- Funktio ja sen derivaatta ovat molemmat monotonisia
- Tulos on nollakeskinen
- Optimointi on helpompaa
- Tanh-funktion derivaatta /Differentiaali (f'(x)) sijoittuu välille 0 ja 1.
Miinukset:
- Tanh-funktion derivaatta kärsii ”katoavan gradientin ja räjähtävän gradientin ongelmasta”.
- Hidas konvergenssi- koska se on laskennallisesti raskas.(Syy eksponenttifunktion käyttöön )
”Tanh on parempi kuin sigmoidifunktio, koska se on nollakeskitetty ja gradientteja ei ole rajoitettu liikkumaan tiettyyn suuntaan”
3. ReLu-aktivointifunktio (ReLu – oikaistut lineaariset yksiköt): ReLun derivaatta (vihreä)
ReLu on ei-lineaarinen aktivointifunktio, joka on saavuttanut suosiota tekoälyssä. ReLu-funktio esitetään myös muodossa f(x) = max(0,x).
- Funktio ja sen derivaatta ovat molemmat monotonisia.
- Tärkein etu ReLU-funktion käytössä- Se ei aktivoi kaikkia neuroneja samanaikaisesti.
- Laskennallisesti tehokas
- Tanh-funktion (f'(x)) derivaatta/differentiaali on 1 jos f(x) > 0 muuten 0.
- Konvertoituu erittäin nopeasti
Miinukset:
- ReLu-funktio ei ole ”nollakeskeinen ”Tämä saa gradienttipäivitykset menemään liian pitkälle eri suuntiin. 0 < lähtö < 1, ja se tekee optimoinnista vaikeampaa.
- Kuollut neuroni on suurin ongelma.tämä johtuu siitä, että funktio ei ole differentioituva nollapisteessä.
”Kuolevan neuronin/kuolleen neuronin ongelma : Koska ReLu:n derivaatta f'(x) ei ole 0 neuronin positiivisille arvoille (f'(x)=1 for x ≥ 0), ReLu:n funktio ei kyllästy (eksploidaan) eikä kuolleita neuroneja (Vanishing neuron)ilmoiteta. Saturaatiota ja katoavaa gradienttia esiintyy vain negatiivisille arvoille, jotka ReLulle annettuna muuttuvat 0:ksi- Tätä kutsutaan kuolevan neuronin ongelmaksi.”
4. vuotava ReLun aktivointifunktio:
Vuotava ReLU-funktio ei ole mitään muuta kuin parannettu versio ReLU-funktiosta, jossa on otettu käyttöön ”vakiokaltevuus”


- Leaky ReLU on määritelty puuttumaan kuolevan neuronin/kuolleen neuronin ongelmaan.
- Kuolevan neuronin/kuolleen neuronin ongelmaan puututaan ottamalla käyttöön pieni kaltevuus, jonka negatiiviset arvot skaalataan α:lla, mahdollistaa niiden vastaavien neuronien ”pysymisen hengissä”.
- Funktio ja sen derivaatta ovat molemmat monotonisia
- Se sallii negatiiviset arvot takaisinkytkennän aikana
- Se on tehokasta ja helppoa laskea.
- Leakyn derivaatta on 1, kun f(x) > 0 ja vaihtelee välillä 0-1, kun f(x) < 0.
Miinukset:
- Leaky ReLU ei anna johdonmukaisia ennusteita negatiivisille tuloarvoille.
5. ELU (Eksponentiaaliset lineaariset yksiköt) Aktivointifunktio:

- ELU ehdotetaan myös kuolevan neuronin ongelman ratkaisemiseksi.
- Ei Dead ReLU -ongelmia
- Nollakeskeinen
Miinukset:
- Laskennallisesti intensiivinen.
- Samankaltainen kuin vuotava ReLU, vaikka teoreettisesti parempi kuin ReLU, tällä hetkellä ei ole hyvää käytännön näyttöä siitä, että ELU olisi aina parempi kuin ReLU.
- f(x) on monotoninen vain jos alfa on suurempi tai yhtä suuri kuin 0.
- f'(x) ELU:n derivaatta on monotoninen vain, jos alfa on 0:n ja 1:n välillä.
- Hidas konvergenssi eksponenttifunktion takia.
6. P ReLu (Parametrinen ReLU) Aktivointifunktio:

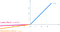
- Ajatusta vuotavasta ReLU:sta voidaan laajentaa vielä pidemmälle.
- Sen sijaan, että kertoisimme x:n vakiotermillä, voimme kertoa sen ”hyperparametrilla (a-treenattava parametri)”, joka näyttää toimivan paremmin kuin leaky ReLU. Tätä vuotavan ReLU:n laajennusta kutsutaan parametriseksi ReLU:ksi.
- Parametri α on yleensä luku 0:n ja 1:n välillä, ja se on yleensä suhteellisen pieni.
- On hieman etulyöntiasemassa vuotavaan ReLU:hun nähden treenattavan parametrin ansiosta.
- Käsittelee kuolevan neuronin ongelmaa.
Miinukset:
- Sama kuin leaky Relu.
- f(x) on monotoninen kun a> tai =0 ja f'(x) on monotoninen kun a =1
7. Swish (A Self-Gated) Activation Function: (Sigmoid Linear Unit)

- Google Brain Team on ehdottanut uutta aktivointifunktiota, nimeltään Swish, joka on yksinkertaisesti f(x) = x – sigmoid(x).
- Heidän kokeilunsa osoittavat, että Swish pyrkii toimimaan paremmin kuin ReLU syvemmissä malleissa useissa haastavissa datajoukoissa.
- Swish-funktion käyrä on sileä ja funktio on differentioituva kaikissa pisteissä. Tämä on hyödyllistä mallin optimointiprosessin aikana, ja sitä pidetään yhtenä syynä siihen, että Swish päihittää ReLU:n.
- Swish-funktio on ”ei monotoninen”. Tämä tarkoittaa, että funktion arvo voi pienentyä, vaikka syöttöarvot kasvavat.
- Funktio on yläpuolella rajoittamaton ja alapuolella rajoitettu.
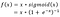
”Swishillä on taipumus jatkuvasti vastata ReLu:ta tai ylittää sen.”
Huomaa, että swish-funktion ulostulo voi laskea, vaikka tuloarvo kasvaa. Tämä on mielenkiintoinen ja Swishille ominainen piirre.(johtuen ei-monotonisesta luonteesta)
f(x)=2x*sigmoidi(beta*x)
Jos ajattelemme, että beta=0 on Swishin yksinkertainen versio, joka on opittavissa oleva parametri, niin sigmoidiosa on aina 1/2 ja f (x) on lineaarinen. Toisaalta, jos beta on hyvin suuri arvo, sigmoidista tulee lähes kaksinumeroinen funktio (0 kun x<0,1 kun x>0). Näin ollen f (x) konvergoi ReLU-funktion kanssa. Tämän vuoksi valitaan Swishin vakiofunktioksi beta = 1. Näin saadaan aikaan pehmeä interpolointi (muuttujien arvojoukkojen liittäminen funktioon annetulla alueella ja halutulla tarkkuudella). Erinomaista! Ratkaisu gradienttien katoamisongelmaan on löydetty.
8.Softplus
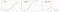
Softaplus-funktio on samankaltainen kuin ReLU-funktio, mutta se on suhteellisesti tasaisempi.Softplus- tai SmoothRelu-funktio f(x) = ln(1+exp x).
Softplus-funktion derivaatta on f'(x) on logistinen funktio (1/(1+exp x)).
Funktion arvo vaihtelee välillä (0, + inf).Sekä f(x) että f'(x) ovat monotonisia.
9.Softmax eli normalisoitu eksponenttifunktio:

”Softmax”-funktio on myös eräänlainen sigmoidifunktio, mutta se on erittäin käyttökelpoinen moniluokkaisten luokitteluongelmien käsittelyssä.
”Softmax” -funktio voidaan kuvata useiden sigmoidifunktioiden yhdistelmänä.”
”Softmax-funktio palauttaa todennäköisyyden, jolla datapiste kuuluu kuhunkin yksittäiseen luokkaan.”
Kehitettäessä verkkoa usean luokan ongelmaa varten lähtökerroksessa olisi yhtä monta neuronia kuin kohteessa on luokkia.”
Jos esimerkiksi luokkia on kolme, lähtökerroksessa olisi kolme neuronia. Oletetaan, että saat neuronien ulostulon arvoksi.Soveltamalla softmax-funktiota näihin arvoihin saat seuraavan tuloksen – . Nämä edustavat todennäköisyyttä sille, että datapiste kuuluu kuhunkin luokkaan. Tuloksesta voimme päätellä, että tulo kuuluu luokkaan A.
”Huomaa, että kaikkien arvojen summa on 1.”
Kumpaa on parempi käyttää ? Miten valita oikea?
Ollakseni rehellinen, ei ole olemassa mitään kovaa ja nopeaa sääntöä aktivointifunktion valintaan.Emme voi erottaa aktivointifunktioita toisistaan.Jokaisella aktivointifunktiolla on omat hyvät ja huonot puolensa.Kaikki hyvä ja huono päätetään jäljen perusteella.
Mutta ongelman ominaisuuksien perusteella voimme ehkä tehdä paremman valinnan verkon helpomman ja nopeamman konvergenssin saavuttamiseksi.
- Sigmoidifunktiot ja niiden yhdistelmät toimivat yleensä paremmin luokitusongelmissa
- Sigmoidifunktioita ja tanh-funktioita vältetään joskus katoavan gradientin ongelman vuoksi
- ReLU-aktivointifunktio on laajalti käytössä nykyaikana.
- Jos verkoissamme on kuolleita neuroneja ReLU:n takia, niin vuotava ReLU-funktio on paras valinta
- ReLU-funktiota tulisi käyttää vain piilokerroksissa
”Nyrkkisääntönä voidaan aloittaa ReLU-funktion käyttäminen ja siirtyä sitten muihin aktivointifunktioihin, jos ReLU ei tuota optimaalisia tuloksia”