Método 1, Mau: PEDIDO POR NEWID()
Fácil de escrever, mas funciona como lixo quente, quente, porque ele varre todo o índice agrupado, calculando NEWID() em cada linha:
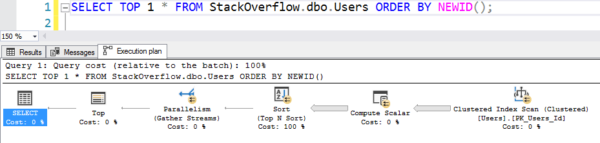
O plano com a varredura
Que levou 6 segundos na minha máquina, passando paralelamente por vários threads, usando dezenas de segundos de CPU para toda aquela computação e ordenação. (E a tabela Utilizadores nem sequer tem 1GB.)
Método 2, Melhor mas Estranho: TABLESAMPLE
Saiu em 2005, e tem uma tonelada de gotchas. É como que escolher uma página aleatória, e depois devolver um monte de filas dessa página. A primeira linha é meio aleatória, mas o resto não é.
>
>
>
>
>
>
>>
>
>>
Transact-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENTRO);
|
O plano parece estar fazendo uma varredura de tabela, mas está fazendo apenas 7 leituras lógicas:
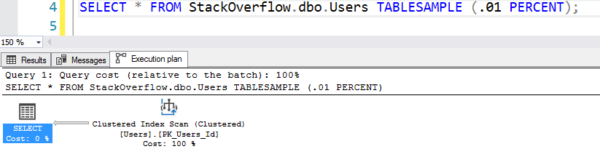
O plano com a varredura falsa
Mas aqui estão os resultados – você pode ver que ele salta para uma página 8K aleatória e então começa a ler linhas em ordem. Não são linhas realmente aleatórias.
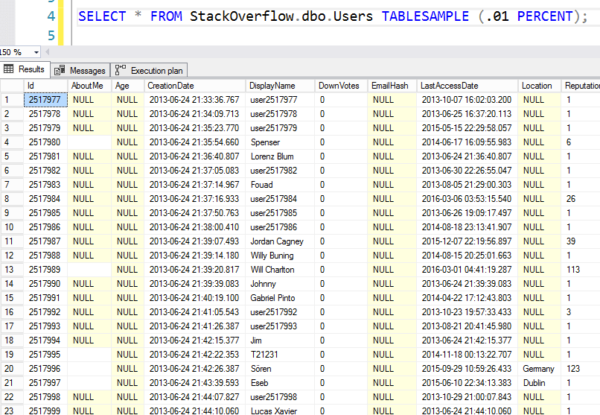
Números da loteria da máfia aleatórios
Você pode usar o tamanho da amostra ROWS em vez disso, mas ele tem alguns resultados bastante estranhos. Por exemplo, na tabela Stack Overflow Users, quando eu disse TABLESAMPLE (50 ROWS), na verdade eu consegui 75 linhas de volta. Isso porque o SQL Server converte o tamanho da sua linha para uma percentagem em vez disso.
Método 3, Melhor mas Requer Código: Random Primary Key
Pega o campo de ID do topo da tabela, gera um número aleatório, e procura por esse ID. Aqui, estamos ordenando pelo ID porque queremos encontrar o registro superior que realmente existe (enquanto um número aleatório pode ter sido excluído). Se você quisesse 10 linhas, você teria que chamar código como este 10 vezes (ou gerar 10 números aleatórios e usar uma cláusula IN.)
O plano de execução mostra uma varredura de índice agrupada, mas está agarrando apenas uma linha – estamos falando apenas de 6 leituras lógicas para tudo que você vê aqui, e termina quase instantaneamente:

O plano que pode
Existe um que tem: se o Id tiver números negativos, não funcionará como esperado. (Por exemplo, digamos que você começa seu campo de identidade em -1 e passo -1, indo sempre para baixo, como a minha moral.)
Método 4, OFFSET-FETCH (2012+)
Daniel Hutmacher adicionou este nos comentários:
E disse: “Mas ele só funciona corretamente com um índice agrupado. Acho que isso é porque vai procurar por (@linhas) linhas numa pilha em vez de fazer uma procura de índice”
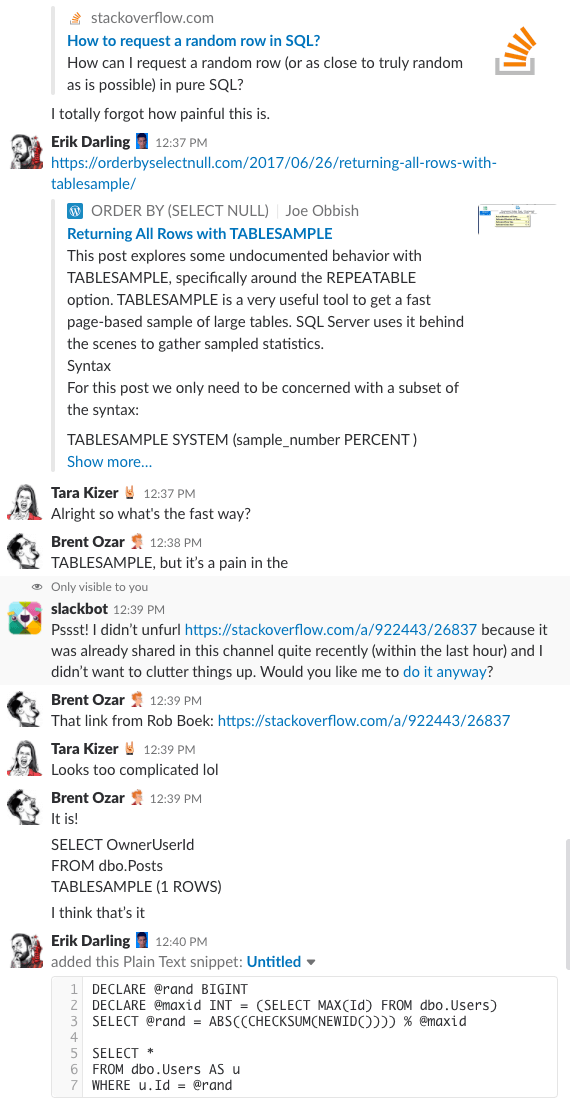
Bonus Track #1: Veja-nos a discutir isto
Ever como é estar na sala de chat da nossa empresa? Esta discussão de 10 minutos de folga lhe dará uma boa idéia:
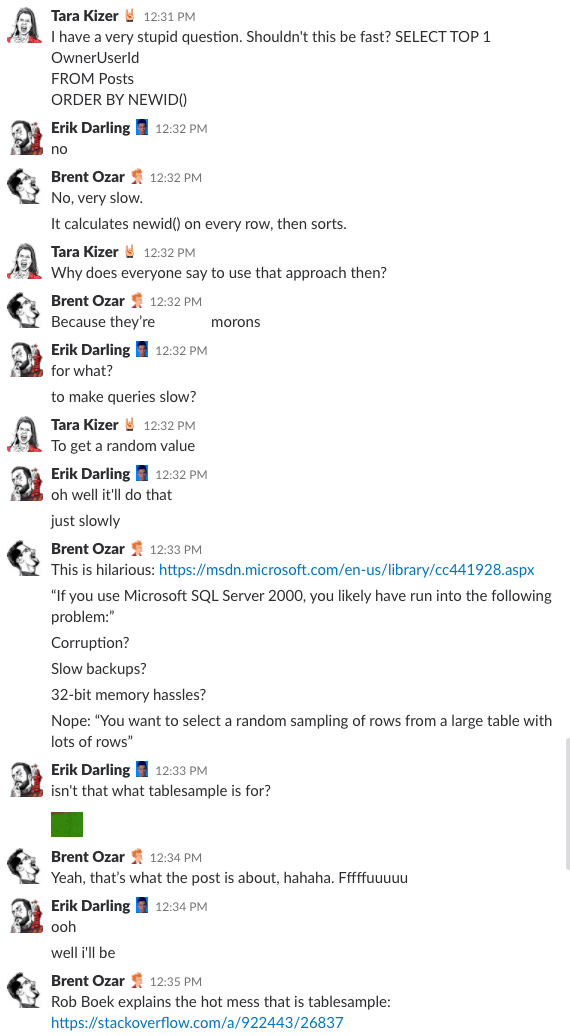
>
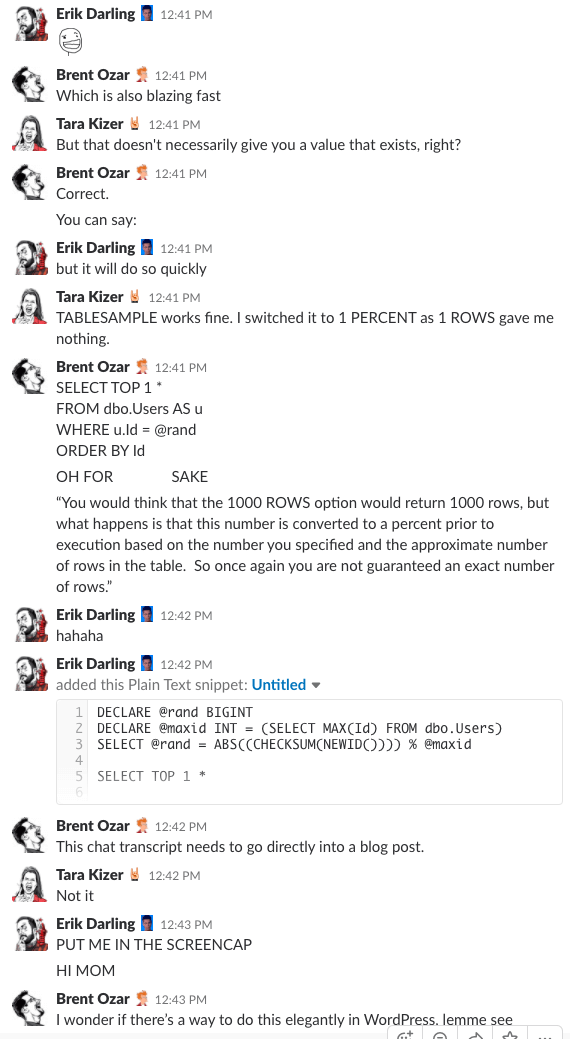
Alerta de spoiler: não houve. Acabei de tirar screenshots.
Pista de Bónus #2: Mitch Wheat Digs Deeper
Quer uma análise profunda da aleatoriedade de várias técnicas diferentes? Mitch Wheat mergulha muito fundo, completo com gráficos!