- Introducción
- Objetivo
- A. Métodos de filtrado
- Prueba de Chi-cuadrado
- Puntuación de Fisher
- Coeficiente de correlación
- Umbral de varianza
- Diferencia absoluta media (MAD)
- Razón de dispersión
- B. Métodos envolventes:
- Selección de características hacia delante
- Eliminación de características hacia atrás
- Selección exhaustiva de características
- Eliminación recursiva de características
- C. Métodos incorporados:
- Regularización deLASSO (L1)
- Importancia de los Bosques Aleatorios
- Conclusión
Introducción
Cuando se construye un modelo de aprendizaje automático en la vida real, es casi raro que todas las variables del conjunto de datos sean útiles para construir un modelo. Añadir variables redundantes reduce la capacidad de generalización del modelo y también puede reducir la precisión global de un clasificador. Además, añadir más y más variables a un modelo aumenta la complejidad global del mismo.
Según la Ley de Parsimonia de la «Navaja de Occam», la mejor explicación a un problema es la que implica el menor número de supuestos posibles. Por lo tanto, la selección de características se convierte en una parte indispensable de la construcción de modelos de aprendizaje automático.
Objetivo
El objetivo de la selección de características en el aprendizaje automático es encontrar el mejor conjunto de características que permita construir modelos útiles de los fenómenos estudiados.
Las técnicas de selección de características en el aprendizaje automático pueden clasificarse a grandes rasgos en las siguientes categorías:
Técnicas supervisadas: Estas técnicas se pueden utilizar para datos etiquetados, y se utilizan para identificar las características relevantes para aumentar la eficiencia de los modelos supervisados como la clasificación y la regresión.
Técnicas no supervisadas: Estas técnicas pueden utilizarse para datos no etiquetados.
Desde un punto de vista taxonómico, estas técnicas se clasifican en:
A. Métodos de filtrado
B. Métodos de envoltura
C. Métodos embebidos
D. Métodos híbridos
En este artículo, discutiremos algunas técnicas populares de selección de características en el aprendizaje automático.
A. Métodos de filtrado
Los métodos de filtrado recogen las propiedades intrínsecas de las características medidas a través de estadísticas univariantes en lugar del rendimiento de la validación cruzada. Estos métodos son más rápidos y menos costosos computacionalmente que los métodos de envoltura. Cuando se trata de datos de alta dimensión, es computacionalmente más barato utilizar métodos de filtro.
Discutiremos algunas de estas técnicas:
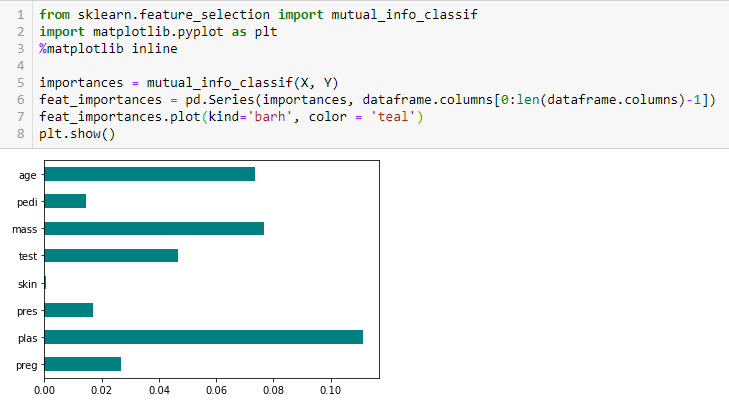
Ganancia de información
La ganancia de información calcula la reducción de la entropía de la transformación de un conjunto de datos. Puede utilizarse para la selección de características evaluando la ganancia de información de cada variable en el contexto de la variable objetivo.
Prueba de Chi-cuadrado
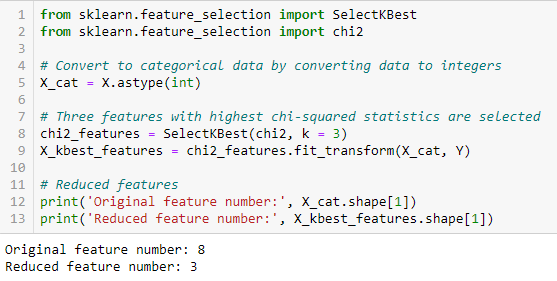
La prueba de Chi-cuadrado se utiliza para características categóricas en un conjunto de datos. Calculamos el Chi-cuadrado entre cada característica y el objetivo y seleccionamos el número deseado de características con las mejores puntuaciones de Chi-cuadrado. Para aplicar correctamente el chi-cuadrado con el fin de probar la relación entre varias características del conjunto de datos y la variable objetivo, deben cumplirse las siguientes condiciones: las variables deben ser categóricas, muestreadas de forma independiente y los valores deben tener una frecuencia esperada superior a 5.
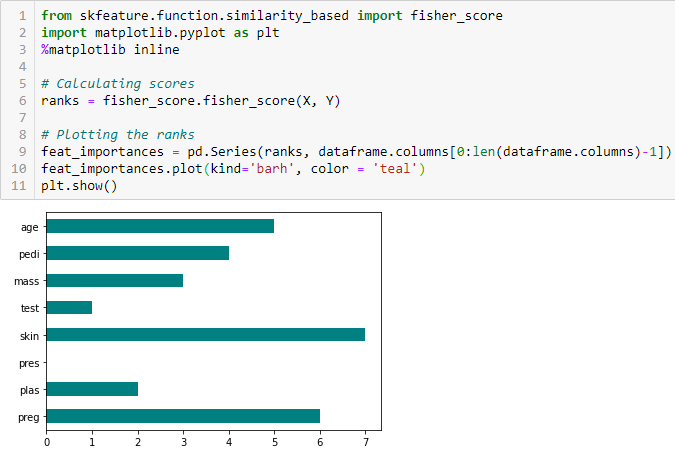
Puntuación de Fisher
La puntuación de Fisher es uno de los métodos supervisados de selección de características más utilizados. El algoritmo que utilizaremos devuelve los rangos de las variables basados en la puntuación de Fisher en orden descendente. Podemos entonces seleccionar las variables según el caso.
Coeficiente de correlación
La correlación es una medida de la relación lineal de 2 o más variables. A través de la correlación, podemos predecir una variable a partir de la otra. La lógica detrás de usar la correlación para la selección de características es que las buenas variables están altamente correlacionadas con el objetivo. Además, las variables deben estar correlacionadas con el objetivo pero no deben estar correlacionadas entre sí.
Si dos variables están correlacionadas, podemos predecir una a partir de la otra. Por lo tanto, si dos características están correlacionadas, el modelo sólo necesita realmente una de ellas, ya que la segunda no añade información adicional. Aquí utilizaremos la correlación de Pearson.
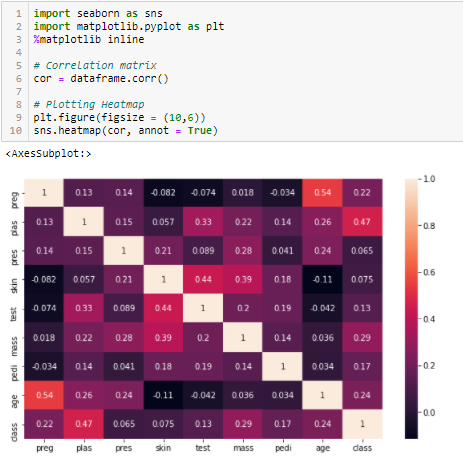
Necesitamos establecer un valor absoluto, digamos 0,5 como umbral para seleccionar las variables. Si encontramos que las variables predictoras están correlacionadas entre sí, podemos descartar la variable que tenga un valor de coeficiente de correlación más bajo con la variable objetivo. También podemos calcular los coeficientes de correlación múltiple para comprobar si hay más de dos variables correlacionadas entre sí. Este fenómeno se conoce como multicolinealidad.
Umbral de varianza
El umbral de varianza es un enfoque básico simple para la selección de características. Elimina todas las características cuya varianza no cumple con algún umbral. Por defecto, elimina todas las características de varianza cero, es decir, las características que tienen el mismo valor en todas las muestras. Suponemos que las características con una mayor varianza pueden contener más información útil, pero tenga en cuenta que no estamos teniendo en cuenta la relación entre las variables de las características o las variables de las características y el objetivo, que es uno de los inconvenientes de los métodos de filtrado.

El get_support devuelve un vector booleano donde True significa que la variable no tiene varianza cero.
Diferencia absoluta media (MAD)
‘La diferencia absoluta media (MAD) calcula la diferencia absoluta con respecto al valor medio. La principal diferencia entre las medidas de varianza y MAD es la ausencia del cuadrado en esta última. La DAM, al igual que la varianza, es también una variante de escala.’ Esto significa que a mayor DAM, mayor poder discriminatorio.
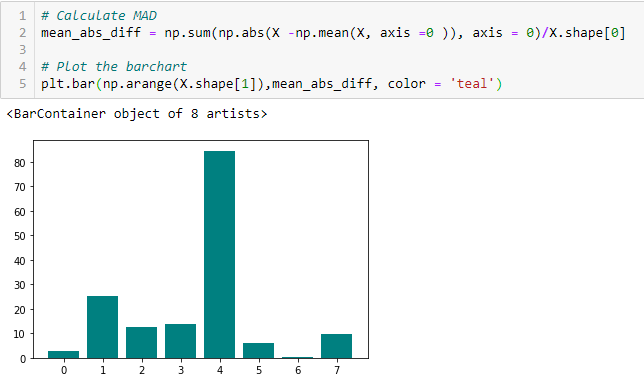
Razón de dispersión
‘Otra medida de dispersión aplica la media aritmética (MA) y la media geométrica (MG). Para una característica Xi dada (positiva) en n patrones, la AM y la GM vienen dadas por
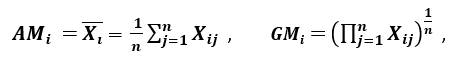
respectivamente; dado que AMi ≥ GMi, con igualdad si y sólo si Xi1 = Xi2 = …. = Xin, entonces la relación
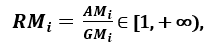
puede utilizarse como medida de dispersión. Una mayor dispersión implica un mayor valor de Ri y, por tanto, una característica más relevante. Por el contrario, cuando todas las muestras de rasgos tienen (aproximadamente) el mismo valor, Ri está cerca de 1, lo que indica un rasgo de baja relevancia.’

 ‘
‘
B. Métodos envolventes:
Los wrappers requieren algún método para buscar en el espacio de todos los posibles subconjuntos de características, evaluando su calidad mediante el aprendizaje y la evaluación de un clasificador con ese subconjunto de características. El proceso de selección de características se basa en un algoritmo de aprendizaje automático específico que se intenta ajustar a un conjunto de datos determinado. Sigue un enfoque de búsqueda codiciosa evaluando todas las posibles combinaciones de características con respecto al criterio de evaluación. Los métodos de envoltura suelen dar lugar a una mayor precisión predictiva que los métodos de filtrado.
Discutiremos algunas de estas técnicas:
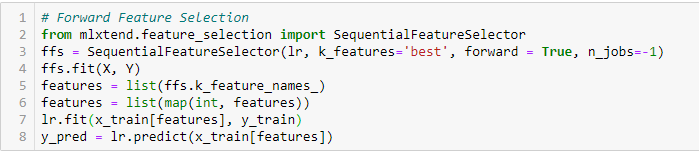
Selección de características hacia delante
Se trata de un método iterativo en el que comenzamos con la variable de mejor rendimiento frente al objetivo. A continuación, seleccionamos otra variable que ofrezca el mejor rendimiento en combinación con la primera variable seleccionada. Este proceso continúa hasta que se alcanza el criterio preestablecido.
Eliminación de características hacia atrás
Este método funciona exactamente al revés que el método de selección de características hacia delante. Aquí, empezamos con todas las características disponibles y construimos un modelo. A continuación, la variable del modelo que da el mejor valor de la medida de evaluación. Este proceso continúa hasta que se alcanza el criterio preestablecido.
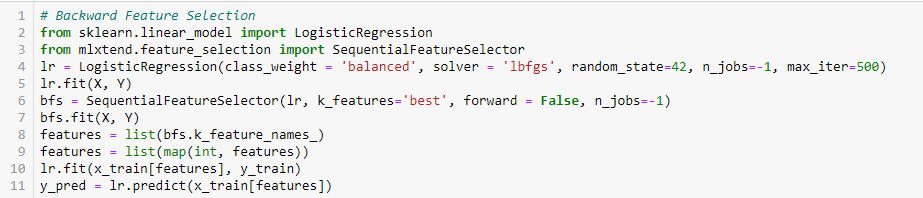
Este método, junto con el anterior, también se conoce como método de selección secuencial de características.
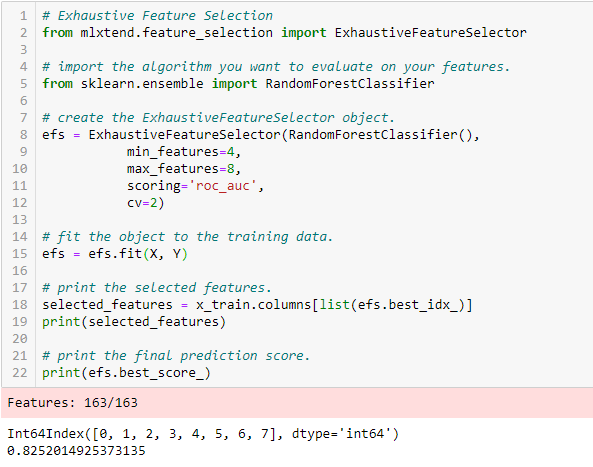
Selección exhaustiva de características
Este es el método de selección de características más robusto cubierto hasta ahora. Se trata de una evaluación de fuerza bruta de cada subconjunto de características. Esto significa que prueba todas las combinaciones posibles de las variables y devuelve el subconjunto de mejor rendimiento.
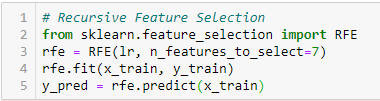
Eliminación recursiva de características
‘Dado un estimador externo que asigna pesos a las características (por ejemplo, los coeficientes de un modelo lineal), el objetivo de la eliminación recursiva de características (RFE) es seleccionar características considerando recursivamente conjuntos cada vez más pequeños de características. En primer lugar, el estimador se entrena en el conjunto inicial de características y la importancia de cada característica se obtiene a través de un atributo coef_ o a través de un atributo feature_importances_.
Entonces, las características menos importantes se eliminan del conjunto actual de características. Este procedimiento se repite recursivamente en el conjunto podado hasta que se alcanza el número deseado de características a seleccionar.’
C. Métodos incorporados:
Estos métodos engloban las ventajas de los métodos de envoltura y de filtro, al incluir las interacciones de las características pero manteniendo un coste computacional razonable. Los métodos embebidos son iterativos en el sentido de que se encargan de cada iteración del proceso de entrenamiento del modelo y extraen cuidadosamente aquellas características que más contribuyen al entrenamiento para una iteración en particular.
Discutimos algunas de estas técnicas pulsando aquí:
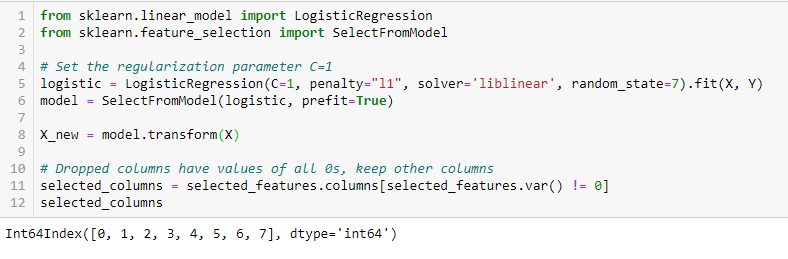
Regularización deLASSO (L1)
La regularización consiste en añadir una penalización a los diferentes parámetros del modelo de aprendizaje automático para reducir la libertad del modelo, es decir, para evitar el sobreajuste. En la regularización de modelos lineales, la penalización se aplica sobre los coeficientes que multiplican cada uno de los predictores. De los distintos tipos de regularización, Lasso o L1 tiene la propiedad de que es capaz de reducir a cero algunos de los coeficientes. Por lo tanto, esa característica puede ser eliminada del modelo.
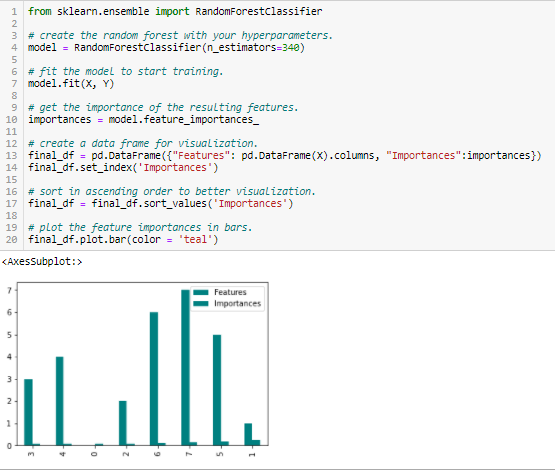
Importancia de los Bosques Aleatorios
Los Bosques Aleatorios son una especie de Algoritmo de Ensacado que agrega un número específico de árboles de decisión. Las estrategias basadas en árboles utilizadas por los bosques aleatorios se clasifican naturalmente en función de cómo mejoran la pureza del nodo, o en otras palabras, una disminución de la impureza (impureza de Gini) sobre todos los árboles. Los nodos con la mayor disminución de la impureza se encuentran al principio de los árboles, mientras que las notas con la menor disminución de la impureza se encuentran al final de los árboles. Así, podando los árboles por debajo de un nodo concreto, podemos crear un subconjunto de las características más importantes.
Conclusión
Hemos discutido algunas técnicas para la selección de características. Hemos dejado a propósito las técnicas de extracción de características como el Análisis de Componentes Principales, la Descomposición de Valores Singulares, el Análisis Discriminante Lineal, etc. Estos métodos ayudan a reducir la dimensionalidad de los datos o a reducir el número de variables preservando la varianza de los datos.
Aparte de los métodos discutidos anteriormente, hay muchos otros métodos de selección de características. También existen métodos híbridos que utilizan tanto técnicas de filtrado como de envoltura. Si desea explorar más sobre las técnicas de selección de características, gran material de lectura completa en mi opinión sería ‘Feature Selection for Data and Pattern Recognition’ por Urszula Stańczyk y Lakhmi C. Jain.