Det ovenstående billede har måske givet dig en idé om, hvad dette indlæg handler om.
Dette indlæg dækker nogle af de vigtige fuzzy(ikke nøjagtigt lige, men klumper de samme strenge, siger RajKumar & Raj Kumar) strengmatchningsalgoritmer, som omfatter:
Hamming Distance
Levenstein Distance
Damerau Levenstein Distance
N-Gram baseret string matching
BK Tree
Bitap algoritme
Men vi bør først vide, hvorfor fuzzy matching er vigtigt i betragtning af et virkeligt scenarie. Når en bruger får lov til at indtaste data, kan det gå rigtig galt som i nedenstående tilfælde!
Lad,
- Dit navn er ‘Saurav Kumar Agarwal’.
- Du har fået et bibliotekskort (med et unikt ID naturligvis), som er gyldigt for alle medlemmer af din familie.
- Du går på et bibliotek for at udlevere nogle bøger hver uge. Men for at gøre dette skal du først foretage en registrering i et register ved bibliotekets indgang, hvor du indtaster dit ID & navn.
Nu beslutter biblioteksmyndighederne at analysere data i dette biblioteksregister for at få en idé om unikke læsere, der besøger hver måned. Nu kan dette gøres af mange grunde (f.eks. om man skal gå til udvidelse af arealet eller ej, om antallet af bøger skal øges osv.).
De planlagde at gøre dette ved at tælle (unikke navne, biblioteks-ID) par, der er registreret i en måned. Så hvis vi har
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Dette skulle give os 4 unikke læsere.
Så langt så godt
De anslog dette antal til at ligge på omkring 10k-10.5k, men tallene steg til ~50k efter analyse ved hjælp af nøjagtig string matching af navne.
wooohhh!!
Smuk skøn må jeg sige!!
Og de overså et trick her?
Efter en dybere analyse dukkede der et stort problem op. Husk dit navn, “Saurav Agarwal”. De fandt nogle poster, der førte til 5 forskellige brugere på tværs af dit familiebiblioteks-ID:
- Saurav K Aggrawal (bemærk det dobbelte ‘g’, ‘ra-ar’, Kumar bliver til K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Der findes nogle tvetydigheder, da biblioteksmyndighederne ikke ved
- Hvor mange personer besøger biblioteket fra din familie? om disse 5 navne repræsenterer en enkelt læser, 2 eller 3 forskellige læsere. Kald det et uovervåget problem, hvor vi har en streng, der repræsenterer ikke-standardiserede navne, men deres standardiserede navne er ikke kendt (f.eks. Saurav Agarwal: Saurav Kumar Agarwal er ikke kendt)
- Bør de alle slås sammen til “Saurav Kumar Agarwal”? Det kan jeg ikke sige, da SK Agarwal kan være Shivam Kumar Agarwal (f.eks. din fars navn). Desuden kan den eneste Agarwal være hvem som helst fra familien.
De sidste 2 tilfælde (SK Agarwal & Agarwal) ville kræve nogle ekstra oplysninger (som køn, fødselsdato, udstedte bøger), som vil blive indlæst i en eller anden ML-algoritme for at bestemme læserens faktiske navn & bør lades tilbage for nu. Men en ting jeg er ret sikker på er, at de 1. 3 navne repræsenterer den samme person & Jeg bør ikke have brug for ekstra oplysninger for at flette dem til en enkelt læser, dvs. ‘Saurav Kumar Agarwal’.
Hvordan dette kan gøres?
Her kommer fuzz string matching, hvilket betyder et næsten nøjagtigt match mellem strenge, der er lidt forskellige fra hinanden (hovedsagelig på grund af forkerte stavemåder) som ‘Agarwal’ & ‘Aggarwal’ & ‘Aggarwal’ & ‘Aggrawal’. Hvis vi får en streng med en acceptabel fejlprocent (f.eks. et bogstav forkert ), vil vi betragte den som et match. Så lad os undersøge →
Hamming-afstanden er den mest oplagte afstand beregnet mellem to strenge af samme længde, som giver en optælling af tegn, der ikke matcher svarende til et givet indeks. For eksempel: ‘Bat’ & ‘Bet’ har hamming afstand 1 som ved indeks 1, ‘a’ er ikke lig med ‘e’
Levenstein Distance/ Edit Distance
Men jeg går ud fra, at du er fortrolig med Levenstein afstand & Rekursion. Hvis ikke, skal du læse dette. Nedenstående forklaring er mere en sammenfattet version af Levensteins afstand.
Lad ‘x’=længde(Str1) & ‘y’=længde(Str2) for hele dette indlæg.
Levenstein Distance beregner det mindste antal redigeringer, der kræves for at konvertere ‘Str1’ til ‘Str2’ ved at udføre enten Tilføjelse, Fjernelse eller Udskiftning af tegn. Derfor har ‘Cat’ & ‘Bat’ en redigeringsafstand på ‘1’ (Udskift ‘C’ med ‘B’), mens den for ‘Ceat’ & ‘Bat’ ville være 2 (Udskift ‘C’ til ‘B’; Slet ‘e’).
Hvis vi taler om algoritmen, har den hovedsageligt 5 trin
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
Det vi gør er at begynde at læse strenge fra det 1. tegn
- Hvis tegnet ved indeks ‘x’ i str1 passer med tegnet ved indeks ‘y’ i str2, ingen redigering nødvendig & beregn redigeringsafstanden ved at kalde
LevensteinDistance(str1,str2)
- Hvis de ikke stemmer overens, ved vi, at en redigering er nødvendig. Så vi tilføjer +1 til den aktuelle edit_distance & beregner rekursivt edit_distance for 3 betingelser & tager det mindste ud af de tre:
Levenstein(str1,str2) →indsættelse i str2.
Levenstein(str1,str2) →udslettelse i str2
Levenstein(str1,str2)→erstatning i str2
- Hvis en af strengene løber tør for tegn under rekursion, tilføjes længden af de resterende tegn i den anden streng til redigeringsafstanden (de to første if-udsagn)
Demerau-Levenstein-afstanden
Opmærksom ‘abcd’ & ‘acbd’. Hvis vi går efter Levenstein Distance, ville det være (replace ‘b’-‘c’ & ‘c’-‘b’ at index positions 2 & 3 in str2) Men hvis man ser nærmere efter, blev begge tegn byttet om som i str1 & hvis vi indfører en ny operation ‘Swap’ ved siden af ‘addition’, ‘ deletion’ & ‘replace’, kan dette problem løses. Denne indførelse kan hjælpe os med at løse problemer som ‘Agarwal’ & ‘Agrawal’.
Denne operation tilføjes ved nedenstående pseudokode
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Lad os køre ovenstående operation for ‘abcd’ & ‘acbd’ hvor antager
initial_x=1 & initial_y=1 (Start af indeksering fra 1 & ikke fra 0 for begge strenge).
aktuel x=3 & y=3 derfor str1 & str2 ved henholdsvis ‘c’ (abcd) & ‘b’ (acbd).
Overste grænser inkluderet i den nedenfor nævnte skiveskæring. Derfor vil “qwerty” betyde “qwer”.
- last_matching_index_y vil være det sidste_indeks i str2, der passer til str1, dvs. 2, da “c” i “acbd” (indeks 2)passer til “c” i “abcd”.
- last_matching_index_x vil være det sidste_indeks i str1, der passer til str2 i.e 2 som “b” i “abcd” (indeks 2)matchede med “b” i “acbd”.
- Som følge af ovenstående pseudokode vil DemarauLevenstein(‘abc’,’acb’)=
1+(4-3-1) + (4-3-1)+ (4-3-1)+LevensteinDistance(‘a’,’a’)=1+0+0+0+0=1. Dette ville have været 2, hvis vi havde fulgt Levenstein Distance
N-Gram
N-gram er dybest set ikke andet end et sæt værdier, der genereres fra en streng ved at parre sekventielt forekommende ‘n’ tegn/ord. For eksempel: n-gram med n=2 for ‘abcd’ vil være ‘ab’,’bc’,’cd’.
Nu kan disse n-grammer genereres for strenge, hvis lighed skal måles & Der kan anvendes forskellige målemetoder til at måle ligheden.
Lad ‘abcd’ & ‘acbd’ være 2 strenge, der skal matches.
n-grammer med n=2 for
‘abcd’=ab,bc,cd
‘acbd’=ac,cb,bd
Komponentmatch (qgrammer)
Tal n-grammer, der matcher nøjagtigt for de to strenge. Her ville det være 0
Cosine Similarity
Beregning af prikproduktet efter konvertering af n-grammer genereret for strenge til vektorer
Komponentmatch (ingen rækkefølge taget i betragtning)
Matching af n-grammernes komponenter uden hensyntagen til rækkefølgen af elementerne i dvs. bc=cb.
Der findes mange andre sådanne metrikker som Jaccard-afstand, Tversky-indeks osv., som ikke er blevet diskuteret her.
BK Tree
BK tree er blandt de hurtigste algoritmer til at finde frem til lignende strenge (fra en pulje af strenge) for en given streng. BK tree bruger en
- Levenstein Distance
- Triangle inequality (vil dække dette ved slutningen af dette afsnit)
til at finde frem til lignende strenge(& ikke bare én bedste streng).
Et BK tree oprettes ved hjælp af en pulje af ord fra en tilgængelig ordbog. Lad os sige, at vi har en ordbog D={Book, Books, Cake, Cake, Boo, Boon, Cook, Cape, Cart}
Et BK-træ oprettes ved at
- Vælg en rodknude (kan være et hvilket som helst ord). Lad det være ‘Books’
- Gå igennem hvert ord W i ordbogen D, beregn dets Levenstein-afstand til rodknuden, og gør ordet W til rodknudens barn, hvis der ikke findes noget barn med samme Levenstein-afstand til forælderen. Indsættelse af Bøger & Kage.
Levenstein(Bøger,Bog)=1 & Levenstein(Bøger,Kage)=4. Da der ikke er fundet noget barn med samme afstand for “Book”, skal du lave dem til nye børn for roden.
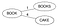
- Hvis der findes et barn med samme Levenstein-afstand for forældrene P, så betragt nu dette barn som en forælder P1 for ordet W, beregn Levenstein(forælder, ord), og hvis der ikke findes noget barn med samme afstand til forælderen P1, så gør ordet W til et nyt barn til P1, ellers fortsætter du nedad i træet.
Overvej at indsætte Boo. Levenstein(Book, Boo)=1, men der findes allerede et barn med samme dvs. Books. Beregn derfor nu Levenstein(Books, Boo)=2. Da der ikke findes noget barn med samme afstand til Books, skal Boo gøres til barn af Books.

Sådan, indsætte alle ord fra ordbogen i BK-træet

Når BK-træet er forberedt, skal vi for at søge lignende ord for et givet ord (forespørgselsord) indstille en tolerance_threshold sige “t”.
- Dette er den maksimale edit_distance, som vi vil overveje for ligheden mellem enhver node & query_word. Alt over dette afvises.
- Også vil vi kun overveje de børn af en overordnet knude til sammenligning med Query, hvor Levenstein(Child, Parent) er inden for
hvorfor? vil diskutere dette om kort tid
- Hvis denne betingelse er sand for et barn, vil vi kun beregne Levenstein(Child, Query), som vil blive betragtet som svarende til query, hvis
Levenshtein(Child, Query)≤t.
- Dermed vil vi ikke beregne Levenstein-afstanden for alle knuder/ord i ordbogen med forespørgselsordet & og dermed spare meget tid, når puljen af ord er enorm
Dermed, for at et barn skal ligne forespørgsel hvis
- Levenstein(Forældre, forespørgsel)-t ≤ Levenstein(Barn,Forældre) ≤ Levenstein(Forældre,Forældre)+t
- Levenstein(Barn,Forespørgsel)≤t
Lad os gennemgå et eksempel hurtigt. Lad ‘t’=1
Lad ordet, som vi skal finde lignende ord for, være ‘Care’ (forespørgselsord)
- Levenstein(Bog,Care)=4. Da 4>1, er ‘Bog’ afvist. Nu vil vi kun tage hensyn til de børn af ‘Bog’, som har en LevisteinDistance(Child,’Book’) mellem 3(4-1) & 5(4+1). Derfor vil vi afvise ‘Books’ & alle dens børn, da 1 ikke ligger inden for de fastsatte grænser
- Som Levenstein(Cake, Book)=4, der ligger mellem 3 & 5, vil vi kontrollere Levenstein(Cake, Care)=1, der er ≤1 og dermed et lignende ord.
- Retablering af grænserne, for Kages børn, bliver 0(1-1) & 2(1+1)
- Som både Cape & Cart har Levenstein(Barn, Forælder)=1 & 2 henholdsvis, er begge berettiget til at blive testet med ‘Care’.
- Som Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, er det kun Cape der betragtes som et ord der ligner ‘Care’.
Dermed fandt vi 2 ord der ligner ‘Care’, som er: Kage & Cape
Men på hvilket grundlag beslutter vi os for grænserne
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
for en hvilken som helst barnknude?
Dette følger af Triangle Inequality, som siger
Distance (A,B) + Distance(B,C)≥Distance(A,C), hvor A,B,C er sider af en trekant.
Hvordan denne idé hjælper os til at komme til disse grænser, lad os se:
Lad Query,=Q Parent=P & Child=C danne en trekant med Levenstein-afstanden som kantlængde. Lad “t” være tolerance_threshold. Så, Ved ovenstående ulighed
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Gennem trekant-ulighed,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Bitap-algoritme
Det er også en meget hurtig algoritme, som kan bruges til fuzzy string matching ret effektivt. Dette skyldes, at den bruger bitvise operationer &, da de er ret hurtige, algoritmen er kendt for sin hastighed. Uden at spilde en smule, lad os komme i gang:
Lad S0=’abababc’ være det mønster, der skal matches med strengen S1=’abdababababc’.
Først af alt,
- Find ud af alle unikke tegn i S1 & S0, der er a,b,c,d
- Form bitmønstre for hvert tegn. Hvordan?

- Returnerer det mønster S0, der skal søges
- For bitmønster for tegn x, placer 0 hvor det forekommer i mønsteret ellers 1. I T forekommer ‘a’ på 3. & 5. sted, vi placerede 0 på disse positioner & resten 1.
Form på samme måde alle andre bitmønstre for forskellige tegn i ordbogen.
S0=ababababc S1=abdababababc
- Tag en indledende tilstand af et bitmønster af længde(S0) med alle 1’er. I vores tilfælde vil det være 11111 (tilstand S).
- Da vi begynder at søge i S1 og passerer gennem et tegn,
skifter et 0 på den nederste bit, dvs. 5. bit fra højre i S &
OR-operation på S med T.
Da vi således støder på 1. ‘a’ i S1, vil vi
- Venstreskifte et 0 i S ved den nederste bit for at danne 11111 →11110
- 11010 | 11110=11110
Nu, da vi bevæger os til det 2. tegn ‘b’
- Skifter 0 til S i.e for at danne 11110 →11100
- S |T=11100 | 10101=11101
Så snart vi støder på ‘d’
- Skift 0 til S for at danne 11101 →11010
- S |T=11010 |11111=11111
Opmærksomheden henledes på, at da ‘d’ ikke er i S0, bliver tilstanden S nulstillet. Når du gennemgår hele S1, får du nedenstående stater ved hvert tegn

Hvordan ved jeg, om jeg har fundet en fuzz/fuld match?
- Hvis et 0 når den øverste bit i tilstand S-bitmønsteret (som i det sidste tegn “c”), har du et fuldt match
- For fuzz-match skal du observere 0 på forskellige positioner i tilstand S. Hvis 0 er på 4. plads, har vi fundet 4/5 tegn i samme rækkefølge som i S0. Tilsvarende for 0 på andre steder.
En ting du måske har bemærket er, at alle disse algoritmer arbejder på stavemåde lighed mellem strenge. Kan der være andre kriterier for fuzzy matching? Ja,
Fonetik
Vil dække fonetik(lydbaseret, som Saurav & Sourav, skal have et nøjagtigt match i fonetik) baserede fuzz match algoritmer næste gang !!!
- Dimension Reduction (3 dele)
- NLP Algoritmer(5 dele)
- Reinforcement Learning Basics (5 dele)
- Starting off with Time-Series (7 dele)
- Object Detection using YOLO (3 dele)
- Tensorflow for begyndere (koncepter + eksempler) (4 dele)
- Preprocessing Time Series (med koder)
- Data Analytics for begyndere
- Statistics for begyndere (4 dele)