A imagem acima pode ter lhe dado idéia suficiente do que se trata este post.
Este post cobre alguns dos importantes algoritmos de combinação de strings fuzzy(não exatamente iguais, mas nódulos as mesmas strings, digamos RajKumar & Raj Kumar) que inclui:
Distância de Hamming
Distância de Levenstein
Damerau Levenstein Distance
Casamento de string baseado em N-Gram
Árvore BK
>
Bitap algoritmo
Mas devemos primeiro saber porque é que o cruzamento fuzzy é importante considerando um cenário do mundo real. Sempre que um usuário tem permissão para digitar qualquer dado, as coisas podem ficar realmente confusas como no caso abaixo!!
Let,
- Seu nome é ‘Saurav Kumar Agarwal’.
- Você recebeu um cartão de biblioteca (com um ID exclusivo, é claro) que é válido para cada membro de sua família.
- Você vai a uma biblioteca para emitir alguns livros a cada semana. Mas para isso, você primeiro precisa fazer uma entrada em um registro na entrada da biblioteca onde você digita seu ID & nome.
Agora, as autoridades da biblioteca decidem analisar os dados neste registro da biblioteca para ter uma idéia de leitores únicos visitando todos os meses. Agora, isto pode ser feito por muitas razões (como por exemplo, se vai ou não à expansão do terreno, o número de livros deve aumentar? etc.).
Planearam fazer isto contando (nomes únicos, ID da biblioteca) pares registados durante um mês. Então se temos
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Isto deve dar-nos 4 leitores únicos.
Até agora tudo bem
Eles estimaram este número em cerca de 10k-10.5k mas os números subiram até ~50k após análise por correspondência exata de nomes.
wooohhhh!!
Pretty bad estimate I must say !!
Or eles perderam um truque aqui?
Após uma análise mais profunda, um grande problema surgiu. Lembre-se do seu nome, ‘Saurav Agarwal’. Eles encontraram algumas entradas que levaram a 5 usuários diferentes em sua biblioteca familiar ID:
- Saurav K Aggrawal (repare no duplo ‘g’, ‘ra-ar’, Kumar torna-se K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Existem algumas ambiguidades pois as autoridades da Biblioteca não sabem
- Quantas pessoas visitam a biblioteca da sua família? se estes 5 nomes representam um único leitor, 2 ou 3 leitores diferentes. Chame-lhe um problema não supervisionado onde temos uma string representando nomes não padronizados mas os seus nomes padronizados não são conhecidos (ou seja, Saurav Agarwal: Saurav Kumar Agarwal não é conhecido)
- Todos eles devem fundir-se com ‘Saurav Kumar Agarwal’? não pode dizer como SK Agarwal pode ser Shivam Kumar Agarwal (diga o nome do seu Pai). Além disso, o único Agarwal pode ser qualquer pessoa da família.
Os últimos 2 casos (SK Agarwal & Agarwal) exigiriam alguma informação extra (como sexo, Data de Nascimento, Livros emitidos) que serão alimentados com algum algoritmo ML para determinar o nome real do leitor & devem ser deixados por enquanto. Mas uma coisa que estou bastante confiante é que os 3 primeiros nomes representam a mesma pessoa & Não deveria precisar de informação extra para fundi-los a um único leitor, i.e. ‘Saurav Kumar Agarwal’.
Como isto pode ser feito?
Vem aí uma correspondência de cadeia de caracteres, o que significa uma correspondência quase exacta entre cadeias de caracteres que são ligeiramente diferentes umas das outras (principalmente devido a ortografias erradas) como ‘Agarwal’ & ‘Aggarwal’ & ‘Aggrawal’. Se obtivermos uma string com uma taxa de erro aceitável (digamos uma letra errada), estaríamos considerando isso como uma correspondência. Então vamos explorar →
Hamming distance is the most obvious distance calculated between two string of equal length which gives a count of characters that don’t match corresponding a given index. Por exemplo: ‘Bat’ & ‘Bet’ tem distância de Hamming 1 como no índice 1, ‘a’ não é igual a ‘e’
Levenstein Distance/ Edit Distance
Though I assume que você está confortável com a distância de Levenstein & Recursion. Se não, leia isto. A explicação abaixo é mais uma versão resumida da distância do Levenstein.
Let ‘x’= comprimento(Str1) & ‘y’=comprimento(Str2) para todo este post.
Distância do Levenstein calcula o número mínimo de edições necessárias para converter ‘Str1’ para ‘Str2’, executando ou Adição, Remoção ou Substituição de caracteres. Assim ‘Cat’ & ‘Bat’ tem distância de edição ‘1’ (Substitua ‘C’ por ‘B’) enquanto que para ‘Ceat’ & ‘Bat’, seria 2 (Substitua ‘C’ por ‘B’; Apague ‘e’).
Falando sobre o algoritmo, ele tem principalmente 5 passos
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
O que estamos fazendo é começar a ler strings a partir do 1º caractere
- Se o caractere no índice ‘x’ do str1 corresponder ao caractere no índice ‘y’ do str2, não é necessário editar & calcular a distância de edição chamando
LevensteinDistance(str1,str2)
- Se não corresponderem, sabemos que é necessária uma edição. Então adicionamos +1 à distância edit_distance actual & calcula recursivamente a distância edit_distance para 3 condições & retira o mínimo das três:
Levenstein(str1,str2) →insertion em str2.
Levenstein(str1,str2) →deletion em str2
Levenstein(str1,str2)→replacement em str2
- Se alguma das cadeias de caracteres ficar sem caracteres durante a recursividade, o comprimento dos caracteres restantes na outra string são adicionados para editar a distância (os dois primeiros se afirmações)
Demerau-Levenstein Distance
Consider ‘abcd’ & ‘acbd’. Se formos pela Distância Levenstein, isto seria (substituir ‘b’-‘c’ & ‘c’-‘b’ nas posições de índice 2 & 3 na str2) Mas se você olhar com atenção, ambos os caracteres foram trocados como na str1 & se introduzirmos uma nova operação ‘Swap’ ao lado de ‘add’, ‘delete’ & ‘replace’, este problema pode ser resolvido. Esta introdução pode nos ajudar a resolver problemas como ‘Agarwal’ & ‘Agrawal’.
Esta operação é adicionada pelo pseudo-código abaixo
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Passemos a operação acima para ‘abcd’ & ‘acbd’ onde assume
inicial_x=1 & initial_y=1 (Iniciando a indexação a partir de 1 & não a partir de 0 para ambas as strings).
current x=3 & y=3 daí str1 & str2 em ‘c’ (abcd) & ‘b’ (acbd) respectivamente.
Limites superiores incluídos na operação de corte mencionada abaixo. Assim ‘qwerty’ significará ‘qwer’.
- last_matching_index_y será o último_index na str2 que combinou com a str1 i. 2 como ‘c’ em ‘acbd’ (índice 2)combinado com ‘c’ em ‘abcd’.
- last_matching_index_x será o último_index na str1 que combinou com a str2 i.e 2 como ‘b’ em ‘abcd’ (índice 2)combinado com ‘b’ em ‘acbd’.
- Hence, seguindo o pseudocódigo acima, DemarauLevenstein(‘abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(‘a’,’a’)=1+0+0+0=1. Isto teria sido 2 se tivéssemos seguido Levenstein Distance
N-Gram
N-gram é basicamente nada mais que um conjunto de valores gerados a partir de uma string através do emparelhamento sequencial de caracteres/palavras ‘n’. Por exemplo: n-grama com n=2 para ‘abcd’ será ‘ab’,’bc’,’cd’.
Agora, estes n-gramas podem ser gerados para strings cuja similaridade tem que ser medida & diferentes métricas podem ser usadas para medir a similaridade.
Deixe ‘abcd’ & ‘acbd’ serem 2 cordas a serem combinadas.
n-gramas com n=2 para
‘abcd’=ab,bc,cd
‘acbd’=ac,cb,bd
Componente compatível (qgrams)
Conta de n-gramas combinados exactamente para as duas cordas. Aqui, seria 0
Semelhança dos n-gramas
Cálculo do produto de pontos após a conversão de n-gramas gerados para as cordas em vetores
Casamento de componentes (sem ordem considerada)
Casamento de componentes de n-gramas ignorando a ordem dos elementos dentro de bc=cb.
Existem muitas outras métricas como distância Jaccard, índice Tversky, etc que não foram discutidas aqui.
Árvore BK
Árvore BK está entre os algoritmos mais rápidos para descobrir strings similares (de um pool de strings) para uma determinada string. A árvore BK usa uma
- Levenstein Distância
- Desigualdade triangular (estará cobrindo isto no final desta seção)
para descobrir strings similares(& e não apenas uma melhor string).
Uma árvore BK é criada usando um conjunto de palavras de um dicionário disponível. Digamos que temos um dicionário D={Book, Books, Cake, Boo, Boon, Cook, Cape, Cart}
Uma árvore BK é criada por
- Selecionar um nó raiz (pode ser qualquer palavra). Que seja ‘Books’
- Vá através de cada palavra W no Dicionário D, calcule sua distância Levenstein com o nó raiz, e faça a palavra W filho da raiz se não existir nenhuma criança com a mesma distância Levenstein para o pai. Inserindo Livros & Cake.
Levenstein(Books,Book)=1 & Levenstein(Books,Cake)=4. Como nenhuma criança com a mesma distância encontrada para ‘Livro’, faça-lhes novas crianças para raiz.
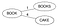
- Se existir uma criança com a mesma distância de Levenstein para o pai P, agora considere essa criança como pai P1 para essa palavra W, calcule Levenstein(pai, palavra) e se não existir nenhuma criança com a mesma distância para o pai P1, faça da palavra W uma nova criança para P1, continue descendo a árvore.
Considerando a inserção de Boo. Levenstein(Livro, Boo)=1 mas já existe uma criança com a mesma distância, ou seja, Books. Portanto, agora calcule Levenstein(Books, Boo)=2. Como não existe uma criança com a mesma distância para Books, faça Boo child of Books.

Similiarmente, insira todas as palavras do dicionário para BK Tree

Once BK Tree está preparada, para procurar palavras semelhantes para uma dada palavra (Query word) precisamos de definir um limite_de tolerância dizer ‘t’.
- Esta é a distância_de_edição máxima que vamos considerar para a similaridade entre qualquer nó & palavra_de_consulta. Qualquer coisa acima disto é rejeitada.
- Também, vamos considerar apenas os filhos de um nó pai para comparação com Query onde o Levenstein(Child, Parent) está dentro de
porquê? discutiremos isso em breve
- Se essa condição for verdadeira para uma criança, então somente estaremos calculando Levenstein(Child, Query) que será considerado similar à consulta se
Levenshtein(Child, Query)≤t.
- Hence, Não estaremos calculando a distância de Levenstein para todos os nós/palavras no Dicionário com a palavra de consulta &, portanto poupe muito tempo quando o conjunto de palavras for enorme
Hence, para uma Criança ser semelhante à Query se
- Levenstein(Parent, Query)-t ≤ Levenstein(Child,Parent) ≤ Levenstein(Parent,Query)+t
- Levenstein(Child,Query)≤t
Levenstein(Parent,Query)-t ≤ Levenstein(Parent,Query)+t
Levenstein(Parent,Query)-t Let ‘t’=1
Levenstein(Book,Care)=4. Como 4>1, ‘Livro’ é rejeitado. Agora vamos considerar apenas aqueles filhos de ‘Livro’ que têm uma LevisteinDistance(Child,’Book’) entre 3(4-1) & 5(4+1). Assim, estaremos rejeitando ‘Livros’ & todos os seus filhos pois 1 não se encontra nos limites estabelecidos
Hence, encontramos 2 palavras similares a ‘Care’ que são: Bolo & Cabo
Mas em que base estamos a decidir sobre os limites
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
para qualquer nó de criança?
>
Esta é a seguinte a partir do Triângulo Desigualdade que diz
Distância (A,B) + Distância(B,C)≥Distance(A,C) onde A,B,C são lados de um triângulo.
Como esta ideia nos ajuda a chegar a estes limites, vejamos:
Let Query,=Q Parent=P &Criança=C forma um triângulo com a distância de Levenstein como comprimento da borda. Que o ‘t’ seja o limite de tolerância. Então, Por acima da desigualdade
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Again, por Triangle Inequality,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Bitap algoritmo
É também um algoritmo muito rápido que pode ser usado para correspondência de strings difusas de forma bastante eficiente. Isto é porque usa operações bitwise & como são bastante rápidas, o algoritmo é conhecido pela sua velocidade. Sem desperdiçar um pouco, vamos começar:
Let S0=’ababc’ é o padrão a ser combinado com a string S1=’abdabababc’.
Primeiro de todos,
- Figure todos os caracteres únicos em S1 & S0 que são a,b,c,d
- Padrão de bits para cada caractere. Como?

- Reverse o padrão S0 a ser pesquisado
- Para padrão de bit para o caractere x, coloque 0 onde ocorre no padrão outro 1. Em T, ‘a’ ocorre em 3º & 5º lugar, colocamos 0 nessas posições & descanso 1.
Simplesmente, forme todos os outros padrões de bit para diferentes caracteres no dicionário.
S0=ababc S1=abdabababc
- Tome um estado inicial de um padrão de bit de comprimento(S0) com todos os 1’s. No nosso caso, seria 11111 (State S).
- As we start searching in S1 and pass through any character,
shift a 0 at the lowermost bit i.e. 5th bit from the right in S &
OR operação em S com T.
Hence, como vamos encontrar o 1º ‘a’ em S1, vamos
- Shift a 0 em S no bit mais baixo para formar 11111 →11110
- 11010 | 11110=11110
Agora, ao passarmos para o 2º caractere ‘b’
- Shift 0 para S i.e para formar 11110 →11100
- S |T=11100 | 10101=11101
Como ‘d’ é encontrado
- Shift 0 para S para formar 11101 →11010
>S |T=11010 |11111=1111111
Observe que como ‘d’ não está em S0, o estado S é reiniciado. Uma vez que você atravessar todo o S1, você irá os estados abaixo em cada caractere

Como eu sei se encontrei algum fuzz/full match?
- Se um 0 atingir o maior número de bits no padrão de bits State S (como no último caractere ‘c’), você tem uma correspondência completa
- Para correspondência de fuzz, observe 0 em diferentes posições de State S. Se 0 estiver em 4º lugar, encontramos 4/5 caracteres na mesma sequência que em S0. Similarmente para 0 em outros lugares.
Uma coisa que você pode ter observado é que todos esses algoritmos funcionam na similaridade ortográfica das cordas. Pode haver algum outro critério para a correspondência fuzzy? Sim,
Fonética
Vai cobrir fonética (baseada em som, como Saurav & Sourav, deve ter uma correspondência exata em fonética) baseado em algoritmos de fuzz match a seguir !!
- Dimension Reduction (3 partes)
- Algoritmos de NLP(5 partes)
- Reforço Básico de Aprendizagem (5 partes)
- Começando com o Tempo-Série (7 partes)
- Detecção de objectos usando YOLO (3 partes)
- Fluxo de Tensor para principiantes (conceitos + exemplos) (4 partes)
- Série de Tempo de Pré-processamento (com códigos)
- Análise de dados para principiantes
- Estatística para principiantes (4 partes)