- Indledning
- Mål
- A. Filtermetoder
- Chi-kvadrat-test
- Fishers score
- Korrelationskoefficient
- Variancetærskel
- Mean Absolute Difference (MAD)
- Spredningsforhold
- B. Wrapper-metoder:
- Forward Feature Selection
- Backward Feature Elimination
- Exhaustive Feature Selection
- Recursiv Feature Elimination
- C. Indlejrede metoder:
- LASSO Regularization (L1)
- Random Forest Importance
- Slutning
Indledning
Når man opbygger en maskinlæringsmodel i det virkelige liv, er det næsten sjældent, at alle variabler i datasættet er nyttige til at opbygge en model. Tilføjelse af redundante variabler reducerer modellens generaliseringsevne og kan også reducere den samlede nøjagtighed af en klassifikator. Desuden øger tilføjelse af flere og flere variabler til en model modellens samlede kompleksitet.
Som følge loven om parsimoni i “Occams razor” er den bedste forklaring på et problem den, der involverer færrest mulige antagelser. Derfor bliver udvælgelse af funktioner en uundværlig del af opbygningen af maskinlæringsmodeller.
Mål
Målet med udvælgelse af funktioner i maskinlæring er at finde det bedste sæt af funktioner, der gør det muligt at opbygge nyttige modeller af de undersøgte fænomener.
Teknikkerne til udvælgelse af funktioner i maskinlæring kan groft sagt inddeles i følgende kategorier:
Superviserede teknikker: Disse teknikker kan anvendes til mærkede data og bruges til at identificere de relevante funktioner for at øge effektiviteten af overvågede modeller som klassifikation og regression.
Usuperviserede teknikker: Disse teknikker kan bruges til at identificere de relevante funktioner for at øge effektiviteten af overvågede modeller som klassifikation og regression.
Usuperviserede teknikker: Disse teknikker kan anvendes til umærkede data.
Fra et taksonomisk synspunkt er disse teknikker klassificeret som følger:
A. Filtermetoder
B. Wrapper-metoder
C. Indlejrede metoder
D. Hybridmetoder
I denne artikel vil vi diskutere nogle populære teknikker til udvælgelse af funktioner i maskinlæring.
A. Filtermetoder
Filtermetoder henter de iboende egenskaber ved funktionerne, der måles via univariate statistikker i stedet for krydsvalideringspræstationer. Disse metoder er hurtigere og mindre beregningsmæssigt dyre end wrapper-metoder. Når der er tale om højdimensionelle data, er det beregningsmæssigt billigere at anvende filtermetoder.
Lad os, diskutere nogle af disse teknikker:
Informationsgevinst
Informationsgevinst beregner reduktionen i entropi fra transformationen af et datasæt. Den kan bruges til udvælgelse af funktioner ved at evaluere informationsgevinsten for hver enkelt variabel i forbindelse med målvariablen.
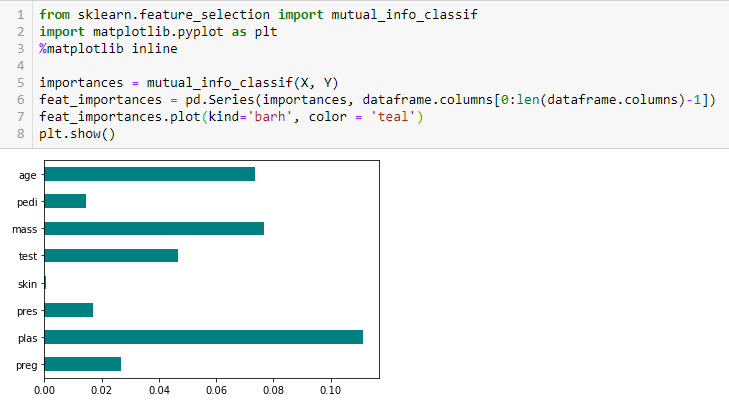
Chi-kvadrat-test
Chi-kvadrat-testen bruges til kategoriske funktioner i et datasæt. Vi beregner Chi-square mellem hver funktion og målet og vælger det ønskede antal funktioner med de bedste Chi-square-scorer. For at anvende chi-kvadrat-testen korrekt for at teste forholdet mellem forskellige funktioner i datasættet og målvariablen skal følgende betingelser være opfyldt: Variablerne skal være kategoriske, udtages uafhængigt af hinanden, og værdierne skal have en forventet frekvens større end 5.
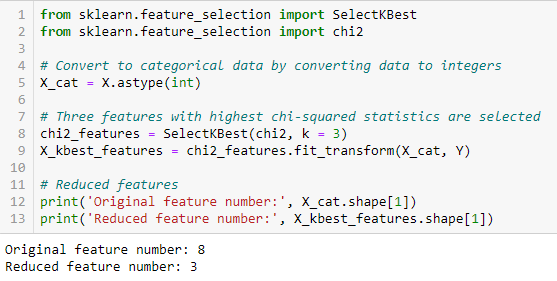
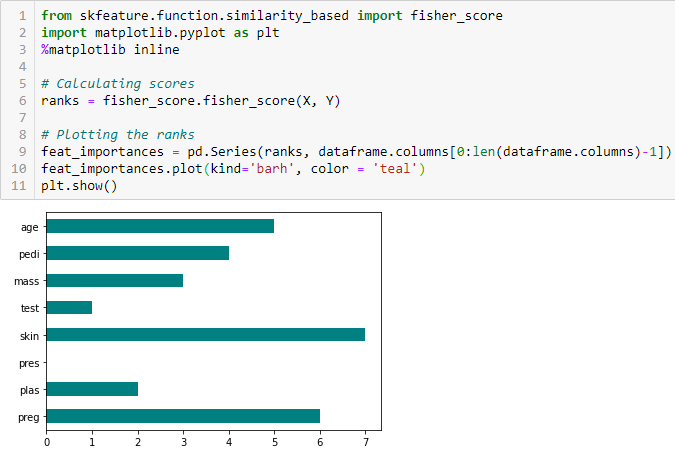
Fishers score
Fishers score er en af de mest udbredte superviserede metoder til udvælgelse af funktioner. Den algoritme, som vi vil bruge, returnerer rangeringen af variablerne baseret på Fisher’s score i faldende rækkefølge. Vi kan derefter vælge variablerne efter tilfældet.
Korrelationskoefficient
Korrelation er et mål for den lineære sammenhæng mellem 2 eller flere variabler. Gennem korrelation kan vi forudsige den ene variabel ud fra den anden. Logikken bag brugen af korrelation til udvælgelse af funktioner er, at de gode variabler er stærkt korreleret med målet. Endvidere bør variablerne være korreleret med målet, men bør være ukorreleret indbyrdes.
Hvis to variabler er korreleret, kan vi forudsige den ene ud fra den anden. Hvis to egenskaber er korreleret, har modellen derfor kun virkelig brug for den ene af dem, da den anden ikke tilføjer yderligere oplysninger. Vi bruger Pearson-korrelationen her.
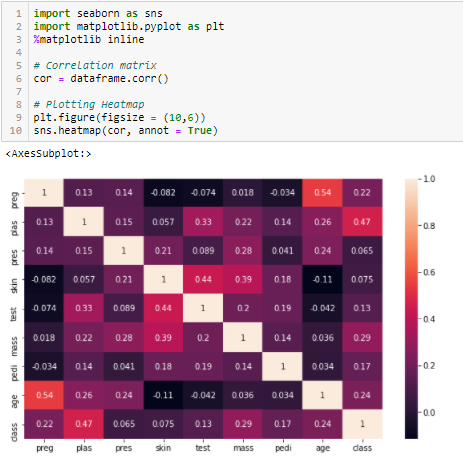
Vi skal indstille en absolut værdi, f.eks. 0,5, som tærskelværdi for udvælgelse af variablerne. Hvis vi finder, at prædiktorvariablerne er indbyrdes korreleret, kan vi droppe den variabel, som har en lavere korrelationskoefficientværdi med målvariablen. Vi kan også beregne flere korrelationskoefficienter for at kontrollere, om mere end to variabler er korreleret med hinanden. Dette fænomen er kendt som multikollinearitet.
Variancetærskel
Variancetærsklen er en simpel grundtilgang til udvælgelse af funktioner. Den fjerner alle funktioner, hvis varians ikke opfylder en vis tærskelværdi. Som standard fjerner den alle funktioner med nulvarians, dvs. funktioner, der har den samme værdi i alle prøver. Vi antager, at features med en højere varians kan indeholde mere nyttig information, men bemærk, at vi ikke tager hensyn til forholdet mellem feature-variabler eller feature- og målvariabler, hvilket er en af ulemperne ved filtermetoder.

Get_support returnerer en boolsk vektor, hvor True betyder, at variablen ikke har nul varians.
Mean Absolute Difference (MAD)
‘Den gennemsnitlige absolutte forskel (MAD) beregner den absolutte forskel i forhold til middelværdien. Den væsentligste forskel mellem varians- og MAD-målingerne er, at der ikke findes et kvadrat i sidstnævnte. MAD er ligesom variansen også en skalavariant. Det betyder, at højere MAD, højere diskriminerende effekt.
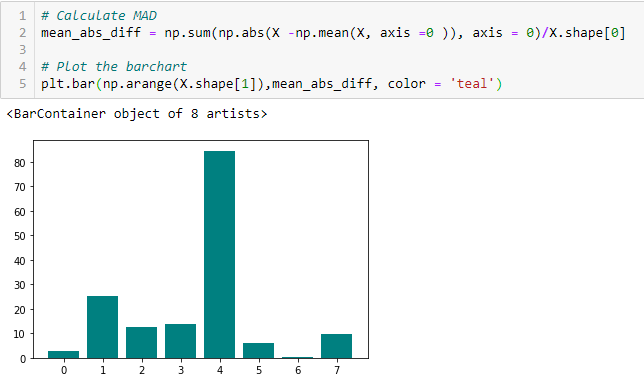
Spredningsforhold
‘Et andet mål for spredning anvender det aritmetiske gennemsnit (AM) og det geometriske gennemsnit (GM). For et givet (positivt) kendetegn Xi på n mønstre er AM og GM givet ved
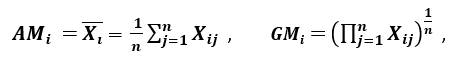
respektivt; da AMi ≥ GMi, med lighed, der gælder hvis og kun hvis Xi1 = Xi2 = …. = Xin, kan forholdet
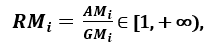
anvendes som spredningsmål. En højere spredning indebærer en højere værdi af Ri, og dermed et mere relevant træk. Omvendt, når alle funktionsprøverne har (nogenlunde) den samme værdi, er Ri tæt på 1, hvilket indikerer en funktion med lav relevans.

 ‘
‘
B. Wrapper-metoder:
Wrappers kræver en metode til at søge i rummet af alle mulige delmængder af funktioner og vurdere deres kvalitet ved at lære og evaluere en klassifikator med den pågældende delmængde af funktioner. Processen til udvælgelse af funktioner er baseret på en specifik maskinlæringsalgoritme, som vi forsøger at tilpasse på et givet datasæt. Den følger en greedy search-metode ved at evaluere alle mulige kombinationer af funktioner i forhold til evalueringskriteriet. Wrapper-metoderne resulterer normalt i en bedre forudsigelsesnøjagtighed end filtermetoder.
Lad os, diskutere nogle af disse teknikker:
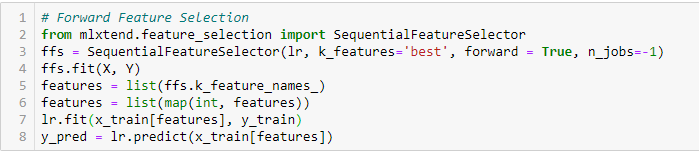
Forward Feature Selection
Dette er en iterativ metode, hvor vi starter med den bedst præsterende variabel i forhold til målet. Dernæst vælger vi en anden variabel, der giver den bedste ydeevne i kombination med den først valgte variabel. Denne proces fortsætter, indtil det forudindstillede kriterium er nået.
Backward Feature Elimination
Denne metode fungerer præcis modsat af Forward Feature Selection-metoden. Her starter vi med alle de tilgængelige funktioner og opbygger en model. Dernæst vælger vi den variabel fra modellen, som giver den bedste værdi for evalueringsmålet. Denne proces fortsættes, indtil det forudindstillede kriterium er opnået.
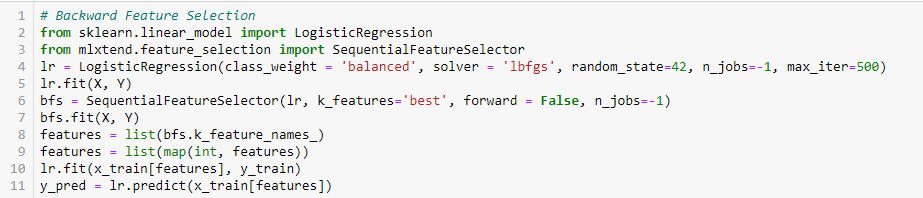
Denne metode er sammen med den ovenfor omtalte metode også kendt som Sequential Feature Selection-metoden.
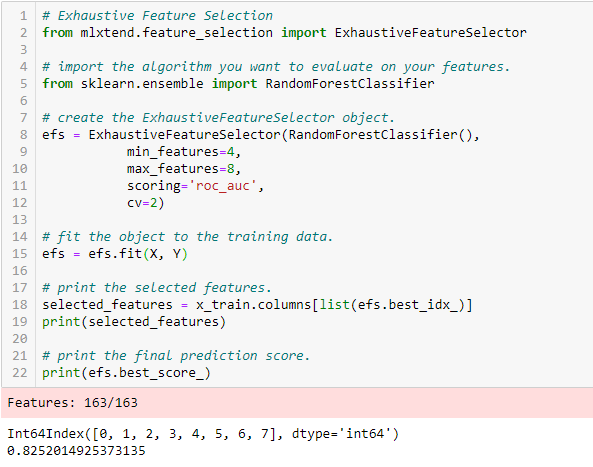
Exhaustive Feature Selection
Dette er den mest robuste featureudvælgelsesmetode, der er behandlet indtil videre. Der er tale om en brute-force-evaluering af hver delmængde af funktioner. Det betyder, at den prøver alle mulige kombinationer af variablerne og returnerer den bedst fungerende delmængde.
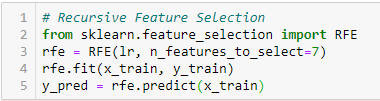
Recursiv Feature Elimination
‘Givet en ekstern estimator, der tildeler vægte til features (f.eks. koefficienterne i en lineær model), er målet med rekursiv feature elimination (RFE) at vælge features ved rekursivt at overveje mindre og mindre sæt af features. Først trænes estimatoren på det oprindelige sæt af træk, og betydningen af hvert enkelt træk fås enten gennem en coef_-attribut eller gennem en feature_importances_-attribut.
Dernæst fjernes de mindst vigtige træk fra det aktuelle sæt af træk. Denne procedure gentages rekursivt på det beskårede sæt, indtil det ønskede antal træk, der skal vælges, er nået.”
C. Indlejrede metoder:
Disse metoder omfatter fordelene ved både wrapper- og filtermetoderne, idet de omfatter interaktioner af funktioner, men også opretholder rimelige beregningsomkostninger. Indlejrede metoder er iterative i den forstand, at de tager sig af hver iteration af modeltræningsprocessen og omhyggeligt udtrækker de funktioner, der bidrager mest til træningen for en bestemt iteration.
Lad os, diskutere nogle af disse teknikker klik her:
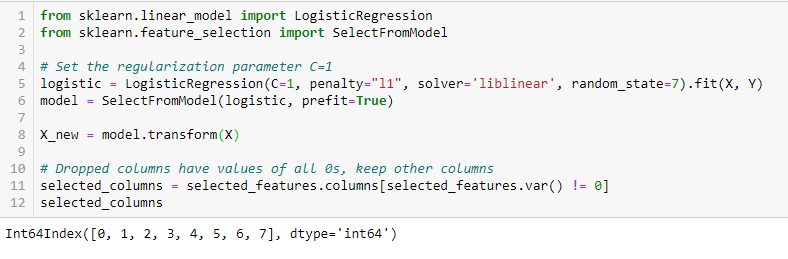
LASSO Regularization (L1)
Regularization består i at tilføje en straf til de forskellige parametre i maskinlæringsmodellen for at reducere modellens frihed, dvs. for at undgå overpasning. I regulering af lineære modeller anvendes straffen over de koefficienter, der multiplicerer hver af prædiktorerne. Af de forskellige typer regulering har Lasso eller L1 den egenskab, at den er i stand til at skrumpe nogle af koefficienterne til nul. Derfor kan denne egenskab fjernes fra modellen.
Random Forest Importance
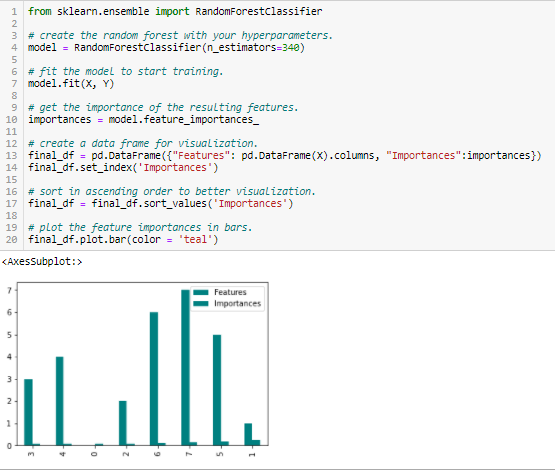
Random Forests er en slags Bagging-algoritme, der aggregerer et bestemt antal beslutningstræer. De træbaserede strategier, der anvendes af tilfældige skove, rangerer naturligvis efter, hvor godt de forbedrer knudepunktets renhed, eller med andre ord et fald i urenheden (Gini-urenhed) i forhold til alle træer. Noder med det største fald i urenhed forekommer i starten af træerne, mens noder med det mindste fald i urenhed forekommer i slutningen af træerne. Ved at beskære træer under en bestemt knude kan vi således skabe en delmængde af de vigtigste funktioner.
Slutning
Vi har diskuteret et par teknikker til udvælgelse af funktioner. Vi har med vilje forladt featureudvindingsteknikker som Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis osv. Disse metoder hjælper med at reducere dataenes dimensionalitet eller reducere antallet af variabler, samtidig med at dataenes varians bevares.
Ud over de metoder, der er diskuteret ovenfor, findes der mange andre metoder til udvælgelse af funktioner. Der findes også hybridmetoder, som anvender både filtrerings- og indpakningsteknikker. Hvis du ønsker at udforske mere om teknikker til udvælgelse af funktioner, kan du efter min mening læse “Feature Selection for Data and Pattern Recognition” af Urszula Stańczyk og Lakhmi C. Jain.