Opdateret 29-maj-2018: Formålet med denne artikel er tredelt (1) Vis, at vi altid vil have brug for en datamodel (enten udført af mennesker eller maskiner) (2) Vis, at fysisk modellering ikke er det samme som logisk modellering. Faktisk er det meget forskelligt og afhænger af den underliggende teknologi. Vi har dog brug for begge dele. Jeg illustrerede dette punkt ved hjælp af Hadoop på det fysiske lag (3) Vis, hvilken betydning begrebet uforanderlighed har for datamodellering.
- Er dimensionel modellering død?
- Hvorfor skal vi modellere vores data?
- Hvorfor har vi brug for dimensionelle modeller?
- Datamodellering vs. dimensionel modellering
- Så hvorfor hævder nogle mennesker, at dimensionel modellering er død?
- Data Warehouse er død Forvirring
- Misforståelsen om Schema on Read
- Denormalisering genbehandlet. De fysiske aspekter af modellen.
- Tag de-normalisering til sin fulde konklusion
- Datadistribution på en distribueret relationel database (MPP)
- Datadistribution på Hadoop
- Dimensionelle modeller på Hadoop
- Hadoop og langsomt skiftende dimensioner
- Storage evolution on Hadoop
- Dommen. Er dimensionelle modeller og stjerneskemaer forældede?
- Komplementær læsning om dimensionel modellering i Big Data-æraen
Er dimensionel modellering død?
Hvor jeg giver dig et svar på dette spørgsmål, så lad os tage et skridt tilbage og først se på, hvad vi forstår ved dimensionel datamodellering.
Hvorfor skal vi modellere vores data?
I modsætning til en udbredt misforståelse er det ikke det eneste formål med datamodeller at tjene som ER-diagram til at designe en fysisk database. Datamodeller repræsenterer kompleksiteten af forretningsprocesser i en virksomhed. De dokumenterer vigtige forretningsregler og koncepter og bidrager til at standardisere vigtig virksomhedsterminologi. De skaber klarhed og hjælper med at afdække uklare tankegange og tvetydigheder om forretningsprocesser. Desuden kan du bruge datamodeller til at kommunikere med andre interessenter. Du ville ikke bygge et hus eller en bro uden en tegningsplan. Så hvorfor ville du bygge en dataapplikation som f.eks. et datawarehouse uden en plan?
Hvorfor har vi brug for dimensionelle modeller?
Dimensionel modellering er en særlig tilgang til modellering af data. Vi bruger også ordene datamart eller stjerneskema som synonymer for en dimensionel model. Stjerneskemaer er optimeret til dataanalyser. Tag et kig på den dimensionelle model nedenfor. Den er ret intuitiv at forstå. Vi kan straks se, hvordan vi kan skære vores ordredata ud efter kunde, produkt eller dato og måle ydelsen af forretningsprocessen Orders ved at aggregere og sammenligne målinger.
En af de centrale idéer om dimensionel modellering er at definere det laveste granularitetsniveau i en transaktionel forretningsproces. Når vi skærer og skærer og borer i dataene, er dette det bladniveau, hvorfra vi ikke kan bore længere ned. Sagt på en anden måde er det laveste granularitetsniveau i et stjerneskema et join af fakta til alle dimensionstabeller uden nogen aggregeringer.
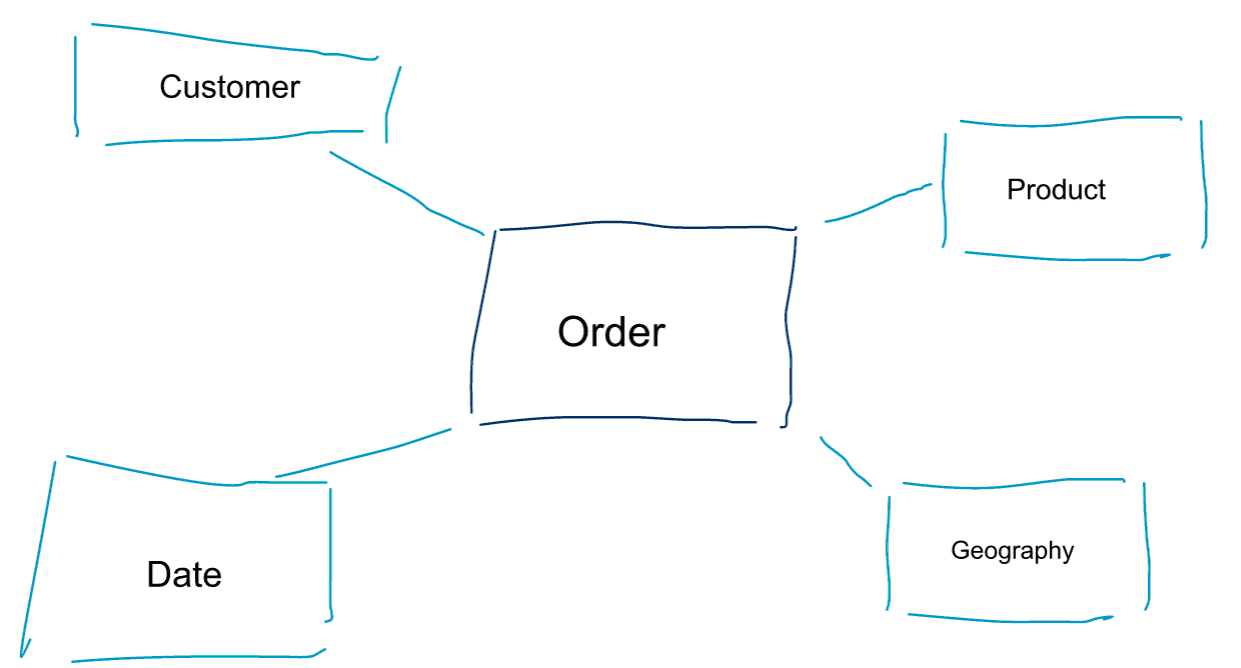
Datamodellering vs. dimensionel modellering
I standard datamodellering tilstræber vi at fjerne gentagelser og redundans i data. Når der sker en ændring i data, behøver vi kun at ændre det ét sted. Dette bidrager også til datakvaliteten. Værdierne bliver ikke ude af synkronisering flere steder. Tag et kig på nedenstående model. Den indeholder forskellige tabeller, der repræsenterer geografiske begreber. I en normaliseret model har vi en separat tabel for hver enhed. I en dimensionel model har vi kun én tabel: geografi. I denne tabel vil byer blive gentaget flere gange. En gang for hver by. Hvis landet ændrer navn, skal vi opdatere landet mange steder
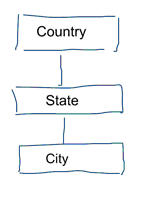
Note: Standardiseret datamodellering kaldes også for 3NF-modellering.
Den standardiserede tilgang til datamodellering er ikke egnet til formålet for Business Intelligence-arbejdsbelastninger. En masse tabeller resulterer i en masse joins. Joins gør tingene langsommere. I dataanalyser undgår vi dem så vidt muligt. I dimensionelle modeller de-normaliserer vi flere relaterede tabeller til én tabel, f.eks. kan de forskellige tabeller i vores forrige eksempel for-jointes til kun én tabel: geografi.
Så hvorfor hævder nogle mennesker, at dimensionel modellering er død?
Jeg tror, du vil være enig i, at datamodellering i almindelighed og dimensionel modellering i særdeleshed er en ganske nyttig øvelse. Så hvorfor hævder nogle mennesker, at dimensionel modellering ikke er nyttig i en tid med big data og Hadoop?
Som du kan forestille dig, er der forskellige grunde til dette.
Data Warehouse er død Forvirring
For det første forveksler nogle mennesker dimensionel modellering med data warehousing. De hævder, at data warehousing er dødt, og som følge heraf kan dimensionel modellering også henlægges til historiens skraldespand. Dette er et logisk sammenhængende argument. Men begrebet datawarehouse er langt fra forældet. Vi har altid brug for integrerede og pålidelige data til at udfylde vores BI-dashboards. Hvis du vil vide mere, kan jeg anbefale vores kursus Big Data for Data Warehouse Professionals. I kurset går jeg i detaljer og forklarer, hvordan datawarehouse er lige så relevant som nogensinde. Jeg vil også vise, hvordan nye Big Data-værktøjer og -teknologier er nyttige til data warehousing.

Misforståelsen om Schema on Read
Det andet argument, jeg ofte hører, lyder sådan her. ‘Vi følger en schema on read-tilgang og behøver ikke længere at modellere vores data’. Efter min mening er begrebet schema on read en af de største misforståelser inden for dataanalyser. Jeg er enig i, at det er nyttigt i første omgang at gemme dine rå data i et datadump, der er let på skema. Men dette argument bør ikke bruges som en undskyldning for slet ikke at modellere dine data. Schema on read-tilgangen er blot at sparke dåsen og ansvaret nedad til downstream-processer. Nogen er stadig nødt til at bide i det sure æble og definere datatyperne. Hver eneste proces, der har adgang til det skemafrie datadump, skal selv finde ud af, hvad der foregår. Denne type arbejde løber op, er fuldstændig overflødigt og kan let undgås ved at definere datatyper og et ordentligt skema.
Denormalisering genbehandlet. De fysiske aspekter af modellen.
Er der faktisk nogle gyldige argumenter for at erklære dimensionelle modeller for forældede? Der er faktisk nogle bedre argumenter end de to, jeg har nævnt ovenfor. De kræver en vis forståelse af fysisk datamodellering og af den måde, Hadoop fungerer på. Bær over med mig.
Tidligere har jeg kort nævnt en af grundene til, at vi modellerer vores data dimensionelt. Det er i forbindelse med den måde, hvorpå data lagres fysisk i vores datalager. I standard datamodellering får hver enhed i den virkelige verden sin egen tabel. Det gør vi for at undgå dataredundans og risikoen for, at datakvalitetsproblemer sniger sig ind i vores data. Jo flere tabeller, vi har, jo flere joins har vi brug for. Det er ulempen. Tabeljoins er dyre, især når vi sammenføjer et stort antal poster fra vores datasæt. Når vi modellerer data dimensionelt, konsoliderer vi flere tabeller til én. Vi siger, at vi pre-joiner eller de-normaliserer dataene. Vi har nu færre tabeller, færre joins og som følge heraf lavere latenstid og bedre forespørgselsydelse.
Deltag i diskussionen om dette indlæg på LinkedIn
Tag de-normalisering til sin fulde konklusion
Hvorfor ikke tage de-normalisering til sin fulde konklusion? Slippe af med alle joins og bare have en enkelt faktatabel? Dette ville faktisk helt fjerne behovet for alle joins. Men som du kan forestille dig, har det nogle bivirkninger. For det første øger det den nødvendige mængde lagerplads. Vi skal nu lagre en masse redundante data. Med fremkomsten af kolonnelagringsformater til dataanalyser er dette mindre problematisk i dag. Det større problem ved de-normalisering er det faktum, at hver gang en værdi af en af attributterne ændres, skal vi opdatere værdien flere steder – muligvis tusindvis eller millioner af opdateringer. En måde at komme uden om dette problem på er at genindlæse vores modeller fuldstændigt hver nat. Ofte vil dette være meget hurtigere og nemmere end at anvende et stort antal opdateringer. Kolonnedatabaser anvender typisk følgende fremgangsmåde. De gemmer først opdateringer af data i hukommelsen og skriver dem asynkront til disken.
Datadistribution på en distribueret relationel database (MPP)
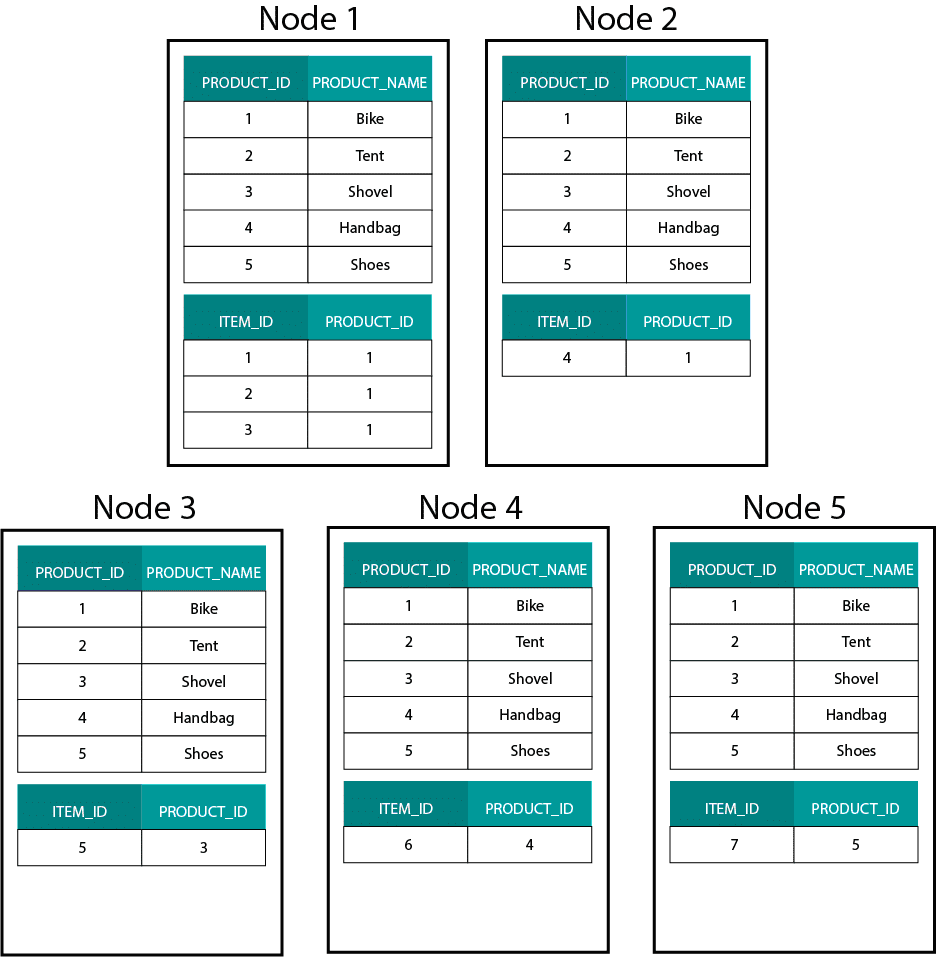
Når vi opretter dimensionelle modeller på Hadoop, f.eks. Hive, SparkSQL osv. skal vi bedre forstå en kernefunktion ved teknologien, der adskiller den fra en distribueret relationel database (MPP) såsom Teradata osv. Når vi distribuerer data på tværs af knuderne i en MPP, har vi kontrol over pladsplacering. På grundlag af vores partitioneringsstrategi, f.eks. hash, liste, rækkevidde osv. kan vi placere nøglerne til de enkelte poster på tværs af faneblade på den samme knude. Med garanteret datakolokalitet er vores sammenføjninger superhurtige, da vi ikke behøver at sende data på tværs af netværket. Tag et kig på eksemplet nedenfor. Records med samme ORDER_ID fra tabellerne ORDER og ORDER_ITEM ender på samme node.
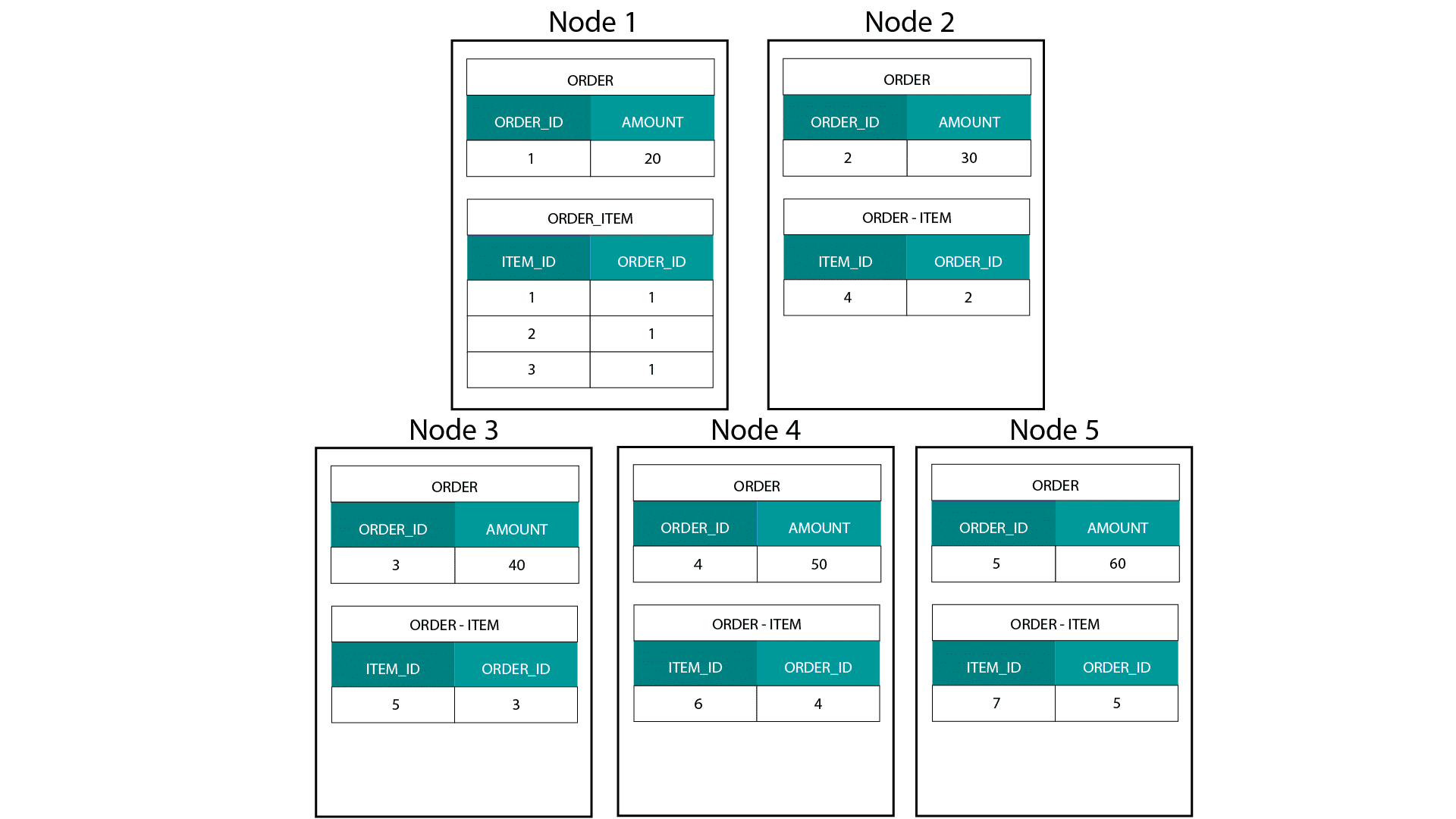
Nøgler til order_id i tabellen order og order_item er co-located på de samme noder.
Datadistribution på Hadoop
Dette er meget forskelligt fra Hadoop-baserede systemer. Der opdeler vi vores data i store stykker og distribuerer og replikerer dem på tværs af vores knudepunkter på Hadoop Distributed File System (HDFS). Med denne datadistributionsstrategi kan vi ikke garantere datakolokalitet. Tag et kig på eksemplet nedenfor. Registreringerne for ORDER_ID-nøglen ender på forskellige knudepunkter.
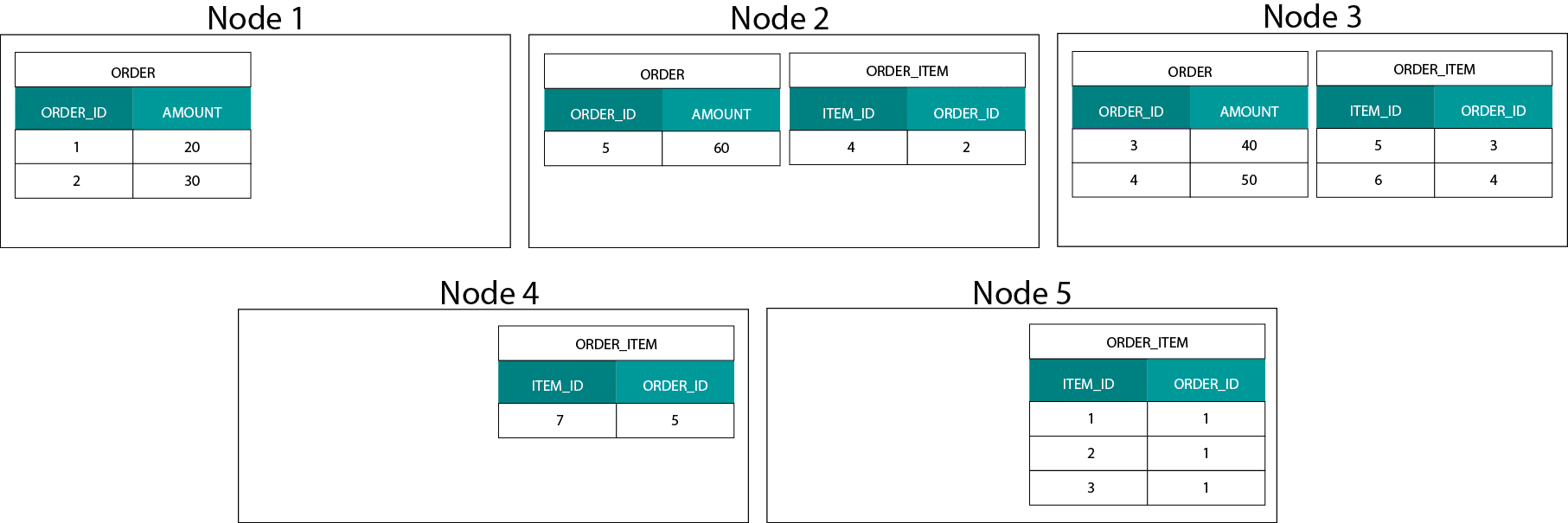
For at kunne sammenføje skal vi sende data på tværs af netværket, hvilket påvirker ydelsen.
En strategi til håndtering af dette problem er at replikere en af sammenføjningstabellerne på tværs af alle knudepunkter i klyngen. Dette kaldes en broadcast join, og vi bruger den samme strategi på en MPP. Som du kan forestille dig, fungerer det kun for små opslags- eller dimensionstabeller.
Så hvad gør vi, når vi har en stor faktatabel og en stor dimensionstabel, f.eks. kunde eller produkt? Eller faktisk når vi har to store faktatabeller.
Dimensionelle modeller på Hadoop
For at komme uden om dette præstationsproblem kan vi de-normalisere store dimensionstabeller i vores faktatabel for at garantere, at data er samlokaliseret. Vi kan udsende de mindre dimensionstabeller på tværs af alle vores knudepunkter.
For at sammenføje to store faktatabeller kan vi indlejre tabellen med den lavere granularitet inde i tabellen med den højere granularitet, f.eks. en stor ORDER_ITEM-tabel indlejret inde i ORDER-tabellen. Moderne forespørgselsmotorer som Impala eller Drill giver os mulighed for at flade disse data ud

Denne strategi med at indlejre data er også nyttig for smertefulde Kimball-koncepter som f.eks. brotabeller til at repræsentere M:N-relationer i en dimensionel model.
Hadoop og langsomt skiftende dimensioner
Lagring på Hadoop-filsystemet er uforanderlig. Med andre ord kan du kun indsætte og tilføje poster. Du kan ikke ændre data. Hvis du kommer fra en baggrund med relationelle datalagre, kan dette i første omgang virke lidt mærkeligt. Men under motorhjelmen fungerer databaser på en lignende måde. De gemmer alle ændringer af data i en uforanderlig write ahead log (kendt i Oracle som redo loggen), før en proces asynkront opdaterer dataene i datafilerne.
Hvilken betydning har uforanderlighed for vores dimensionelle modeller? Du husker måske begrebet Slowly Changing Dimensions (SCD’er) fra dit kursus i dimensionel modellering. SCD’er bevarer valgfrit historikken for ændringer af attributter. De giver os mulighed for at rapportere målinger i forhold til værdien af en attribut på et bestemt tidspunkt. Dette er dog ikke standardadfærden. Som standard opdaterer vi dimensionstabeller med de seneste værdier. Så hvad er vores muligheder på Hadoop? Husk! Vi kan ikke opdatere data. Vi kan blot gøre SCD til standardadfærd og kontrollere eventuelle ændringer. Hvis vi ønsker at køre rapporter mod de aktuelle værdier, kan vi oprette en visning oven på SCD’en, som kun henter den seneste værdi. Dette kan nemt gøres ved hjælp af windowing-funktioner. Alternativt kan vi køre en såkaldt komprimeringstjeneste, der fysisk opretter en separat version af dimensionstabellen med kun de seneste værdier.
Storage evolution on Hadoop
Disse Hadoop-begrænsninger er ikke gået ubemærket hen hos leverandørerne af Hadoop-platformene. I Hive har vi nu ACID-transaktioner og tabeller, der kan opdateres. Baseret på antallet af åbne større problemer og min egen erfaring, synes denne funktion dog ikke at være produktionsklar endnu . Cloudera har valgt en anden tilgang. Med Kudu har de skabt et nyt opdaterbart lagringsformat, der ikke ligger på HDFS, men på det lokale OS-filsystem. Det fjerner Hadoop-begrænsningerne helt og holdent og svarer til det traditionelle lagringslag i en kolonneformet MPP. Generelt set er det nok bedre at køre BI- og dashboard-brugstilfælde på en MPP, f.eks. Impala + Kudu, end på Hadoop. Når det er sagt, har MPP’er deres egne begrænsninger, når det kommer til modstandsdygtighed, samtidighed og skalerbarhed. Når du støder på disse begrænsninger, er Hadoop og dets nære fætter Spark gode muligheder for BI-arbejdsbelastninger. Vi dækker alle disse begrænsninger i vores kursus Big Data for Data Warehouse Professionals og kommer med anbefalinger om, hvornår du skal bruge et RDBMS og hvornår du skal bruge SQL på Hadoop/Spark.
Dommen. Er dimensionelle modeller og stjerneskemaer forældede?
Vi ved alle, at Ralph Kimball er gået på pension. Men hans principielle ideer og koncepter er stadig gyldige og lever videre. Vi er nødt til at tilpasse dem til nye teknologier og lagertyper, men de giver stadig værdi.
Lær mig Big Data for at fremme min karriere
Komplementær læsning om dimensionel modellering i Big Data-æraen
Tom Breur: The Past and Future of Dimensional Modeling
Edosa Odaro: 5 Radical Tips for Speedy Big Data Integration – The Anti Data Warehouse Pattern