lisääminen vähentää mallin yleistyskykyä ja saattaa myös vähentää luokittelijan kokonaistarkkuutta. Lisäksi yhä useampien muuttujien lisääminen malliin lisää mallin yleistä monimutkaisuutta.
Occamin parsimonian lain (Occam’s Razor) mukaan paras selitys ongelmaan on se, joka sisältää mahdollisimman vähän oletuksia. Näin ollen piirteiden valinnasta tulee välttämätön osa koneoppimisen mallien rakentamista.
Tavoite
Koneoppimisen piirteiden valinnan tavoitteena on löytää paras piirteiden joukko, jonka avulla voidaan rakentaa käyttökelpoisia malleja tutkituista ilmiöistä.
Koneoppimisen piirteiden valintatekniikat voidaan karkeasti luokitella seuraaviin kategorioihin:
Valvotut tekniikat: Näitä tekniikoita voidaan käyttää leimattuun dataan, ja niitä käytetään relevanttien piirteiden tunnistamiseen valvottujen mallien, kuten luokittelun ja regression, tehokkuuden lisäämiseksi.
Valvomattomat tekniikat: Näitä tekniikoita voidaan käyttää merkitsemättömään dataan.
Taksonomisesta näkökulmasta nämä tekniikat luokitellaan seuraavasti:
A. Suodatusmenetelmät
B. Kääremenetelmät
C. Sulautetut menetelmät
D. Hybridimenetelmät
Tässä artikkelissa käsittelemme joitakin suosittuja ominaisuuksien valintamenetelmiä koneoppimisessa.
A. Suodatusmenetelmät
Suodatusmenetelmät poimivat ominaisuuksien luontaisia ominaisuuksia, joita mitataan yksimuuttujatilastojen avulla ristiinvalidointisuorituskyvyn sijaan. Nämä menetelmät ovat nopeampia ja vähemmän laskennallisesti kalliita kuin kääremenetelmät. Kun käsitellään korkea-ulotteista dataa, on laskennallisesti halvempaa käyttää suodatinmenetelmiä.
Keskustellaanpa muutamista näistä tekniikoista:
Informaatiovoitto
Informaatiovoitto laskee tietokokonaisuuden transformaatiosta aiheutuvan entropian vähenemisen. Sitä voidaan käyttää piirteiden valintaan arvioimalla kunkin muuttujan informaatiovoittoa kohdemuuttujan yhteydessä.
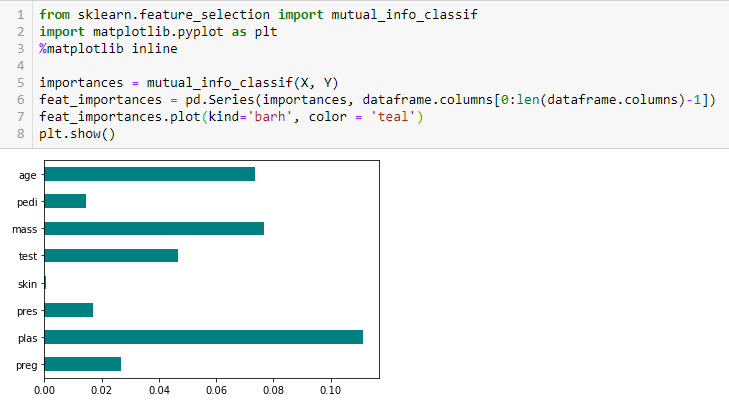
Chi-neliö-testi
Chi-neliö-testiä käytetään kategorisille piirteille aineistossa. Lasketaan khiin neliö kunkin piirteen ja kohteen välillä ja valitaan haluttu määrä piirteitä, joilla on parhaat khiin neliö-pisteet. Jotta khiin neliö -testiä voidaan soveltaa oikein testattaessa aineistossa olevien eri piirteiden ja kohdemuuttujan välistä yhteyttä, seuraavien ehtojen on täytyttävä: muuttujien on oltava kategorisia, otoksen on oltava riippumaton ja arvojen odotetun frekvenssin on oltava suurempi kuin 5.
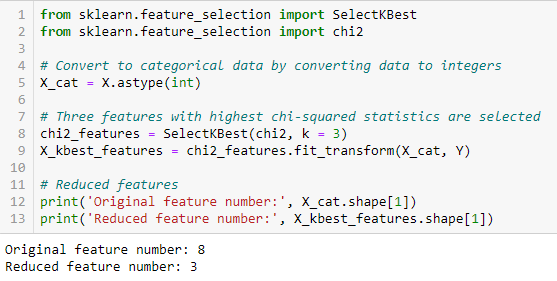
Fisherin pistemäärä
Fisherin pistemäärä (Fisher’s Score
Fisherin pistemäärä (Fisher’s Score)) on yksi laajimmin käytetyistä valvotuista piirteiden valinta menetelmistä. Algoritmi, jota käytämme, palauttaa muuttujien sijat Fisherin pistemäärän perusteella alenevassa järjestyksessä. Tämän jälkeen voimme valita muuttujat tapauksen mukaan.
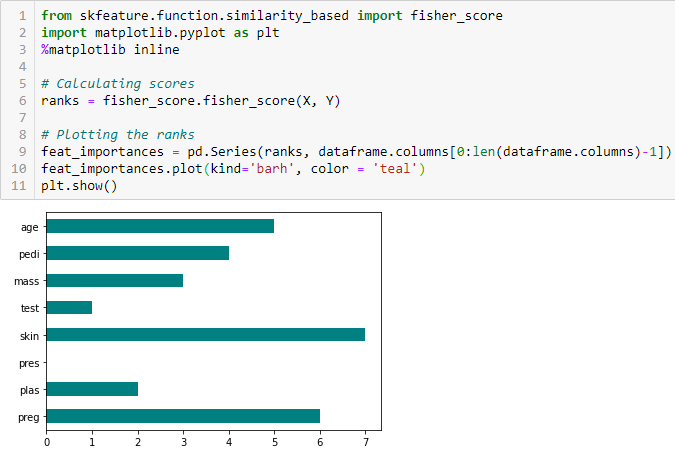
Korrelaatiokerroin
Korrelaatio on kahden tai useamman muuttujan lineaarisen suhteen mitta. Korrelaation avulla voimme ennustaa yhden muuttujan toisesta. Korrelaation käyttämisen logiikka ominaisuuksien valinnassa on se, että hyvät muuttujat korreloivat voimakkaasti kohteen kanssa. Lisäksi muuttujien tulisi korreloida kohteen kanssa, mutta olla keskenään korreloimattomia.
Jos kaksi muuttujaa korreloi, voimme ennustaa toisen toisesta. Jos siis kaksi muuttujaa korreloi, malli tarvitsee oikeastaan vain toista niistä, sillä toinen ei tuo lisäinformaatiota. Käytämme tässä Pearsonin korrelaatiota.
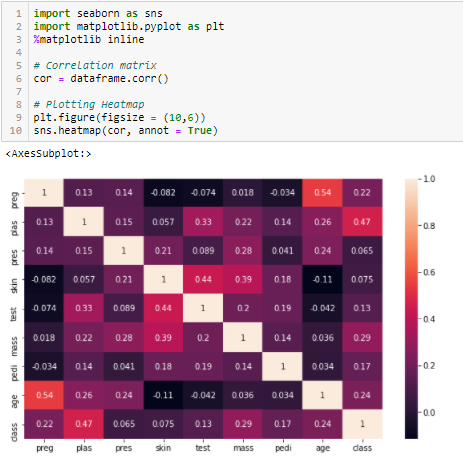
Muuttujien valintakynnykseksi on asetettava absoluuttinen arvo, esimerkiksi 0,5. Jos havaitsemme, että ennustemuuttujat korreloivat keskenään, voimme jättää pois muuttujan, jonka korrelaatiokertoimen arvo on pienempi kohdemuuttujan kanssa. Voimme myös laskea useita korrelaatiokertoimia tarkistaaksemme, korreloivatko useammat kuin kaksi muuttujaa keskenään. Tätä ilmiötä kutsutaan multikollineaarisuudeksi.
Varianssikynnys
Varianssikynnys on yksinkertainen peruslähestymistapa ominaisuuksien valintaan. Se poistaa kaikki piirteet, joiden varianssi ei täytä jotain kynnysarvoa. Oletusarvoisesti se poistaa kaikki nollavarianssin piirteet, eli piirteet, joilla on sama arvo kaikissa näytteissä. Oletamme, että piirteet, joilla on suurempi varianssi, saattavat sisältää enemmän hyödyllistä tietoa, mutta huomaa, että emme ota huomioon piirteen muuttujien tai piirteen ja kohdemuuttujien välistä suhdetta, mikä on yksi suodatinmenetelmien haittapuolista.

Get_support palauttaa Boolean-vektorin, jossa True tarkoittaa, että muuttujalla ei ole nollavarianssia.
Mean Absolute Difference (MAD)
’Mean Absolute Difference eli absoluuttinen keskiarvoero (Mean Absolute Difference, MAD) laskee absoluuttisen erotuksen keskiarvosta. Tärkein ero varianssi- ja MAD-mittojen välillä on se, että jälkimmäisessä ei ole neliötä. MAD, kuten varianssi, on myös asteikkomuunnos. Tämä tarkoittaa sitä, että suurempi MAD, suurempi erottelukyky.
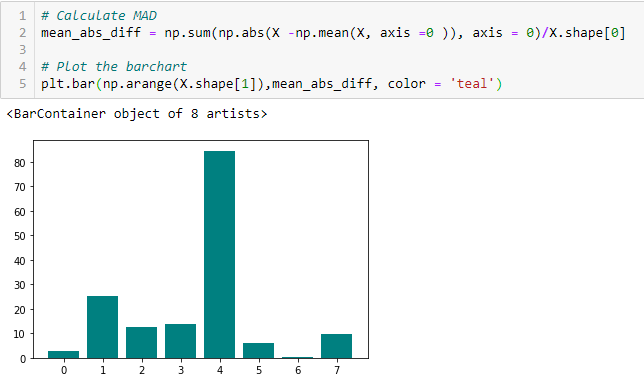
Hajontasuhde
’Toinen hajonnan mittari soveltaa aritmeettista keskiarvoa (AM) ja geometrista keskiarvoa (GM). Tietylle (positiiviselle) piirteelle Xi n kuviossa AM ja GM saadaan
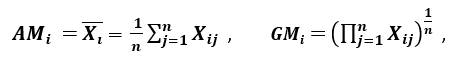
joka on
; koska AMi ≥ GMi, jolloin yhtäläisyys pätee, jos ja vain jos Xi1 = Xi2 = …. = Xin, niin suhdelukua
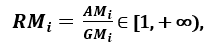
voidaan käyttää hajontamittarina. Suurempi hajonta merkitsee Ri:n suurempaa arvoa ja siten merkityksellisempää ominaisuutta. Kääntäen, kun kaikilla piirteen näytteillä on (suurin piirtein) sama arvo, Ri on lähellä arvoa 1, mikä osoittaa vähärelevanttia piirrettä.

 ’
’
B. Kääremenetelmät:
Kääreet vaativat jonkin menetelmän, jolla etsitään kaikkien mahdollisten piirteiden osajoukkojen avaruus ja arvioidaan niiden laatu oppimalla ja arvioimalla luokittelija kyseisellä piirteiden osajoukolla. Ominaisuuksien valintaprosessi perustuu tiettyyn koneoppimisalgoritmiin, jota yritetään sovittaa tietylle tietokokonaisuudelle. Se noudattaa ahnetta hakumenetelmää arvioimalla kaikkia mahdollisia ominaisuuksien yhdistelmiä arviointikriteeriä vasten. Käärintämenetelmät johtavat yleensä parempaan ennustustarkkuuteen kuin suodatinmenetelmät.
Keskustellaanpa näistä tekniikoista:
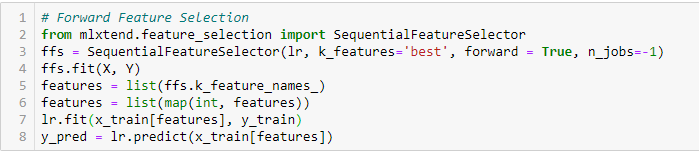
Forward Feature Selection
Tämä on iteratiivinen menetelmä, jossa aloitetaan parhaiten suoriutuvasta muuttujasta tavoitetta vastaan. Seuraavaksi valitaan toinen muuttuja, joka antaa parhaan suorituskyvyn yhdessä ensin valitun muuttujan kanssa. Tätä prosessia jatketaan, kunnes ennalta asetettu kriteeri on saavutettu.
Backward Feature Elimination
Tämä menetelmä toimii täsmälleen päinvastoin kuin Forward Feature Selection -menetelmä. Tässä aloitetaan kaikista käytettävissä olevista piirteistä ja rakennetaan malli. Seuraavaksi valitsemme mallista sen muuttujan, joka antaa parhaan arviointimittarin arvon. Tätä prosessia jatketaan, kunnes ennalta asetettu kriteeri on saavutettu.
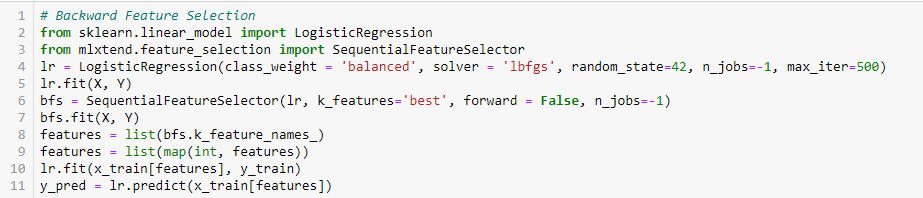
Tämä menetelmä yhdessä edellä käsitellyn kanssa tunnetaan myös nimellä sekventiaalinen ominaisuuksien valintamenetelmä.
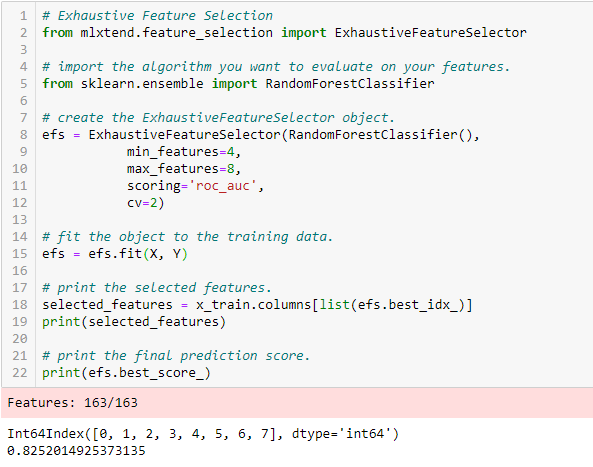
Tyhjentävä ominaisuuksien valinta
Tämä on tähän mennessä käsitellyistä ominaisuuksien valintamenetelmistä vankin. Kyseessä on jokaisen piirteen osajoukon raa’an voiman arviointi. Tämä tarkoittaa, että se kokeilee kaikkia mahdollisia muuttujien yhdistelmiä ja palauttaa parhaiten toimivan osajoukon.
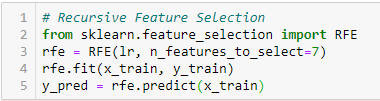
Rekursiivinen ominaisuuksien eliminointi
’Kun on olemassa ulkoinen estimaattori, joka antaa painotuksia ominaisuuksille (esim. lineaarisen mallin kertoimet), rekursiivisen ominaisuuksien eliminoinnin (RFE, recursive feature elimination) tavoitteena on valita ominaisuudet tarkastelemalla rekursiivisesti yhä pienempiä ja pienempiä ominaisuussarjoja. Ensin estimaattori koulutetaan alkuperäisellä piirrejoukolla, ja kunkin piirteen tärkeys saadaan joko coef_-attribuutin tai feature_importances_-attribuutin avulla.
Sitten vähiten tärkeät piirteet karsitaan nykyisestä piirrejoukosta. Tämä menettely toistetaan rekursiivisesti karsitulle joukolle, kunnes lopulta saavutetaan haluttu määrä valittavia piirteitä.”
C. Sulautetut menetelmät:
Nämä menetelmät sisältävät sekä kääre- että suodatinmenetelmien edut sisällyttämällä piirteiden vuorovaikutukset, mutta säilyttämällä samalla kohtuulliset laskentakustannukset. Sulautetut menetelmät ovat iteratiivisia siinä mielessä, että huolehtii mallin koulutusprosessin jokaisesta iteraatiosta ja poimii huolellisesti ne piirteet, jotka edistävät eniten tietyn iteraation koulutusta.
Keskustellaanpa, keskustellaan joistakin näistä tekniikoista klikkaamalla tästä:
LASSO Regularisointi (L1)
Regularisointi koostuu rangaistuksen lisäämisestä konekielisen oppimismallin eri parametreihin mallin vapauden vähentämiseksi eli ylisovittamisen välttämiseksi. Lineaarisen mallin regularisoinnissa rangaistusta sovelletaan niiden kertoimien päälle, jotka kertovat kunkin ennustajan. Eri regularisointityypeistä Lassolla eli L1:llä on se ominaisuus, että se pystyy kutistamaan osan kertoimista nollaan. Siksi kyseinen ominaisuus voidaan poistaa mallista.
Random Forest Importance
Random Forests on eräänlainen bagging-algoritmi, joka kokoaa yhteen tietyn määrän päätöspuita. Satunnaismetsien käyttämät puupohjaiset strategiat asettuvat luonnollisesti paremmuusjärjestykseen sen mukaan, kuinka hyvin ne parantavat solmun puhtautta eli epäpuhtauden (Gini-epäpuhtauden) vähenemistä kaikkien puiden yli. Solmut, joissa epäpuhtauden väheneminen on suurinta, sijaitsevat puiden alussa, kun taas solmut, joissa epäpuhtauden väheneminen on vähäisintä, sijaitsevat puiden lopussa. Näin ollen karsimalla puita tietyn solmun alapuolelta voimme luoda osajoukon tärkeimmistä piirteistä.
Johtopäätös
Olemme käsitelleet muutamia piirteiden valintatekniikoita. Olemme tarkoituksella jättäneet pois sellaiset ominaisuuksien poimintatekniikat kuin pääkomponenttianalyysi, singulaariarvon hajotus, lineaarinen diskriminaatioanalyysi jne. Nämä menetelmät auttavat pienentämään datan dimensiota tai vähentämään muuttujien lukumäärää säilyttäen samalla datan varianssin.
Edellä käsiteltyjen menetelmien lisäksi on olemassa monia muitakin ominaisuuksien valintamenetelmiä. On olemassa myös hybridimenetelmiä, joissa käytetään sekä suodatus- että käärintätekniikoita. Jos haluat tutustua tarkemmin ominaisuuksien valintatekniikoihin, hyvää ja kattavaa luettavaa on mielestäni Urszula Stańczykin ja Lakhmi C:n teos ’Feature Selection for Data and Pattern Recognition’. Jain.