Revideret: December 11, 2020
Taler forsøgspersonerne sandheden?
Pålideligheden af selvrapporteringsdata er en akilleshæl i survey-undersøgelser. For eksempel viste meningsmålinger, at mere end 40 procent af amerikanerne går i kirke hver uge. Ved at undersøge opgørelser over kirkegang konkluderede Hadaway og Marlar (2005) imidlertid, at det faktiske fremmøde var mindre end 22 procent. I sit grundlæggende værk “Everybody lies” fandt Seth Stephens-Davidowitz (2017) rigeligt med beviser for, at de fleste mennesker ikke gør, hvad de siger, og ikke siger, hvad de gør. For eksempel erklærede de fleste vælgere i forbindelse med meningsmålinger, at kandidatens etnicitet er uvæsentlig. Ved at tjekke søgetermer i Google fandt Sephens-Davidowitz imidlertid det modsatte.Specifikt, når Google-brugere indtastede ordet “Obama”, associerede de altid hans navn med nogle ord relateret til race.
For forskning i webbaseret undervisning kan man få data om webbrug ved at analysere brugerens adgangslog, indstille cookies eller uploade cachen. Disse muligheder kan dog have begrænset anvendelighed. For eksempel kan brugeradgangsloggen ikke spore brugere, der følger links til andre websteder. Endvidere kan cookie- eller cache-metoder give anledning til problemer med privatlivets fred. I disse situationer anvendes selvrapporterede data, der indsamles ved hjælp af undersøgelser. Dette giver anledning til et spørgsmål: Hvor nøjagtige er selvrapporterede data? Cook og Campbell (1979) har påpeget, at forsøgspersonerne (a) har en tendens til at rapportere det, som de tror, at forskeren forventer at se, eller (b) rapporterer det, som afspejler deres egne evner, viden, overbevisninger eller meninger positivt. En anden bekymring i forbindelse med sådanne data drejer sig om, hvorvidt forsøgspersoner er i stand til at huske tidligere adfærd nøjagtigt. Psykologer har advaret om, at den menneskelige hukommelse er fejlbarlig (Loftus, 2016; Schacter, 1999). Nogle gange “husker” folk begivenheder, der aldrig har fundet sted. Selv om statistiske softwarepakker er i stand til at beregne tal på op til 16-32 decimaler, er denne præcision meningsløs, hvis dataene ikke kan være nøjagtige selv på heltalsniveau. En hel del forskere har advaret forskerne om, hvordan målefejl kan lamme den statistiske analyse (Blalock, 1974) og foreslået, at god forskningspraksis kræver undersøgelse af kvaliteten af de indsamlede data (Fetter, Stowe, & Owings, 1984).
Bias og varians
Målefejl omfatter to komponenter, nemlig bias og variabel fejl.Bias er en systematisk fejl, der har en tendens til at skubbe den rapporterede score ud i den ene ekstreme ende. F.eks. er flere versioner af IQ-tests fundet at være skævvredet over for ikke-hvide. Det betyder, at sorte og latinamerikanske personer har tendens til at få lavere karakterer, uanset deres faktiske intelligens. En variabel fejl, også kendt som varians, har en tendens til at være tilfældig. Med andre ord kan de rapporterede resultater enten ligge over eller under de faktiske resultater (Salvucci, Walter, Conley, Fink, Saba, 1997).
Fundene af disse to typer målefejl har forskellige implikationer. I en undersøgelse, der sammenlignede selvrapporterede data om højde og vægt med direkte målte data (Hart & Tomazic, 1999), blev det f.eks. konstateret, at forsøgspersoner har en tendens til at overrapportere deres højde, men underrapportere deres vægt. Det er indlysende, at denne form for fejlmønster er en bias snarere end en varians. En mulig forklaring på denne bias er, at de fleste mennesker ønsker at præsentere et bedre fysisk billede over for andre. Hvis målefejlen imidlertid er tilfældig, kan forklaringen være mere kompliceret.
Man kan hævde, at variable fejl, som er tilfældige i deres natur, vil udligne hinanden og således ikke være en trussel mod undersøgelsen. For eksempel kan den første bruger overvurdere sine internetaktiviteter med 10 %, men den anden bruger kan undervurdere sine med 10 %. I dette tilfælde kan gennemsnittet stadig være korrekt. Over- og undervurderinger øger imidlertid variabiliteten i fordelingen. I mange parametriske test anvendes variabiliteten inden for en gruppe som fejltermin. En for høj variabilitet vil helt sikkert påvirke testens signifikans. Nogle tekster kan forstærke den ovennævnte misforståelse. F.eks. siger Deese (1972),
Statistisk teori fortæller os, at pålideligheden af observationer er proportional med kvadratroden af antallet af dem. Jo flere observationer der er, jo mere tilfældig påvirkning vil der være. Og statistisk teori siger, at jo flere tilfældige fejl der er, jo mere sandsynligt er det, at de ophæver hinanden og giver en normalfordeling (s.55).
For det første er det rigtigt, at når stikprøvestørrelsen øges, falder variansen i fordelingen, men det garanterer ikke, at fordelingens form nærmer sig normalitet. For det andet bør pålideligheden (datakvaliteten) være knyttet til målingen snarere end til bestemmelsen af stikprøvestørrelsen. En stor stikprøvestørrelse med mange målefejl, selv tilfældige fejl, vil puste fejlterminen for parametriske test op.
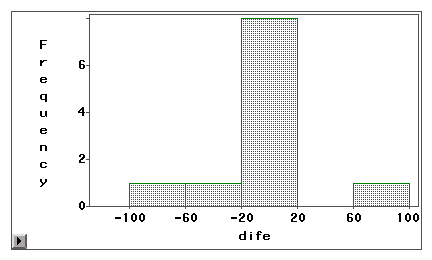
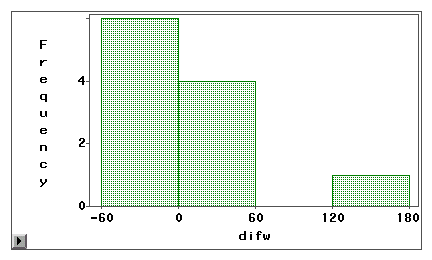
Et stamme-og-bladplot eller et histogram kan bruges til visuelt at undersøge, om en målefejl skyldes systematisk skævhed eller tilfældig varians. I det følgende eksempel er to typer internetadgang (webbrowsing og e-mail) målt ved hjælp af både selvrapporteret undersøgelse og logbog. Forskelsscorerne (måling 1 – måling 2) er plottet i de følgende histogrammer.
Den første graf afslører, at de fleste forskelscorere er centreret omkring nul. Underrapportering og overrapportering forekommer i begge ender, hvilket tyder på, at målefejlen er tilfældig fejl snarere end systematisk skævhed.
Den anden graf viser tydeligt, at der er en høj grad af målefejl, fordi meget få differencemål er centreret omkring nul. Desuden er fordelingen negativt skæv, og derfor er fejlen skævhed i stedet for varians.
Hvor pålidelig er vores hukommelse?
Schacter (1999) advarede om, at den menneskelige hukommelse er fejlbar. Der er syv fejl i vores hukommelse:
- Forgængelighed: Faldende tilgængelighed af information over tid.
- Absenthed: Uopmærksom eller overfladisk behandling, der bidrager til svage hukommelser.
- Blokering: Den midlertidige utilgængelighed af information, der er lagret i hukommelsen.
- Misattribution Tilskrivning af en erindring eller idé til den forkerte kilde.
- Suggestibilitet: Erindringer, der indplantes som følge af ledende spørgsmål eller forventninger.
- Fordomme: Retrospektive forvrængninger og ubevidste påvirkninger, der er relateret til aktuel viden og overbevisninger.
- Persistens: Patologiske erindringer – information eller begivenheder, som vi ikke kan glemme, selv om vi ville ønske, at vi kunne.
 |
“Jeg har ingen erindring om disse. Jeg kan ikke huske, at jeg underskrev dokumentet forWhitewater. Jeg kan ikke huske, hvorfor dokumentet forsvandt, men dukkede op igen senere. Jeg kan ikke huske noget.” “Jeg husker, at jeg landede (i Bosnien) under snigskyttebeskydning. Der skulle have været en slags velkomstceremoni i lufthavnen, men i stedet løb vi bare med hovedet nedad for at komme ind i køretøjerne for at komme til vores base.” Under efterforskningen af at have sendt klassificerede oplysninger via en personlig e-mail-server fortalte Clinton FBI, at hun ikke kunne “huske” eller “huske” noget 39 gange. Varsel: En ny computervirus ved navn “Clinton” er opdaget. Hvis computeren er inficeret, vil den hyppigt vise denne meddelelse om “hukommelsesmangel”, selv om den har tilstrækkelig RAM. |
| Spørgsmål: “Hvis Vernon Jordon har fortalt os, at De har en ekstraordinær hukommelse, en af de bedste hukommelser, han nogensinde har set hos en politiker, er det så noget, De vil bestride?”
A: “Jeg har en god hukommelse … Men jeg kan ikke huske, om jeg var alene med Monica Lewinsky eller ej. Hvordan skulle jeg kunne holde styr på så mange kvinder i mit liv?” Q: Hvorfor anbefalede Clinton Lewinsky til et job hos Revlon? A: Han vidste, at hun ville være god til at finde på ting. |
 |
Det er vigtigt at bemærke, at nogle gange er pålideligheden af vores hukommelse bundet til ønskværdigheden af resultatet. For eksempel, når en medicinskforsker forsøger at indsamle relevante data fra mødre, hvis babyer er sunde, og mødre, hvis børn er misdannede, er dataene fra sidstnævnte normalt mere nøjagtige end fra førstnævnte. Det skyldes, at mødre til misdannede børn omhyggeligt har gennemgået alle sygdomme, der er opstået under graviditeten, alle lægemidler, der er taget, og alle detaljer, der er direkte eller fjernt forbundet med tragedien, i et forsøg på at finde en forklaring. Mødre til raske spædbørn er derimod ikke særlig opmærksomme på de forudgående oplysninger (Aschengrau & SeageIII, 2008). Opblæsning af GPA er et andet eksempel på, hvordan desirabilitet påvirker hukommelsens nøjagtighed og dataintegritet. I nogle situationer er der en kønsforskel i GPA-inflation. En undersøgelse foretaget af Caskie etal. (2014) fandt ud af, at inden for gruppen af studerende med et lavere GPA på kandidatniveau var kvinder mere tilbøjelige til at rapportere et højere GPA end det faktiske GPA end mænd.
For at modvirke problemet med hukommelsesfejl foreslog nogle forskere at indsamle data vedrørende deltagerens øjeblikkelige tanke eller følelse i stedet for at bede ham eller hende om at huske fjerne begivenheder (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Følgende eksempler er undersøgelsesemner i 2018 Programme forInternational Student Assessment: “Blev du behandlet med respekt hele dagen i går?” “Smilede eller grinede du meget i går?” “Lærte du eller gjorde du noget interessant i går?” (Organisationen for Økonomisk Samarbejde og Udvikling, 2017). Svaret afhænger dog af, hvad der skete for deltageren omkring det pågældende øjeblik, hvilket måske ikke er typisk. Specifikt, selv om respondenten ikke smilede eller grinede meget i går, betyder det ikke nødvendigvis, at respondenten altid er ulykkelig.
Hvad skal vi gøre?
Nogle forskere afviser brugen af selvrapporterede data på grund af deres påståede dårlige kvalitet. Da en gruppe forskere f.eks. undersøgte, om høj religiøsitet førte til mindre overholdelse af shelter-in-placed-direktiver i USA under COVID19-pandemien, brugte de antallet af menigheder pr. 10.000 indbyggere som et proxy-mål for regionens religiøsitet i stedet for selvrapporteret religiøsitet, som har en tendens til at afspejle social ønskværdighed (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Chan (2009) fremførte imidlertid, at den såkaldte dårlige kvalitet af selvrapporterede data ikke er andet end en urban legende. Drevet af social ønskværdighed kan respondenterne give forskerne unøjagtige data ved nogle lejligheder, men det sker ikke hele tiden. Det er f.eks. usandsynligt, at respondenterne ville lyve om deres demografiske oplysninger, f.eks. køn og etnicitet. For det andet er det rigtigt, at respondenterne har en tendens til at forfalske deres svar i eksperimentelle undersøgelser, men dette problem er mindre alvorligt i forbindelse med foranstaltninger, der anvendes i feltundersøgelser og naturalistiske omgivelser. Desuden findes der mange veletablerede selvrapporterede målinger af forskellige psykologiske konstruktioner, som har opnået beviser for konstruktvaliditet gennem både konvergent og diskriminant validering. For eksempel Big-five personlighedstræk, proaktiv personlighed, affektivitetsdisposition, self-efficacy, målorienteringer, opfattet organisatorisk støtte og mange andre.På epidemiologiområdet hævdede Khoury, James og Erickson (1994), at effekten af recall bias er overvurderet. Men deres konklusion kan måske ikke anvendes godt på andre områder, såsom uddannelse og psykologi. på trods af truslen om ukorrekthed i dataene er det umuligt for forskeren at følge alle forsøgspersoner med et videokamera og optage alt, hvad de gør. Ikke desto mindre kan forskeren bruge en delmængde af forsøgspersoner til at indhente observerede data som f.eks. brugerlogbogadgang eller daglig logbog over webadgang på papir. Resultaterne vil derefter blive sammenlignet med resultatet af alle forsøgspersonernes selvrapporterede data med henblik på en vurdering af målefejl.F.eks.
- Når forskeren har adgang til brugeradgangsloggen, kan han bede forsøgspersonerne om at rapportere hyppigheden af deres adgang til webserveren.Forsøgspersonerne bør ikke informeres om, at deres internetaktiviteter er blevet logget af webmasteren, da dette kan påvirke deltagernes adfærd.
- Forskeren kan bede en delmængde af brugerne om at føre en logbog over deres internetaktiviteter i en måned. Herefter bliver de sammebrugere bedt om at udfylde en undersøgelse om deres internetbrug.
Nogen vil måske hævde, at logbogsmetoden er for krævende. I mange videnskabelige forskningsundersøgelser bliver forsøgspersoner faktisk bedt om meget mere end det. Da forskerne f.eks. undersøgte, hvordan dyb søvn under langvarige rumrejser ville påvirke menneskers helbred, blev deltagerne bedt om at ligge i sengen i en måned. I en undersøgelse af, hvordan et lukket miljø påvirker menneskets psykologi under en rumrejse, blev forsøgspersonerne også lukket inde i et rum hver for sig i en måned. Det er dyrt at søge efter videnskabelige sandheder.
Når forskellige datakilder er indsamlet, kan uoverensstemmelsen mellem logbogen og de selvrapporterede data analyseres for at vurdere dataenes pålidelighed. Ved første øjekast ligner denne fremgangsmåde en test-retestreliabilitet, men det er det ikke. For det første skal det instrument, der anvendes i to eller flere situationer, være det samme i test-retest- reliabilitet. For det andet, når test-retest- pålideligheden er lav, er fejlkilderne inden for instrumentet. Men når fejlkilden er ekstern i forhold til instrumentet, f.eks. menneskelige fejl, er inter-rater reliabilitet mere hensigtsmæssig.
Den ovenfor foreslåede procedure kan opfattes som en måling af inter-data reliabilitet, som ligner den for inter-rater reliabilitet og gentagne målinger. Der er fire måder at estimere inter-raterreliabiliteten på, nemlig Kappa-koefficienten, indeks for inkonsekvens, ANOVA med gentagne foranstaltninger og regressionsanalyse. I det følgende afsnit beskrives det, hvordan disse målinger af pålidelighed mellem bedømmere kan anvendes som målinger af pålidelighed mellem data.
Kappa-koefficient
I psykologisk og uddannelsesmæssig forskning er det ikke usædvanligt at anvende to eller flere bedømmere i målingsprocessen, når vurderingen omfatter subjektive vurderinger (f.eks. bedømmelse af essays). Interbedømmernes pålidelighed, som måles ved hjælp af Kappa-koefficienten, anvendes til at angive pålideligheden af dataene.F.eks. bedømmes deltagernes præstationer af to eller flere bedømmere som “mester” eller “ikke-mester” (1 eller 0). Derfor beregnes denne måling normalt i kategoriske dataanalyseprocedurer såsom PROC FREQ i SAS, “måling af overensstemmelse” i SPSS eller en online Kappa-beregner (Lowry, 2016). Billedet nedenfor er et skærmbillede af Vassarstats online beregner.
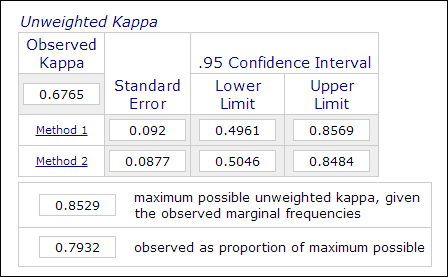
Det er vigtigt at bemærke, at selv om 60 procent af to datasæt stemmer overens med hinanden, betyder det ikke, at målingerne er pålidelige.Da resultatet er dikotomt, er der en 50 procents chance for, at de to målinger stemmer overens. Kappa-koefficienten tager højde for dette og kræver en højere grad af overensstemmelse for at opnå konsistens.
I forbindelse med webbaseret undervisning kan hver kategori af selvrapporteret brug af websteder omkodes som en binær variabel. Når spørgsmål 1 f.eks. lyder “Hvor ofte bruger du telnet?”, er de mulige kategoriske svar “a: dagligt”, “b: tre til fem gange om ugen”, “c: tre-fem gange om måneden”, “d: sjældent” og “e: aldrig”. I dette tilfælde kan de fem kategorier omkodes til fem variabler: Q1A, Q1B, Q1C, Q1C, Q1D og Q1E. Derefter kan alle disse binære variabler tilføjes til en R X 2-tabel som vist i nedenstående tabel. med denne datastruktur kan svarene kodes som “1” eller “0”, og det er således muligt at måle klassifikationsoverensstemmelsen. Overensstemmelsen kan beregnes ved hjælp af Kappa-koefficienten, og derved kan pålideligheden af dataene vurderes.
Subjekter Logbogsdata Selv-rapportdata Subjekt 1 1 1 1 Subjekt 2 0 0 0 Subjekt 3 1 0 0 Subjekt 4 0 1 Indeks for uoverensstemmelse
En anden måde at beregne de ovennævnte kategoriske data på er indeks for uoverensstemmelse (IOI). Da der i ovenstående eksempel er to målinger (log- og selvrapporterede data) og fem svarmuligheder i svaret, dannes der en 4 X 4 tabel. Det første skridt til beregning af IOI består i at opdele RXC-tabellen i flere 2X2-undertabeller. F.eks. behandles den sidste mulighed “aldrig” som én kategori, og alle de øvrige behandles i en anden kategori som “ikke aldrig”, som vist i følgende tabel.
Selv-indberettede data Log Jeg aldrig Ikke aldrig Total Jeg aldrig a b a+b Nej aldrig c d c+d Total a+c b+d n=Sum(a-d) Den procentvise andel af IOI beregnes ved hjælp af følgende formel:
IOI% = 100*(b+c)/ hvor p = (a+c)/n
Når IOI er beregnet for hver 2X2-undertabel, anvendes et gennemsnit af alle indeksene som en indikator for foranstaltningens inkonsekvens. Kriteriet til at bedømme, om dataene er konsistente, er følgende:
- En IOI på under 20 er lav varians
- En IOI mellem 20 og 50 er moderat varians
- En IOI over 50 er høj varians
Den pålidelighed af dataene udtrykkes i denne ligning: r = 1 – IOI
Intraklassekorrelationskoefficient
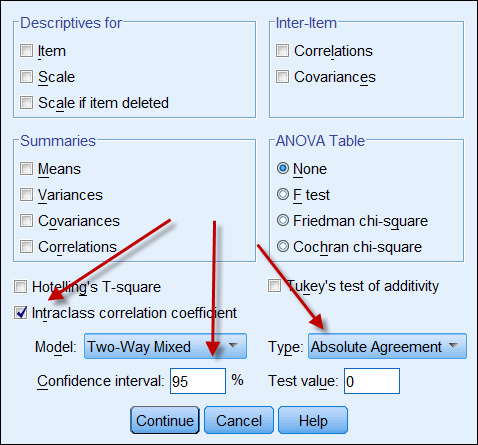
Hvis begge datakilder giver kontinuerlige data, kan man beregne intraklassekorrelationskoefficienten for at angive pålideligheden af dataene. Følgende er et skærmbillede af SPSS’ ICC-muligheder. I Typedet er der to muligheder: “konsistens” og “absolut overensstemmelse”. Hvis “konsistens” vælges, vil selv om det ene sæt tal er af høj konsistens (f.eks. 9, 8, 9, 9, 8, 8, 7…) og det andet er af lav konsistens (f.eks. 4, 3, 4, 3, 3, 2…), vil deres stærke korrelation fejlagtigt antyde, at dataene er i overensstemmelse med hinanden. Det er derfor tilrådeligt at vælge “absolut overensstemmelse”.
Repeated measures
Målingen af pålideligheden mellem data kan også konceptualiseres og proceduretaliseres som enANOVA med gentagne foranstaltninger. I en ANOVA med gentagne foranstaltninger gives målinger til de samme forsøgspersoner flere gange, f.eks. prætest, midtvejstest og posttest. I denne sammenhæng måles forsøgspersonerne også gentagne gange ved hjælp af webbrugerloggen, logbogen og den selvrapporterede undersøgelse. Følgende er SAS-koden for en ANOVA med gentagne foranstaltninger:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
I ovenstående program registreres antallet af besøgte websteder af ni frivillige i brugeradgangsloggen, i den personlige logbog og i den selvrapporterede undersøgelse. Brugerne behandles som en mellem-subjekt-faktor, mens de tre foranstaltninger betragtes som en mellem-målefaktor. Følgende er et kondenseret output:
Source of variation DF Mean Square Between-subject (user) 8 10442.50 Mellem-mål (tid) 2 488.93 Residual 16 454.80 Med udgangspunkt i ovenstående oplysninger kan pålidelighedskoefficienten beregnes ved hjælp af denne formel (Fisher, 1946; Horst, 1949):
r = MSbetween-measure – MSresidual ————————————————————– MSbetween-måling + (dfbetween-people X MSresidual) Lad os sætte tallet ind i formlen:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) Sikkerheden er ca. 0,0008, hvilket er ekstremt lavt. Derfor kan vi gå hjem og glemme alt om dataene. Heldigvis er det kun et hypotetisk datasæt. Men hvad nu, hvis det er et reelt datasæt? Man må være hård nok til at opgive dårlige data i stedet for at offentliggøre nogle resultater, der er helt upålidelige.
Korrelations- og regressionsanalyse
Korrelationsanalyse, som anvender Pearsons produktmomentkoefficient, er meget enkel og især nyttig, når skalaerne for to målinger ikke er de samme. F.eks. kan webserverloggen spore antallet af sidetilgange, mens de selvrapporterede data er på en liste-skala (f.eks.: “Hvor ofte surfer du på internettet? 5 = meget ofte, 4 = ofte, 3 = sommetider, 2 = sjældent, 5 = aldrig). I dette tilfælde kan de selvrapporterede resultater bruges som en prædiktor til at regressere mod sideadgang.
En lignende fremgangsmåde er regressionsanalyse, hvor et sæt scorer (f.eks. undersøgelsesdata) behandles som en prædiktor, mens et andet sæt scorer (f.eks. brugerens daglige logbog) betragtes som den afhængige variabel. Hvis der anvendes mere end to målinger, kan der anvendes en multipel regressionsmodel, dvs. at den, der giver det mest nøjagtige resultat (f.eks. logbog for webbrugeradgang), betragtes som den afhængige variabel, og alle andre målinger (f.eks. daglig brugerlogbog, undersøgelsesdata) behandles som uafhængige variabler.
Reference
- Aschengrau, A., & Seage III, G. (2008). Essentials of epidemiology in public health. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) Measurement in the social sciences: Theories and strategies. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Nøjagtighed af selvrapporteret college GPA: Kønsmodereredeforskelle efter præstationsniveau og akademisk self-efficacy. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Så hvorfor spørge mig? Er selvrapporteringsdata virkelig så dårlige? I Charles E. Lance og Robert J. Vandenberg (Eds.), Statistical and methodological myths and urban legends: Doktrin, sandhed og fabler i organisations- og samfundsvidenskab (pp309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-eksperimentering: Design og analyseproblemer. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validitet og pålidelighed af erfarings-samplingmetoden. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). Psykologi som videnskab og kunst. New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, August 10). Religion og reaktance over for COVID-19mitigationsretningslinjer. American Psychologist. Forudgående onlinepublikation. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). High School and Beyond. A national longitudinal study for the 1980s, quality of responses of high school students to questionnaire items. (NCES 84-216).Washington, D. C.: U.S. Department of Education. Office of EducationalResearch and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). Den inkrementelle validitet af gennemsnitlige statslige selvrapporter over globale selvrapporter af personlighed. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statistical methods for research workers (10th ed.). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). Hvor mangeAmerikanere deltager i gudstjenester hver uge? En alternativ tilgang til måling? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 august). Sammenligning af percentilfordelinger for antropometriske mål mellem tre datasæt. Paper præsenteret på det årlige fælles statistiske møde, Baltimore, MD.
- Horst, P. (1949). Et generaliseret udtryk for pålideligheden af mål. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). Om brugen af berørte kontrolpersoner til at afhjælpe bias i case-kontrolundersøgelser af fødselsdefekter. Teratology, 49, 273-281.
- Loftus, E. (2016, april). Fiktion af hukommelse. Paper præsenteret på Western Psychological Association Convention. Long Beach, CA.
- Lowry, R. (2016). Kappa som et mål for overensstemmelse ved kategorisk sortering. Hentet fra http://vassarstats.net/kappa.html
- Organisation for Økonomisk Samarbejde og Udvikling. (2017). Spørgeskema om trivsel til PISA 2018. Paris: Forfatter. Hentet fra https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). Hukommelsens syv synder: Indsigt fra psykologi og kognitiv neurovidenskab. American Psychology, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Undersøgelser af målefejl i det nationale center for uddannelsesstatistik. Washington D. C.: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Everybody lies: Big data, nye data, og hvad internettet kan fortælle os om, hvem vi virkelig er. New York, NY: Dey Street Books.
 Gå op til hovedmenuen
Gå op til hovedmenuen Andre kurserSøgemaskine

Kontakt mig
|