Når vi diskuterer modelprædiktion, er det vigtigt at forstå forudsigelsesfejl (bias og varians). Der er en afvejning mellem en models evne til at minimere bias og varians. Hvis vi får en ordentlig forståelse af disse fejl, vil det ikke kun hjælpe os med at opbygge nøjagtige modeller, men også med at undgå fejlen med over- og undertilpasning.
Så lad os starte med det grundlæggende og se, hvordan de gør en forskel for vores maskinlæringsmodeller.
Hvad er bias?
Bias er forskellen mellem den gennemsnitlige forudsigelse af vores model og den korrekte værdi, som vi forsøger at forudsige. Model med høj bias er meget lidt opmærksom på træningsdataene og forsimpler modellen for meget. Det fører altid til en høj fejl på trænings- og testdata.
Hvad er varians?
Varians er variabiliteten af modellens forudsigelse for et givet datapunkt eller en værdi, som fortæller os om spredningen af vores data. Model med høj varians er meget opmærksom på træningsdata og generaliserer ikke på de data, som den ikke har set før. Som følge heraf klarer sådanne modeller sig meget godt på træningsdata, men har høje fejlrater på testdata.
Matematisk
Lad variablen, som vi forsøger at forudsige, være Y og andre kovariater være X. Vi antager, at der er en sådan sammenhæng mellem de to, at
Y=f(X) + e
Hvor e er fejltermen, og den er normalt fordelt med en middelværdi på 0.
Vi vil lave en model f^(X) af f(X) ved hjælp af lineær regression eller en anden modelleringsteknik.
Så den forventede kvadrerede fejl i et punkt x er
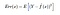
Den Err(x) kan yderligere dekomponeres som

Err(x) er summen af Bias², varians og den irreducerbare fejl.
Irreducible error er den fejl, som ikke kan reduceres ved at skabe gode modeller. Det er et mål for mængden af støj i vores data. Her er det vigtigt at forstå, at uanset hvor god vi laver vores model, vil vores data have en vis mængde støj eller irreducible fejl, som ikke kan fjernes.
Bias og varians ved hjælp af bulls-eye-diagrammet

I ovenstående diagram er centrum af målet en model, der perfekt forudsiger korrekte værdier. Efterhånden som vi bevæger os væk fra målet, bliver vores forudsigelser dårligere og dårligere. Vi kan gentage vores proces med modelopbygning for at få separate hits på målet.
I superviseret læring sker underpasning, når en model ikke er i stand til at fange det underliggende mønster i dataene. Disse modeller har normalt en høj bias og en lav varians. Det sker, når vi har meget få data til at opbygge en præcis model, eller når vi forsøger at opbygge en lineær model med ikke-lineære data. Disse modeller er også meget enkle til at indfange komplekse mønstre i data som lineær og logistisk regression.
I superviseret læring sker der overpasning, når vores model indfanger støjen sammen med det underliggende mønster i data. Det sker, når vi træner vores model meget over støjende datasæt. Disse modeller har lav bias og høj varians. Disse modeller er meget komplekse som f.eks. beslutningstræer, som er tilbøjelige til at blive overfittet.

Hvorfor er Bias Variance Tradeoff?
Hvis vores model er for simpel og har meget få parametre, kan den have høj bias og lav varians. På den anden side, hvis vores model har et stort antal parametre, så vil den have høj varians og lav bias. Så vi skal finde den rigtige/gode balance uden at overfitte og underfitte dataene.
Denne afvejning i kompleksitet er grunden til, at der er en afvejning mellem bias og varians. En algoritme kan ikke være mere kompleks og mindre kompleks på samme tid.
Totalfejl
For at opbygge en god model skal vi finde en god balance mellem bias og varians, således at den minimerer den samlede fejl.

En optimal balance mellem bias og varians vil aldrig overfitte eller underfitte modellen.
Det er derfor afgørende at forstå bias og varians for at forstå opførslen af forudsigelsesmodeller.
Tak for din læsning!