- Funktionen og dens afledte funktion er begge monotone
- Output er nul “centreret”
- Optimering er lettere
- Derivativ /Differentiale af Tanh-funktionen (f'(x)) vil ligge mellem 0 og 1.
Konsekvenser:
- Derivativ af Tanh-funktionen lider under “Vanishing gradient and Exploding gradient problem”.
- Langsom konvergens- da den er beregningstung.(Årsag brug af eksponentiel matematisk funktion )
“Tanh er at foretrække frem for sigmoidfunktionen, da den er nulcentreret, og gradienterne ikke er begrænset til at bevæge sig i en bestemt retning”
3. ReLu-aktiveringsfunktion (ReLu – Rectified Linear Units):


ReLU er den ikke-lineære aktiveringsfunktion, der har vundet popularitet inden for kunstig intelligens. ReLu-funktionen er også repræsenteret som f(x) = max(0,x).
- Funktionen og dens afledte er begge monotone.
- Hovedfordelen ved at bruge ReLU-funktionen- Den aktiverer ikke alle neuroner på samme tid.
- Computationelt effektiv
- Derivativ /Differentiale af Tanh-funktionen (f'(x)) bliver 1 hvis f(x) > 0 ellers 0.
- Konvergerer meget hurtigt
Konsekvenser:
- ReLu-funktionen i ikke “nul-centreret”.Dette gør, at gradientopdateringerne går for langt i forskellige retninger. 0 < output < 1, og det gør optimering sværere.
- Død neuron er det største problem. det skyldes, at den ikke er differentierbar ved nul.
“Problem med døende neuron/Død neuron : Da ReLu-aflederen f'(x) ikke er 0 for de positive værdier af neuronen (f'(x)=1 for x ≥ 0), mætter ReLu ikke (eksploderer), og der rapporteres ikke om døde neuroner (Vanishing neuron). Mætning og forsvindende gradient forekommer kun for negative værdier, der, givet til ReLu, bliver til 0- Dette kaldes problemet med døende neuron.”
4. utæt ReLu aktiveringsfunktion:
Lækre ReLU-funktion er intet andet end en forbedret version af ReLU-funktionen med indførelse af “konstant hældning”


- Leaky ReLU er defineret for at løse problemet med døende neuron/dødt neuron.
- Problemet med døende neuron/dødt neuron løses ved at indføre en lille hældning, hvor de negative værdier skaleret med α gør det muligt for deres tilsvarende neuroner at “holde sig i live”.
- Funktionen og dens afledte er begge monotone
- Den tillader negative værdier under tilbagelægning
- Den er effektiv og nem at beregne.
- Derivativ af Leaky er 1, når f(x) > 0 og ligger mellem 0 og 1, når f(x) < 0.
Konsekvenser:
- Leaky ReLU giver ikke konsistente forudsigelser for negative inputværdier.
5. ELU (eksponentielle lineære enheder) Aktiveringsfunktion:

- ELU foreslås også til at løse problemet med døende neuron.
- Ingen problemer med død ReLU
- Zerocentrisk
Konsekvenser:
- Komputermæssigt intensivt.
- I lighed med Leaky ReLU er der, selv om det teoretisk set er bedre end ReLU, i øjeblikket ikke noget godt bevis i praksis for, at ELU altid er bedre end ReLU.
- F(x) er kun monoton, hvis alfa er større end eller lig med 0.
- F'(x) afledt af ELU er kun monoton, hvis alfa ligger mellem 0 og 1.
- Langsom konvergens på grund af eksponentialfunktionen.
6. P ReLu (Parametrisk ReLU) Aktiveringsfunktion:

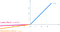
- Idéen om leaky ReLU kan udvides endnu mere.
- I stedet for at gange x med et konstant udtryk kan vi gange det med en “hyperparameter (a-trainable parameter)”, hvilket synes at virke bedre leaky ReLU. Denne udvidelse til leaky ReLU er kendt som Parametric ReLU.
- Parameteren α er generelt et tal mellem 0 og 1, og den er generelt relativt lille.
- Har en lille fordel i forhold til Leaky Relu på grund af trænbar parameter.
- Håndterer problemet med døende neuron.
Konsekvenser:
- Samme som leaky Relu.
- f(x) er monoton, når a> eller =0, og f'(x) er monoton, når a =1
7. Swish (A Self-Gated) Activation Function:(Sigmoid Linear Unit)

- Google Brain Team har foreslået en ny aktiveringsfunktion, kaldet Swish, som ganske enkelt er f(x) = x – sigmoid(x).
- Deres eksperimenter viser, at Swish har en tendens til at fungere bedre end ReLU på dybere modeller på tværs af en række udfordrende datasæt.
- Kurven for Swish-funktionen er glat, og funktionen er differentierbar i alle punkter. Dette er nyttigt under modeloptimeringsprocessen og anses for at være en af grundene til, at swish klarer sig bedre end ReLU.
- Swish-funktionen er “ikke monoton”. Det betyder, at funktionens værdi kan falde, selv når inputværdierne er stigende.
- Funktionen er ubegrænset foroven og begrænset forneden.
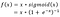
“Swish har en tendens til kontinuerligt at matche eller overgå ReLu”
Bemærk, at output af swish-funktionen kan falde, selv når inputværdierne stiger. Dette er en interessant og swish-specifik egenskab.(På grund af ikke-monotonisk karakter)
f(x)=2x*sigmoid(beta*x)
Hvis vi mener, at beta=0 er en simpel version af Swish, som er en lærbar parameter, så er sigmoid-delen altid 1/2, og f (x) er lineær. På den anden side, hvis beta er en meget stor værdi, bliver sigmoiden en næsten tocifret funktion (0 for x<0,1 for x>0). Således konvergerer f (x) mod ReLU-funktionen. Derfor vælges standard-Sigre-funktionen som beta = 1. På denne måde opnås en blød interpolation (der knytter de variable værdisæt til en funktion i det givne område og med den ønskede præcision). Fremragende! Der er fundet en løsning på problemet med gradienternes forsvinding.
8.Softplus
Softplus-funktionen ligner ReLU-funktionen, men den er relativt mere jævn.Funktion af Softplus eller SmoothRelu f(x) = ln(1+exp x).
Derivat af Softplus-funktionen er f'(x) er logistisk funktion (1/(1+exp x)).
Funktionens værdi ligger mellem (0, + inf).Både f(x) og f'(x) er monotone.
9.Softmax eller normaliseret eksponentiel funktion:

“Softmax”-funktionen er også en type sigmoidfunktion, men den er meget nyttig til at håndtere klassifikationsproblemer med flere klasser.
“Softmax kan beskrives som en kombination af flere sigmoidfunktioner.”
“Softmax-funktionen returnerer sandsynligheden for, at et datapunkt hører til hver enkelt klasse.”
Ved opbygning af et netværk til et problem med flere klasser vil outputlaget have lige så mange neuroner som antallet af klasser i målet.
Fors eksempelvis hvis man har tre klasser, vil der være tre neuroner i outputlaget. Antag, at du har fået output fra neuronerne som .Ved at anvende softmax-funktionen over disse værdier får du følgende resultat – . Disse repræsenterer sandsynligheden for, at datapunktet hører til hver klasse. Ud fra resultatet kan vi se, at input hører til klasse A.
“Bemærk, at summen af alle værdierne er 1.”
Hvilken er bedst at bruge? Hvordan vælger man den rigtige?
For at være ærlig er der ingen faste regler for valg af aktiveringsfunktion.Vi kan ikke skelne mellem aktiveringsfunktioner.Hver aktiveringsfunktion har sine egne fordele og ulemper.Alle de gode og dårlige vil blive afgjort på grundlag af sporet.
Men på grundlag af problemets egenskaber kan vi måske træffe et bedre valg for at sikre en nem og hurtigere konvergens af netværket.
- Sigmoid-funktioner og deres kombinationer fungerer generelt bedre i forbindelse med klassifikationsproblemer
- Sigmoider og tanh-funktioner undgås undertiden på grund af problemet med forsvindende gradient
- ReLU-aktiveringsfunktionen er meget anvendt i moderne tid.
- Hvis der er døde neuroner i vores netværk på grund af ReLu, så er den utætte ReLU-funktion det bedste valg
- ReLU-funktionen bør kun anvendes i de skjulte lag
“Som tommelfingerregel kan man begynde med at bruge ReLU-funktionen og derefter gå over til andre aktiveringsfunktioner, hvis ReLU ikke giver optimale resultater”