Metode 1, dårlig: ORDER BY NEWID()
Nemt at skrive, men det fungerer som varmt, varmt skrald, fordi det scanner hele det clusterede indeks og beregner NEWID() på hver række:
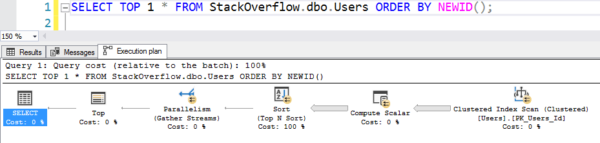
Planen med scanningen
Det tog 6 sekunder på min maskine, der gik parallelt på tværs af flere tråde, og brugte titusindvis af sekunder af CPU til al den beregning og sortering. (Og tabellen Users er ikke engang på 1 GB.)
Metode 2, bedre, men underlig: TABLESAMPLE
Denne kom ud i 2005 og har et væld af problemer. Det er ligesom at vælge en tilfældig side, og derefter returnere en masse rækker fra denne side. Den første række er lidt tilfældig, men resten er det ikke.
Transact-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
Planen ser ud som om den laver en bordscanning, men den laver kun 7 logiske læsninger:
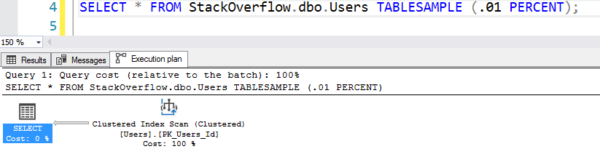
Planen med den falske scanning
Men her er resultaterne – du kan se, at den hopper til en tilfældig 8K-side og begynder derefter at læse rækker i rækkefølge. Det er ikke rigtig tilfældige rækker.
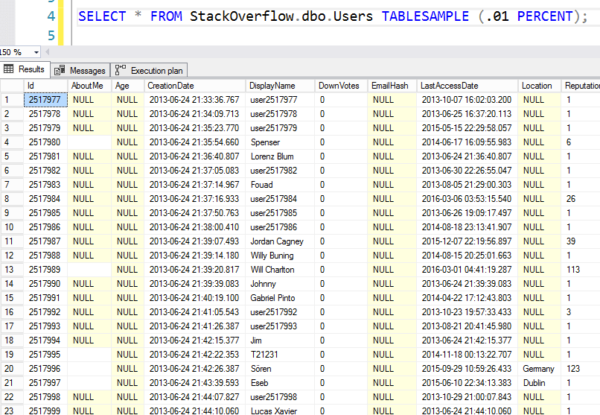
Udsædvanlige som mafia-lotteri numre
Du kan bruge ROWS sample size i stedet, men det giver nogle ret mærkelige resultater. For eksempel, i tabellen Stack Overflow Users, da jeg sagde TABLESAMPLE (50 ROWS), fik jeg faktisk 75 rækker tilbage. Det skyldes, at SQL Server konverterer din række-størrelse til en procentdel i stedet.
Metode 3, bedst, men kræver kode: Random Primary Key
Hent det øverste ID-felt i tabellen, generer et tilfældigt tal, og kig efter dette ID. Her sorterer vi efter ID’et, fordi vi vil finde den øverste post, der faktisk findes (hvorimod et tilfældigt tal måske er blevet slettet).) Ret hurtigt, men er kun godt for en enkelt tilfældig række. Hvis du ville have 10 rækker, skulle du kalde kode som denne 10 gange (eller generere 10 tilfældige tal og bruge en IN-klausul.)
Udførelsesplanen viser en clustered index scan, men den tager kun én række – vi taler kun om 6 logiske læsninger for alt det, du ser her, og den afsluttes næsten øjeblikkeligt:

Den plan, der kan
Der er en enkelt hage: Hvis Id’et har negative tal, virker det ikke som forventet. (Lad os f.eks. sige, at du starter dit identitetsfelt ved -1 og træder -1 og går hele tiden nedad, ligesom min moral.)
Metode 4, OFFSET-FETCH (2012+)
Daniel Hutmacher tilføjede denne i kommentarerne:
Og sagde: “Men den fungerer kun korrekt med et clusteret indeks. Jeg gætter på, at det er fordi den vil scanne efter (@rows) rækker i en bunke i stedet for at lave en indekssøgning.”
Bonus Track #1: Se os diskutere dette
Har du nogensinde spekuleret på, hvordan det er at være i vores virksomheds chatrum? Denne 10-minutters Slack-diskussion vil give dig en ret god idé:
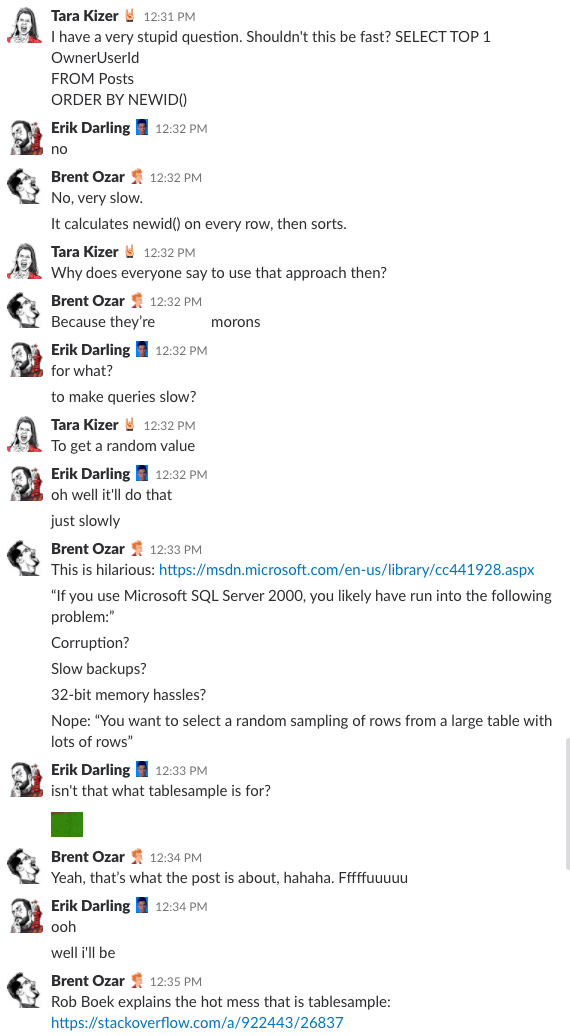
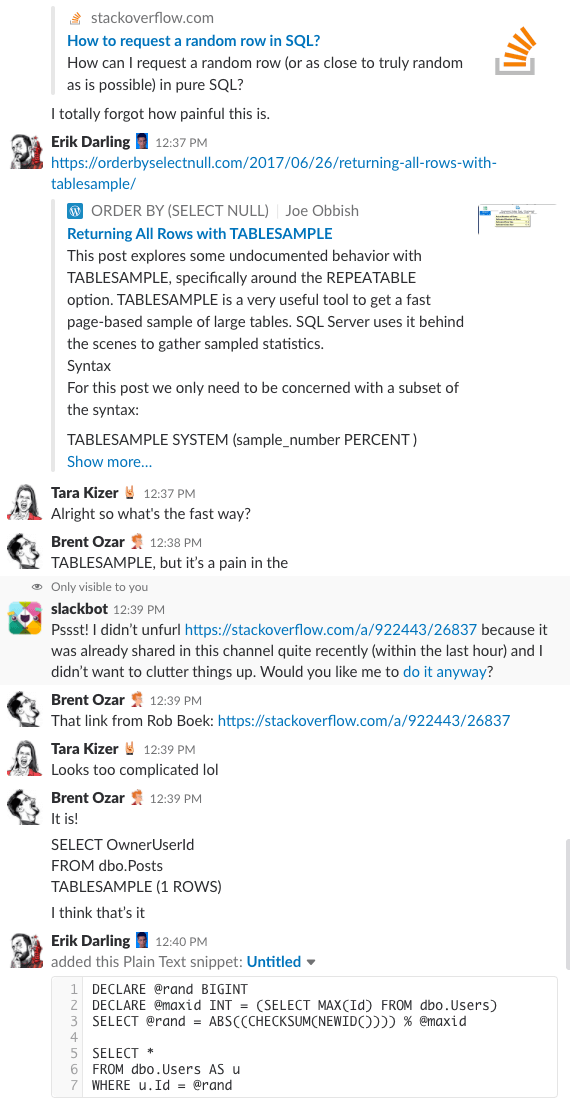
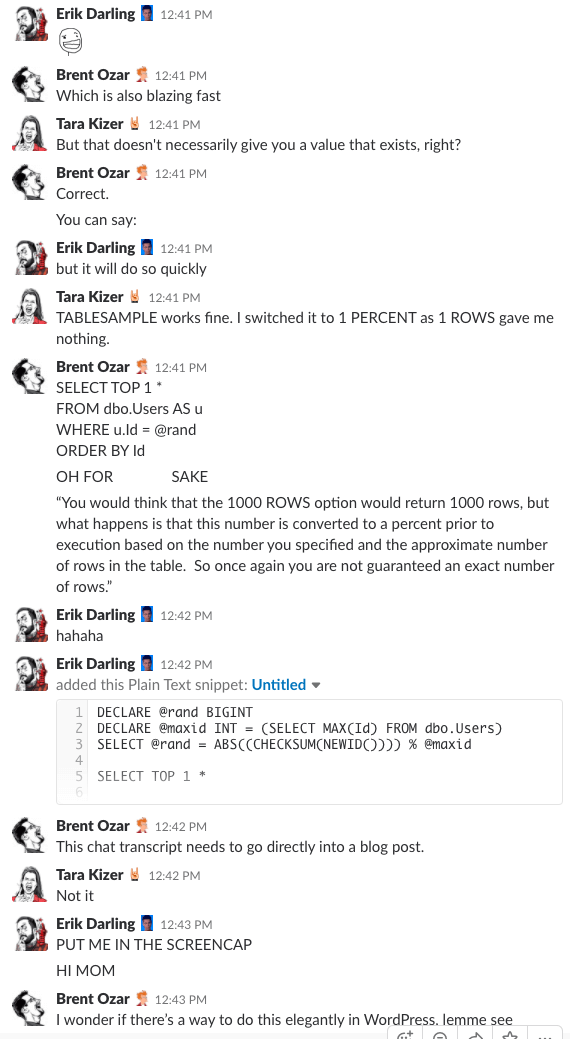
Spoiler-alarm: Det var der ikke. Jeg tog bare screenshots.
Bonus Track #2: Mitch Wheat Digs Deeper
Vil du have en dybdegående analyse af tilfældigheden i flere forskellige teknikker? Mitch Wheat dykker virkelig dybt, komplet med grafer!