Introduktion Denne vejledning viser, hvordan du kan finde og eventuelt slette lignende eller duplikerede sider i det samme PDF-dokument ved hjælp af AutoSplit™-plugin’et til Adobe® Acrobat®. Denne operation opdager lignende sider og præsenterer dem for brugeren til en gennemgang. Brugeren kan gennemgå resultaterne og vælge/fravælge individuelle sider fra listen over dubletter med henblik på eventuel sletning eller udtrækning. Du kan udføre følgende operationer:
- Find duplikerede og næsten-duplikerede sider
- Bogmærke duplikerede sider
- Udtræk duplikerede sider til et separat PDF-dokument
- Slet duplikerede sider fra dokumentet
- Sparer rapport om sidelighed
Plug-in’et tilbyder to forskellige metoder til at registrere duplikerede eller næsten-duplikerede sider: Sammenlign kun sidetekst Brug denne metode til at sammenligne sideteksten uanset dens visuelle udseende. Den beregner sidens lighed baseret på tekstindholdet alene og ignorerer fuldstændigt tekstens udseende, layout, billeder og grafik, der måtte være til stede på siden. Det er den bedste metode til at finde dubletter i de fleste dokumenttyper. Sammenligning af sidernes visuelle udseende Denne metode sammenligner sider “som billeder” og registrerer sider, der ser nøjagtigt ens ud. Denne metode sammenligner ikke usynlig tekst, som måtte være til stede på siden. Det tilrådes ikke at bruge denne metode på scannede papirdokumenter. Brug af scannede papirdokumenter Ganske ofte bruges denne operation til at finde dobbeltsider i de scannede papirdokumenter. De scannede dokumenter skal OCR-behandles, før de kan bruges til tekstbaseret behandling. OCR er en proces til genkendelse af tekst i scannede dokumenter og til at gøre dem søgbare. Det er vigtigt at forstå, at tekstgenkendelse i scannede dokumenter er udsat for fejl, og at den sjældent er 100 % nøjagtig. Antallet af fejl afhænger af scanningsopløsningen og kvaliteten af originaldokumentet. I de mest almindelige tilfælde kan en scannet side indeholde mellem 1 og 10 genkendelsesfejl, hvor visse bogstaver er identificeret forkert. Afhængigt af skrifttypen kan det lille bogstav l f.eks. se nøjagtigt ud som tallet 1 . Det store bogstav O bliver ofte fejlagtigt identificeret som tallet 0, eller det store bogstav S som tallet 5 osv. Da mange alfanumeriske symboler har ens eller identiske fysiske egenskaber, er det ofte en udfordring at skelne dem fra hinanden. Det er derfor, at en sammenligning baseret på lighed er nyttig til at opdage små forskelle mellem sider, der er produceret af tekstgenkendelsesprocessen. Scannede dokumenter af lav kvalitet kan indeholde et stort antal fejl, hvilket gør dem ubrugelige for enhver pålidelig tekstbaseret sammenligning. Se den følgende vejledning om, hvordan man OCR-scanner dokumenter og vurderer deres egnethed til tekstbaseret behandling. . Forudsætninger Du skal have et eksemplar af Adobe® Acrobat® sammen med AutoSplit™ plug-in’et installeret på din computer for at kunne bruge denne vejledning. Du kan downloade prøveversioner af både Adobe® Acrobat® og AutoSplit™ plug-in’et. Indhold
- Komplign kun sidetekst
- Komplign kun visuelt udseende
- Sammenligning af flere dokumenter
Metode 1 – Sammenligning af sidetekst alene oversigt Denne metode sammenligner kun siders lighed baseret på deres sideindhold. Det visuelle udseende, tekstens placering og rækkefølge er irrelevant. Denne metode ignorerer også eventuelle billeder og grafik, der er til stede på siderne. Den modificerede cosinus-lignelsesmetriks metode anvendes til at beregne, hvor ens to sider er på grundlag af deres tekstindhold. Trin 1 – Åbn en PDF-fil Start Adobe® Acrobat®-programmet, og åbn en PDF-fil ved hjælp af menuen “File > Open…” (Fil > Åbn…)..PNG) Trin 2 – Åbn dialogboksen “Find Duplicate Pages” Vælg “Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” for at åbne dialogboksen “Find Duplicate Pages”.
Trin 2 – Åbn dialogboksen “Find Duplicate Pages” Vælg “Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” for at åbne dialogboksen “Find Duplicate Pages”..PNG) Trin 3 – Angiv indstillinger Markér indstillingen “Sammenlign kun sidetekst (ignorer sidernes visuelle udseende)”.
Trin 3 – Angiv indstillinger Markér indstillingen “Sammenlign kun sidetekst (ignorer sidernes visuelle udseende)”..PNG) Brug af foruddefinerede indstillinger Den tekstbaserede metode indeholder en række foruddefinerede parametersæt, der er velegnede til sammenligning af forskellige typer dokumenter med et forskelligt antal genkendelsesfejl. Hvert foruddefineret sæt af parametre giver forskellige betingelser for lighedsberegninger:
Brug af foruddefinerede indstillinger Den tekstbaserede metode indeholder en række foruddefinerede parametersæt, der er velegnede til sammenligning af forskellige typer dokumenter med et forskelligt antal genkendelsesfejl. Hvert foruddefineret sæt af parametre giver forskellige betingelser for lighedsberegninger:
- Brugerdefinerede indstillinger – alle indstillinger er specificeret af brugeren
- Scanning af papirdokument: Høj kvalitet
- Scannet papirdokument: Middel kvalitet
- Faxdokument: Lav kvalitet
- Non-scannet PDF: eksakt match
- Non-scannet PDF: fuzzy match
- Eksakt match (med tekstorden)- denne metode bruger ikke cosinus-lignende lighed
.PNG) Indstillingerne vises under menuen efter valg af et foruddefineret parametersæt.
Indstillingerne vises under menuen efter valg af et foruddefineret parametersæt..PNG) Her er de indstillinger, der anvendes af de foruddefinerede sæt:
Her er de indstillinger, der anvendes af de foruddefinerede sæt:.PNG) Klik på “Rediger…” for at tilpasse indstillingerne for sideoverensstemmelse:
Klik på “Rediger…” for at tilpasse indstillingerne for sideoverensstemmelse:.PNG) Metoden til tekstsammenligning bruger 3 parametre til at begrænse, hvor forskellige to “lignende” sider kan være. Ved at variere disse parametre er det muligt at opdage sider, der har en forskellig grad af lighed.
Metoden til tekstsammenligning bruger 3 parametre til at begrænse, hvor forskellige to “lignende” sider kan være. Ved at variere disse parametre er det muligt at opdage sider, der har en forskellig grad af lighed.
- Minimal tilladt tekstlighed mellem siderne (i procent) – dette er værdien af cosinus- lighedsmetrikken udtrykt i procent. Angiv mindste tilladte sidetekstelighed mellem 70 og 100 (i procent).
- Maksimal tilladt sidelængdeforskel (i tegn).
- Maksimal tilladt sidetekstelighed (i ord).
Brug disse indstillinger til at eksperimentere med behandlingsindstillingerne, når det er nødvendigt at justere behandlingsalgoritmen for et bestemt dokument..PNG) Brug prøvesider Klik eventuelt på “Indstil fra sideprøve…” for at angive indstillingerne for sideoverensstemmelse baseret på de to prøvesider:
Brug prøvesider Klik eventuelt på “Indstil fra sideprøve…” for at angive indstillingerne for sideoverensstemmelse baseret på de to prøvesider:
.PNG) Vælg to sider, der kan anses for at være identiske. Softwaren vil automatisk beregne sidelighed, og statistikken vises i det nederste venstre hjørne af dialogboksen. Klik på “OK” for at gemme de aktuelle lighedsindstillinger.
Vælg to sider, der kan anses for at være identiske. Softwaren vil automatisk beregne sidelighed, og statistikken vises i det nederste venstre hjørne af dialogboksen. Klik på “OK” for at gemme de aktuelle lighedsindstillinger..PNG) Angiv tekstfiltreringsindstillinger Der er flere parametre, der styrer det sideindhold, der analyseres af tekstsammenligningsalgoritmen. Brug disse indstillinger, når du sammenligner scannede papirdokumenter, der kan indeholde forskellige tekstgenkendelsesfejl. Disse indstillinger udelukker visse slags tegn fra behandling. I mange tilfælde kan det hjælpe med at beregne en mere præcis lighedsmetrik.
Angiv tekstfiltreringsindstillinger Der er flere parametre, der styrer det sideindhold, der analyseres af tekstsammenligningsalgoritmen. Brug disse indstillinger, når du sammenligner scannede papirdokumenter, der kan indeholde forskellige tekstgenkendelsesfejl. Disse indstillinger udelukker visse slags tegn fra behandling. I mange tilfælde kan det hjælpe med at beregne en mere præcis lighedsmetrik.
- Ignorér teksthukommelse – denne indstilling ignorerer teksthukommelse ved sammenligning af tekst.
- Ignorér tegnsætning (,.!?-) – denne indstilling udelukker alle tegnsætningstegn fra sammenligning.
- Ignorér ikke-alfanumeriske tegn – denne indstilling ignorerer alle tegn undtagen bogstaver og cifre.
Klik på “OK” for at gemme indstillingerne for sidelighed..PNG) Klik på “OK” for at begynde at søge i det aktuelle PDF-dokument efter de dublerede sider:
Klik på “OK” for at begynde at søge i det aktuelle PDF-dokument efter de dublerede sider:.PNG) Trin 4 – Undersøgelse af duplikerede sider Dialogboksen “Delete Duplicate Pages” viser en liste over duplikerede eller næsten-duplikerede sider. Klik på en sidepost for at få vist en tilsvarende side i viseren. Undersøg siderne, og vælg/fravælg sider til sletning. Klik eventuelt på “Save Report…” (Gem rapport…) for at oprette en rapport om sidelighed i HTML-format. Eller klik på “Bookmark Pages” (bogmærkesider) for at oprette bogmærker i PDF-filen for de valgte dubletsider.
Trin 4 – Undersøgelse af duplikerede sider Dialogboksen “Delete Duplicate Pages” viser en liste over duplikerede eller næsten-duplikerede sider. Klik på en sidepost for at få vist en tilsvarende side i viseren. Undersøg siderne, og vælg/fravælg sider til sletning. Klik eventuelt på “Save Report…” (Gem rapport…) for at oprette en rapport om sidelighed i HTML-format. Eller klik på “Bookmark Pages” (bogmærkesider) for at oprette bogmærker i PDF-filen for de valgte dubletsider..PNG) Plug-in’et giver mulighed for at få vist/ sammenligne de fundne duplikerede eller næsten-duplikerede sider. Sideoverensstemmelsen (i %) og antallet af uoverensstemmende ord vises for hvert par af sider. Her er eksemplerne beregnet for parret af de scannede papirdokumenter:
Plug-in’et giver mulighed for at få vist/ sammenligne de fundne duplikerede eller næsten-duplikerede sider. Sideoverensstemmelsen (i %) og antallet af uoverensstemmende ord vises for hvert par af sider. Her er eksemplerne beregnet for parret af de scannede papirdokumenter:.PNG)
.PNG) Bemærk, at tekstens udseende og placering ikke påvirker resultaterne. Disse to sider anses for at være identiske på trods af forskellen i tekstfarven:
Bemærk, at tekstens udseende og placering ikke påvirker resultaterne. Disse to sider anses for at være identiske på trods af forskellen i tekstfarven:.PNG) Disse to sider anses for at være identiske på trods af forskellen i layoutet af indholdet:
Disse to sider anses for at være identiske på trods af forskellen i layoutet af indholdet:.PNG) Disse to sider anses for at være 94 % ens på trods af forskellen i tekstens rækkefølge, layout og fraværet af billedet:
Disse to sider anses for at være 94 % ens på trods af forskellen i tekstens rækkefølge, layout og fraværet af billedet:.PNG) Trin 5 – Udtræk eller bogmærke kopierede sider Du kan eventuelt bruge knappen “Bogmærkesider” til at bogmærke alle de markerede sider. Dette er nyttigt, hvis du ikke har planer om at slette de fundne dobbeltsider fra dokumentet. Brug afkrydsningsfelterne foran siderne til at vælge/fravælge dem fra behandlingssættet. Brug knappen “Extract Pages….” til at udtrække alle markerede sider til et separat PDF-dokument. Denne operation vil ikke fjerne sider fra det aktuelle dokument.
Trin 5 – Udtræk eller bogmærke kopierede sider Du kan eventuelt bruge knappen “Bogmærkesider” til at bogmærke alle de markerede sider. Dette er nyttigt, hvis du ikke har planer om at slette de fundne dobbeltsider fra dokumentet. Brug afkrydsningsfelterne foran siderne til at vælge/fravælge dem fra behandlingssættet. Brug knappen “Extract Pages….” til at udtrække alle markerede sider til et separat PDF-dokument. Denne operation vil ikke fjerne sider fra det aktuelle dokument.
.PNG) Brug knappen “Save Report…” (Gem rapport…) til at gemme rapporten om beregning af sidelighed i en HTML-fil. Den indeholder detaljer om sidelighed, viser forskelle mellem sider og opregner manglende ord. Den kan være meget nyttig til den dybdegående analyse.
Brug knappen “Save Report…” (Gem rapport…) til at gemme rapporten om beregning af sidelighed i en HTML-fil. Den indeholder detaljer om sidelighed, viser forskelle mellem sider og opregner manglende ord. Den kan være meget nyttig til den dybdegående analyse.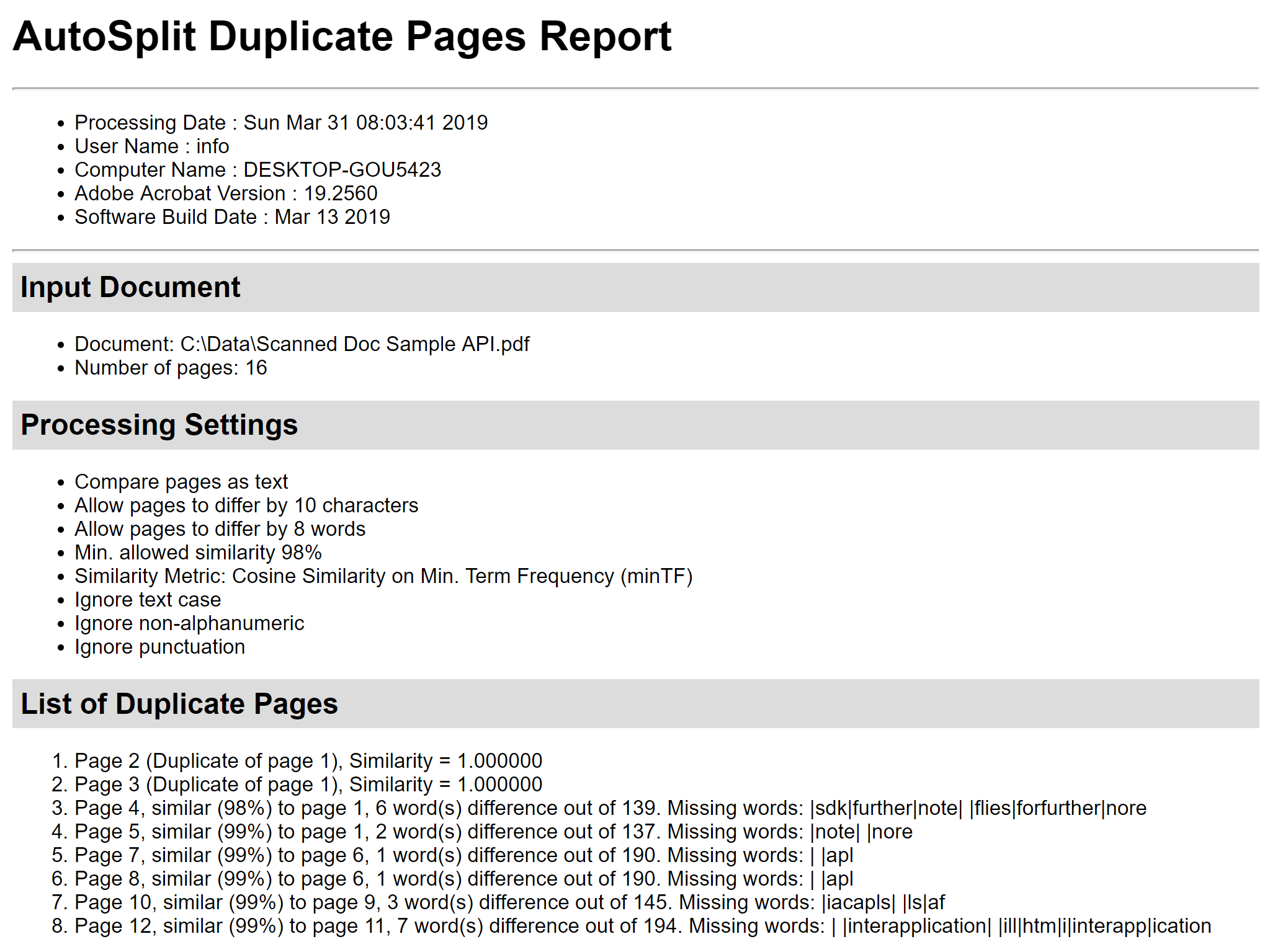 Trin 6 – Slet duplikerede sider Brug afkrydsningsfelterne foran siderne til at vælge/fravælge sider fra at blive slettet. Tryk på knappen “Delete Pages” i dialogboksen “Delete Duplicate Pages” for at fjerne alle markerede sider fra det aktuelle PDF-dokument:
Trin 6 – Slet duplikerede sider Brug afkrydsningsfelterne foran siderne til at vælge/fravælge sider fra at blive slettet. Tryk på knappen “Delete Pages” i dialogboksen “Delete Duplicate Pages” for at fjerne alle markerede sider fra det aktuelle PDF-dokument:.PNG) Klik på “OK”-knappen for at bekræfte. Siderne vil blive permanent fjernet.
Klik på “OK”-knappen for at bekræfte. Siderne vil blive permanent fjernet..PNG) Metode 2 – Sammenligning af visuelt udseende Kun oversigt Denne metode sammenligner sider “som billeder” og registrerer sider, der ser nøjagtigt ens ud. Denne metode sammenligner ikke usynlig tekst, som måtte være til stede på siden. Det tilrådes ikke at bruge denne metode på scannede papirdokumenter. Trin 1 – Åbn en PDF-fil Start Adobe® Acrobat®-programmet, og åbn en PDF-fil ved hjælp af menuen “File > Open…” (Fil > Åbn…).Trin 2 – Åbn dialogboksen “Find duplikatsider” Vælg “Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” for at åbne dialogboksen “Find Duplicate Pages”.Trin 3 – Angiv indstillinger Markér indstillingen “Compare visual appearance for exact match (can be used to compare images)”.
Metode 2 – Sammenligning af visuelt udseende Kun oversigt Denne metode sammenligner sider “som billeder” og registrerer sider, der ser nøjagtigt ens ud. Denne metode sammenligner ikke usynlig tekst, som måtte være til stede på siden. Det tilrådes ikke at bruge denne metode på scannede papirdokumenter. Trin 1 – Åbn en PDF-fil Start Adobe® Acrobat®-programmet, og åbn en PDF-fil ved hjælp af menuen “File > Open…” (Fil > Åbn…).Trin 2 – Åbn dialogboksen “Find duplikatsider” Vælg “Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” for at åbne dialogboksen “Find Duplicate Pages”.Trin 3 – Angiv indstillinger Markér indstillingen “Compare visual appearance for exact match (can be used to compare images)”..PNG) Klik på “OK” for at begynde at søge efter dublerede sider. Trin 4 – Inspicer duplikerede sider Dialogboksen “Delete Duplicate Pages” viser en liste over duplikerede eller næsten-duplikerede sider. Klik på en sidepost for at få vist den tilsvarende side i side-til-side-visningen. Undersøg siderne, og vælg/fravælg sider med henblik på en eventuel sletning.
Klik på “OK” for at begynde at søge efter dublerede sider. Trin 4 – Inspicer duplikerede sider Dialogboksen “Delete Duplicate Pages” viser en liste over duplikerede eller næsten-duplikerede sider. Klik på en sidepost for at få vist den tilsvarende side i side-til-side-visningen. Undersøg siderne, og vælg/fravælg sider med henblik på en eventuel sletning..PNG) Klik eventuelt på “Save Report…” (Gem rapport…) for at oprette en rapport om sidelighed i HTML-format. Eller klik på “Bookmark Pages” (Bogmærkesider) for at oprette bogmærker i PDF-fil for de valgte dubletsider. Denne metode er baseret på at oprette en mindre (stikprøvevis) kopi af siderne og sammenligne dem “som billeder”. Det følgende eksempel viser to identiske sider, der kun indeholder grafik og ingen søgbar tekst:
Klik eventuelt på “Save Report…” (Gem rapport…) for at oprette en rapport om sidelighed i HTML-format. Eller klik på “Bookmark Pages” (Bogmærkesider) for at oprette bogmærker i PDF-fil for de valgte dubletsider. Denne metode er baseret på at oprette en mindre (stikprøvevis) kopi af siderne og sammenligne dem “som billeder”. Det følgende eksempel viser to identiske sider, der kun indeholder grafik og ingen søgbar tekst:.PNG) Hvis siderne er visuelt identiske, registrerer softwaren dem som dubletter:
Hvis siderne er visuelt identiske, registrerer softwaren dem som dubletter:.PNG) Disse to sider anses for at være forskellige på grund af stemplet “Godkendt” på den ene af siderne:
Disse to sider anses for at være forskellige på grund af stemplet “Godkendt” på den ene af siderne:.PNG) Disse to sider anses for at være identiske efter denne metode:
Disse to sider anses for at være identiske efter denne metode:.PNG) I modsætning til den tekstbaserede sammenligningsmetode anses siderne ikke for at være identiske, hvis tekstens farve eller stil er forskellig:
I modsætning til den tekstbaserede sammenligningsmetode anses siderne ikke for at være identiske, hvis tekstens farve eller stil er forskellig:
.PNG) Trin 5 – Slet duplikerede sider Klik på “Delete Pages” (Slet sider) i dialogboksen “Delete Duplicate Pages” (Slet duplikerede sider) for at fortsætte. Klik på “OK”-knappen for at slette sider fra de aktuelle PDF-dokumenter. Siderne vil blive permanent fjernet.Sammenligning af flere PDF-dokumenter Denne operation kan bruges til at finde og fjerne dobbelte sider fra de flere PDF-dokumenter. Fremgangsmåden er at kombinere et eller flere dokumenter til en enkelt PDF-fil og køre “Find og slet dobbelte sider”-operationen på den resulterende fil. Dette vil i det væsentlige producere et enkelt dokument uden dubletter. Det er valgfrit muligt at udtrække alle fundne dobbeltsider til et separat PDF-dokument. Trin 1 – Kombinér flere PDF-dokumenter oversigt Start Adobe® Acrobat®-programmet, og vælg “Værktøjer” i menuen. Vælg ikonet “Combine Files” (kombinér filer) fra listen Værktøjer.
Trin 5 – Slet duplikerede sider Klik på “Delete Pages” (Slet sider) i dialogboksen “Delete Duplicate Pages” (Slet duplikerede sider) for at fortsætte. Klik på “OK”-knappen for at slette sider fra de aktuelle PDF-dokumenter. Siderne vil blive permanent fjernet.Sammenligning af flere PDF-dokumenter Denne operation kan bruges til at finde og fjerne dobbelte sider fra de flere PDF-dokumenter. Fremgangsmåden er at kombinere et eller flere dokumenter til en enkelt PDF-fil og køre “Find og slet dobbelte sider”-operationen på den resulterende fil. Dette vil i det væsentlige producere et enkelt dokument uden dubletter. Det er valgfrit muligt at udtrække alle fundne dobbeltsider til et separat PDF-dokument. Trin 1 – Kombinér flere PDF-dokumenter oversigt Start Adobe® Acrobat®-programmet, og vælg “Værktøjer” i menuen. Vælg ikonet “Combine Files” (kombinér filer) fra listen Værktøjer..PNG) Klik på “Add Files…” i menuen “Combine Files”, og vælg PDF-filer, der skal sammenlægges til sammenligning.
Klik på “Add Files…” i menuen “Combine Files”, og vælg PDF-filer, der skal sammenlægges til sammenligning..PNG) Klik på “Combine”-knappen i menuen for at flette de valgte PDF-filer.
Klik på “Combine”-knappen i menuen for at flette de valgte PDF-filer..PNG) Trin 2 – Find dobbelte sider Den kombinerede output PDF-fil vil blive vist på skærmen. Hvis ikke, skal du åbne den kombinerede PDF-fil. Vælg “Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” for at åbne dialogboksen “Find Duplicate Pages”.Markér indstillingen “Compare visual appearance for exact match (kan bruges til at sammenligne billeder)”. Klik på “OK” for at begynde at søge efter duplikerede sider.
Trin 2 – Find dobbelte sider Den kombinerede output PDF-fil vil blive vist på skærmen. Hvis ikke, skal du åbne den kombinerede PDF-fil. Vælg “Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” for at åbne dialogboksen “Find Duplicate Pages”.Markér indstillingen “Compare visual appearance for exact match (kan bruges til at sammenligne billeder)”. Klik på “OK” for at begynde at søge efter duplikerede sider..PNG) Trin 3 – Udtræk duplikerede sider Dialogboksen “Delete Duplicate Pages” viser en liste over duplikerede eller næsten-duplikerede sider. Klik på en sidepost for at få vist en tilsvarende side i viseren. Undersøg siderne, og vælg/fravælg sider. Klik på “Extract Pages…” for at udtrække de valgte dubletsider til et nyt PDF-dokument.
Trin 3 – Udtræk duplikerede sider Dialogboksen “Delete Duplicate Pages” viser en liste over duplikerede eller næsten-duplikerede sider. Klik på en sidepost for at få vist en tilsvarende side i viseren. Undersøg siderne, og vælg/fravælg sider. Klik på “Extract Pages…” for at udtrække de valgte dubletsider til et nyt PDF-dokument..PNG) Angiv en outputmappe og et filnavn. Klik på “Gem”, når du er færdig.
Angiv en outputmappe og et filnavn. Klik på “Gem”, når du er færdig..PNG) Dialogboksen vil blive vist med det antal sider, der er blevet udtrukket til et separat dokument. Nu har du gemt alle duplikerede sider i den separate PDF-fil, før du sletter dem. Du kan undersøge disse sider og bruge dem senere, hvis det er nødvendigt. Klik på “OK” for at lukke dialogboksen.
Dialogboksen vil blive vist med det antal sider, der er blevet udtrukket til et separat dokument. Nu har du gemt alle duplikerede sider i den separate PDF-fil, før du sletter dem. Du kan undersøge disse sider og bruge dem senere, hvis det er nødvendigt. Klik på “OK” for at lukke dialogboksen..png) Trin 4 – Slet duplikerede sider Klik på “Delete Pages” (Slet sider) i dialogboksen “Delete Duplicate Pages” (Slet duplikerede sider) for at fortsætte.
Trin 4 – Slet duplikerede sider Klik på “Delete Pages” (Slet sider) i dialogboksen “Delete Duplicate Pages” (Slet duplikerede sider) for at fortsætte..PNG) Klik på “OK” i dialogboksen for at slette de valgte duplikerede sider fra det aktuelle PDF-dokument.
Klik på “OK” i dialogboksen for at slette de valgte duplikerede sider fra det aktuelle PDF-dokument..PNG) De valgte dubletsider vil blive permanent fjernet fra PDF-dokumentet. Du skal bruge menuen “File > Save” (Fil > Gem) for at gemme det ændrede dokument på disken. Klik her for at få en liste over alle tilgængelige trin-for-trin vejledninger.
De valgte dubletsider vil blive permanent fjernet fra PDF-dokumentet. Du skal bruge menuen “File > Save” (Fil > Gem) for at gemme det ændrede dokument på disken. Klik her for at få en liste over alle tilgængelige trin-for-trin vejledninger.