Actualización 29-mayo-2018: El propósito de este artículo es triple (1) Mostrar que siempre necesitaremos un modelo de datos (ya sea hecho por humanos o máquinas) (2) Mostrar que el modelado físico no es lo mismo que el modelado lógico. De hecho, es muy diferente y depende de la tecnología subyacente. Sin embargo, necesitamos ambos. He ilustrado este punto utilizando Hadoop en la capa física (3) Mostrar el impacto del concepto de inmutabilidad en el modelado de datos.
- ¿Ha muerto el modelado dimensional?
- ¿Por qué necesitamos modelar nuestros datos?
- ¿Por qué necesitamos modelos dimensionales?
- Modelado de datos frente a modelado dimensional
- Entonces, ¿por qué algunas personas afirman que el modelado dimensional está muerto?
- El almacén de datos está muerto Confusión
- El malentendido del esquema en lectura
- Denormalización revisada. Los aspectos físicos del modelo.
- Llevar la desnormalización a su máxima expresión
- Distribución de datos en una base de datos relacional distribuida (MPP)
- Distribución de datos en Hadoop
- Modelos dimensionales en Hadoop
- Hadoop y las dimensiones que cambian lentamente
- Evolución del almacenamiento en Hadoop
- El veredicto. ¿Son obsoletos los modelos dimensionales y los esquemas en estrella?
- Lectura complementaria sobre el modelado dimensional en la era del Big Data
¿Ha muerto el modelado dimensional?
Antes de dar una respuesta a esta pregunta vamos a dar un paso atrás y primero echar un vistazo a lo que entendemos por modelado dimensional de datos.
¿Por qué necesitamos modelar nuestros datos?
Contrariamente a un malentendido común, no es el único propósito de los modelos de datos servir como un diagrama ER para diseñar una base de datos física. Los modelos de datos representan la complejidad de los procesos de negocio en una empresa. Documentan importantes reglas y conceptos empresariales y ayudan a estandarizar la terminología clave de la empresa. Aportan claridad y ayudan a descubrir las ideas borrosas y las ambigüedades de los procesos empresariales. Además, se pueden utilizar los modelos de datos para comunicarse con otras partes interesadas. No se construiría una casa o un puente sin un plano. Entonces, ¿por qué construir una aplicación de datos, como un almacén de datos, sin un plano?
¿Por qué necesitamos modelos dimensionales?
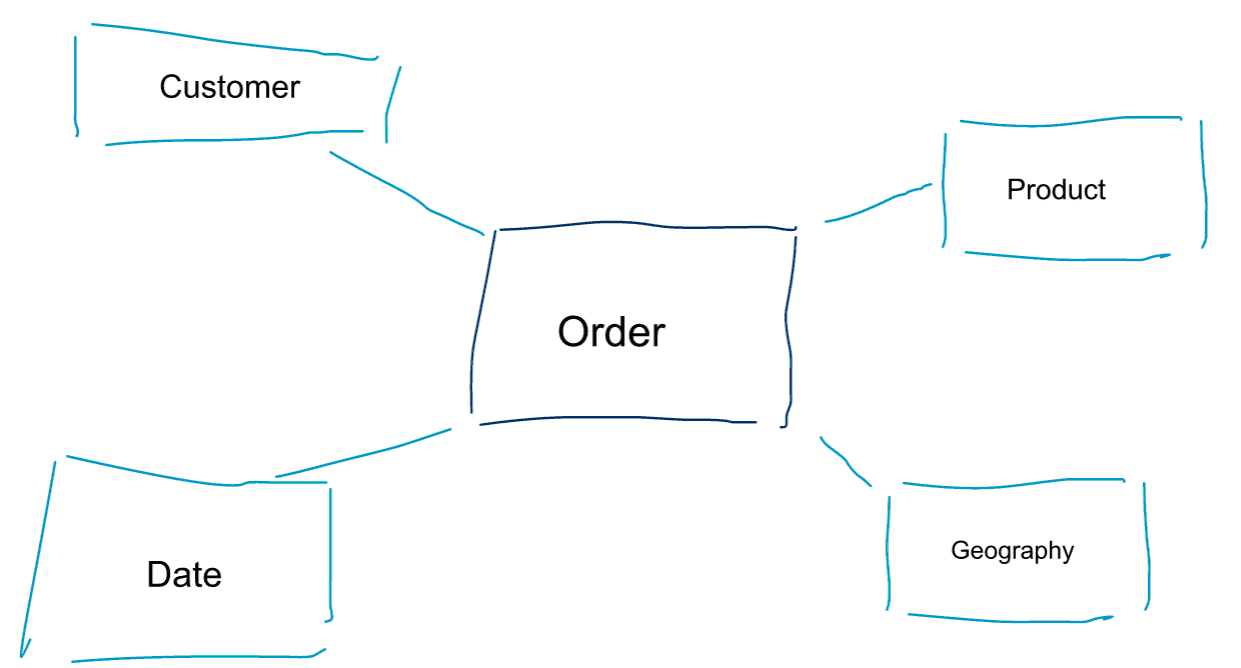
El modelado dimensional es un enfoque especial para modelar datos. También utilizamos las palabras data mart o star schema como sinónimos de un modelo dimensional. Los esquemas en estrella están optimizados para el análisis de datos. Eche un vistazo al modelo dimensional que aparece a continuación. Es bastante intuitivo de entender. Inmediatamente vemos cómo podemos cortar y dividir los datos de los pedidos por cliente, producto o fecha y medir el rendimiento del proceso de negocio de los pedidos agregando y comparando métricas.
Una de las ideas centrales sobre el modelado dimensional es definir el nivel más bajo de granularidad en un proceso de negocio transaccional. Cuando cortamos y cortamos los datos, este es el nivel de hoja a partir del cual no podemos profundizar más. Dicho de otro modo, el nivel más bajo de granularidad en un esquema de estrella es una unión del hecho con todas las tablas de dimensión sin ninguna agregación.
Modelado de datos frente a modelado dimensional
En el modelado de datos estándar pretendemos eliminar la repetición y la redundancia de los datos. Cuando se produce un cambio en los datos, sólo tenemos que cambiarlo en un lugar. Esto también ayuda a la calidad de los datos. Los valores no se desajustan en varios lugares. Eche un vistazo al siguiente modelo. Contiene varias tablas que representan conceptos geográficos. En un modelo normalizado tenemos una tabla distinta para cada entidad. En un modelo dimensional sólo tenemos una tabla: geografía. En esta tabla, las ciudades se repiten varias veces. Una vez por cada ciudad. Si el país cambia de nombre tenemos que actualizar el país en muchos lugares
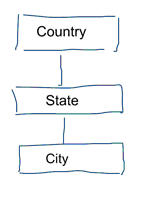
Nota: El modelado de datos normalizado también se conoce como modelado 3NF.
El enfoque estándar del modelado de datos no es adecuado para las cargas de trabajo de Business Intelligence. Muchas tablas dan lugar a muchas uniones. Las uniones ralentizan las cosas. En el análisis de datos los evitamos siempre que sea posible. En los modelos dimensionales desnormalizamos múltiples tablas relacionadas en una sola tabla, por ejemplo, las distintas tablas de nuestro ejemplo anterior pueden preunirse en una sola tabla: geografía.
Entonces, ¿por qué algunas personas afirman que el modelado dimensional está muerto?
Creo que estarás de acuerdo en que el modelado de datos en general y el modelado dimensional en particular es un ejercicio bastante útil. Entonces, ¿por qué algunas personas afirman que el modelado dimensional no es útil en la era del big data y de Hadoop?
Como puedes imaginar hay varias razones para ello.
El almacén de datos está muerto Confusión
En primer lugar, algunas personas confunden el modelado dimensional con el almacenamiento de datos. Afirman que el data warehousing está muerto y que, por lo tanto, el modelado dimensional también puede ser enviado al basurero de la historia. Este es un argumento lógicamente coherente. Sin embargo, el concepto de almacén de datos no está ni mucho menos obsoleto. Siempre necesitaremos datos integrados y fiables para rellenar nuestros cuadros de mando de BI. Si quieres saber más, te recomiendo nuestro curso de formación Big Data para profesionales de los almacenes de datos. En el curso entro en detalles y explico cómo el almacén de datos es tan relevante como siempre. También mostraré cómo las herramientas y tecnologías emergentes de big data son útiles para el almacenamiento de datos.

El malentendido del esquema en lectura
El segundo argumento que escucho con frecuencia es el siguiente. ‘Seguimos un enfoque de esquema en lectura y ya no necesitamos modelar nuestros datos’. En mi opinión, el concepto de esquema en lectura es uno de los mayores malentendidos en la analítica de datos. Estoy de acuerdo en que es útil almacenar inicialmente los datos en bruto en un volcado de datos que sea ligero en cuanto al esquema. Sin embargo, este argumento no debe utilizarse como excusa para no modelar los datos. El enfoque del esquema en la lectura no es más que una patada a la lata y una responsabilidad para los procesos posteriores. Alguien tiene que definir los tipos de datos. Todos y cada uno de los procesos que acceden al volcado de datos sin esquema tienen que averiguar por su cuenta lo que está pasando. Este tipo de trabajo se acumula, es completamente redundante, y se puede evitar fácilmente mediante la definición de tipos de datos y un esquema adecuado.
Denormalización revisada. Los aspectos físicos del modelo.
¿Existen realmente algunos argumentos válidos para declarar obsoletos los modelos dimensionales? En efecto, hay algunos argumentos mejores que los dos que he enumerado anteriormente. Requieren cierta comprensión del modelado físico de datos y de la forma en que funciona Hadoop. Tengan paciencia conmigo.
Antes mencioné brevemente una de las razones por las que modelamos nuestros datos dimensionalmente. Es en relación con la forma en que los datos se almacenan físicamente en nuestro almacén de datos. En el modelado de datos estándar, cada entidad del mundo real tiene su propia tabla. Lo hacemos para evitar la redundancia de datos y el riesgo de que los problemas de calidad de los datos se introduzcan en ellos. Cuantas más tablas tengamos, más uniones necesitaremos. Esa es la desventaja. Las uniones de tablas son caras, especialmente cuando unimos un gran número de registros de nuestros conjuntos de datos. Cuando modelamos los datos dimensionalmente, consolidamos varias tablas en una sola. Decimos que pre-unimos o desnormalizamos los datos. Ahora tenemos menos tablas, menos uniones y, como resultado, una menor latencia y un mejor rendimiento de las consultas.
Participa en la discusión de este post en LinkedIn
Llevar la desnormalización a su máxima expresión
¿Por qué no llevar la desnormalización a su máxima expresión? Deshacerse de todas las uniones y tener una sola tabla de hechos? De hecho, esto eliminaría la necesidad de cualquier unión por completo. Sin embargo, como puedes imaginar, tiene algunos efectos secundarios. En primer lugar, aumenta la cantidad de almacenamiento necesario. Ahora tenemos que almacenar un montón de datos redundantes. Con la llegada de los formatos de almacenamiento en columnas para el análisis de datos, esto es menos preocupante hoy en día. El mayor problema de la desnormalización es el hecho de que cada vez que cambia el valor de uno de los atributos tenemos que actualizar el valor en múltiples lugares – posiblemente miles o millones de actualizaciones. Una forma de evitar este problema es recargar completamente nuestros modelos cada noche. A menudo, esto será mucho más rápido y fácil que aplicar un gran número de actualizaciones. Las bases de datos columnares suelen adoptar el siguiente enfoque. Primero almacenan las actualizaciones de los datos en la memoria y las escriben de forma asíncrona en el disco.
Distribución de datos en una base de datos relacional distribuida (MPP)
Al crear modelos dimensionales en Hadoop, por ejemplo, Hive, SparkSQL, etc. necesitamos entender mejor una característica central de la tecnología que la distingue de una base de datos relacional distribuida (MPP) como Teradata, etc. Al distribuir los datos entre los nodos de una MPP tenemos control sobre la colocación de los registros. En función de nuestra estrategia de partición, por ejemplo, hash, lista, rango, etc., podemos ubicar las claves de los registros individuales en las fichas del mismo nodo. Con la co-localización de datos garantizada, nuestras uniones son súper rápidas ya que no necesitamos enviar ningún dato a través de la red. Vea el siguiente ejemplo. Los registros con el mismo ORDER_ID de las tablas ORDER y ORDER_ITEM terminan en el mismo nodo.
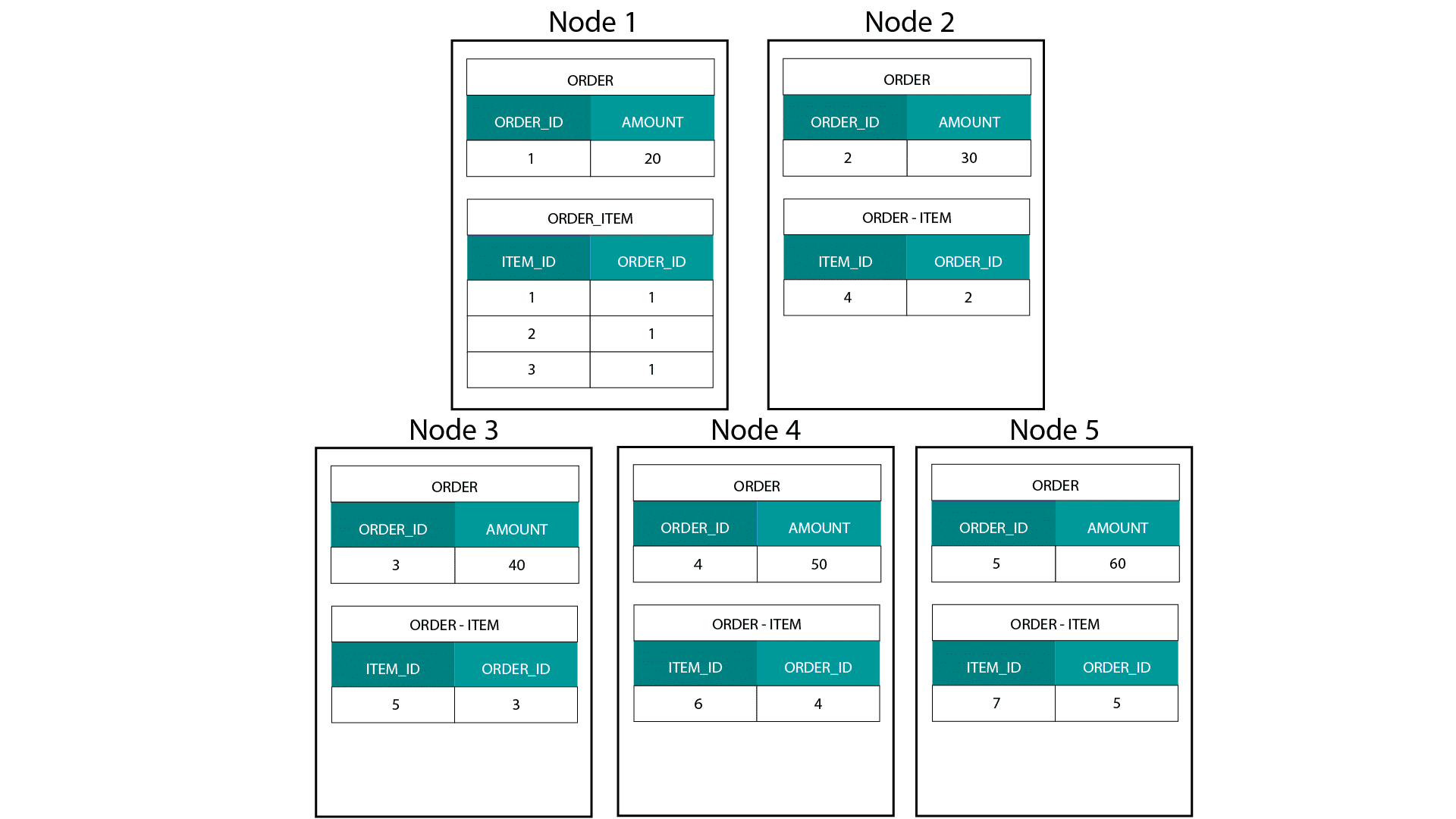
Las claves de order_id de la tabla order y order_item están co-localizadas en los mismos nodos.
Distribución de datos en Hadoop
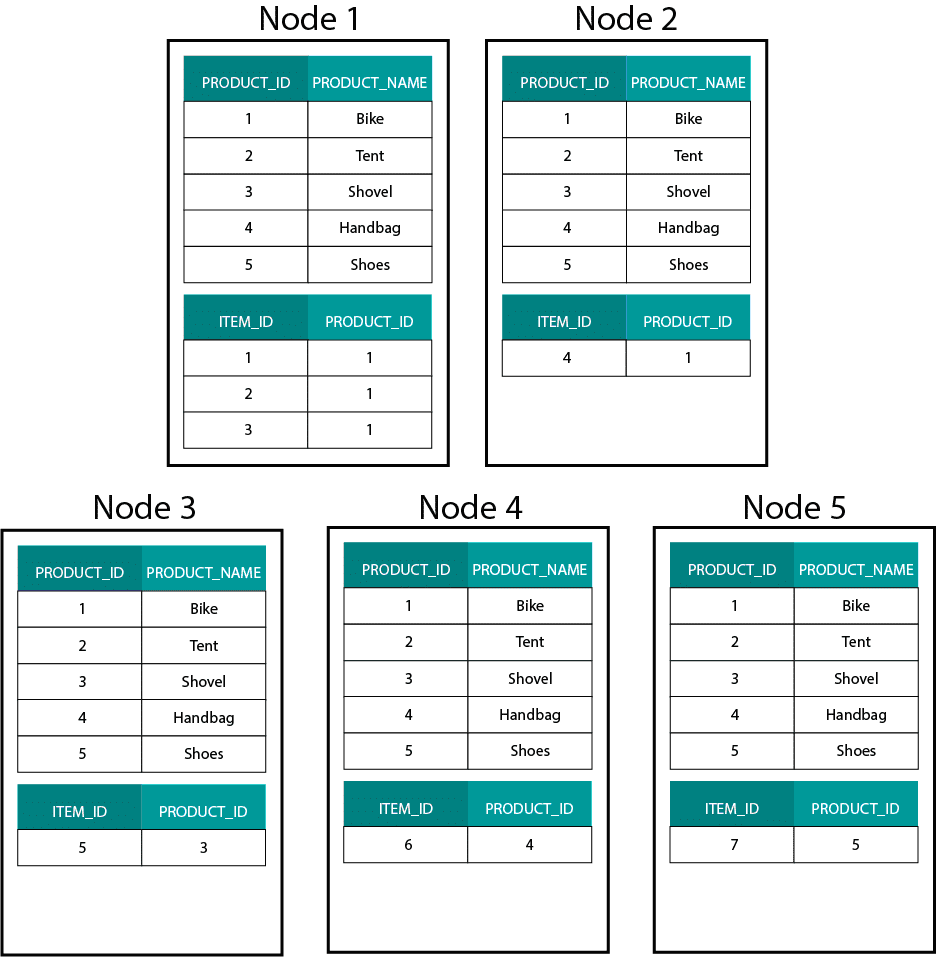
Esto es muy diferente de los sistemas basados en Hadoop. Allí dividimos nuestros datos en trozos de gran tamaño y los distribuimos y replicamos a través de nuestros nodos en el sistema de archivos distribuidos de Hadoop (HDFS). Con esta estrategia de distribución de datos no podemos garantizar la co-localidad de los datos. Mira el ejemplo de abajo. Los registros de la clave ORDER_ID terminan en diferentes nodos.
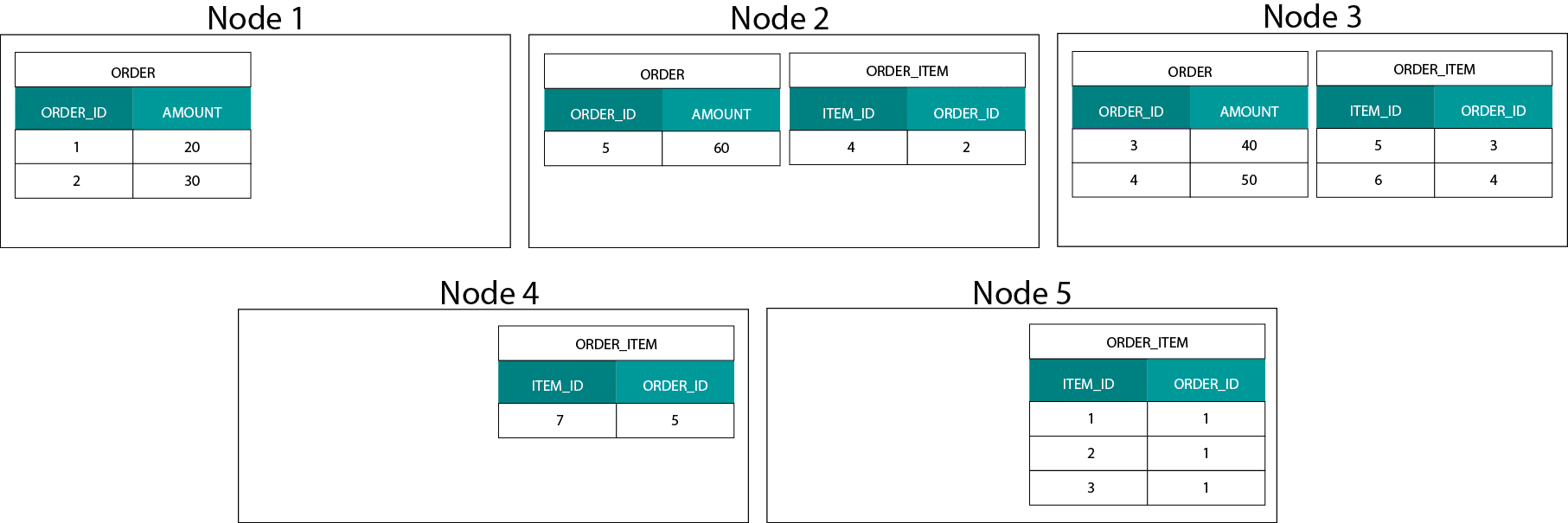
Para poder unir, necesitamos enviar los datos a través de la red, lo que impacta en el rendimiento.
Una estrategia para lidiar con este problema es replicar una de las tablas de unión a través de todos los nodos del clúster. Esto se llama broadcast join y utilizamos la misma estrategia en un MPP. Como puede imaginar, sólo funciona para tablas de búsqueda o de dimensiones pequeñas.
Entonces, ¿qué hacemos cuando tenemos una tabla de hechos grande y una tabla de dimensiones grande, por ejemplo, cliente o producto? O, de hecho, cuando tenemos dos tablas de hechos grandes.
Modelos dimensionales en Hadoop
Para sortear este problema de rendimiento podemos desnormalizar las tablas de dimensiones grandes en nuestra tabla de hechos para garantizar que los datos estén ubicados conjuntamente. Podemos difundir las tablas de dimensiones más pequeñas en todos nuestros nodos.
Para unir dos tablas de hechos grandes podemos anidar la tabla con la granularidad más baja dentro de la tabla con la granularidad más alta, por ejemplo, una tabla ORDER_ITEM grande anidada dentro de la tabla ORDER. Los motores de consulta modernos como Impala o Drill nos permiten aplanar estos datos

Esta estrategia de anidación de datos también es útil para los dolorosos conceptos de Kimball como las tablas puente para representar las relaciones M:N en un modelo dimensional.
Hadoop y las dimensiones que cambian lentamente
El almacenamiento en el sistema de archivos de Hadoop es inmutable. En otras palabras, sólo puedes insertar y añadir registros. No puedes modificar los datos. Si usted viene de un almacén de datos relacional fondo esto puede parecer un poco extraño al principio. Sin embargo, las bases de datos funcionan de forma similar. Almacenan todos los cambios en los datos en un registro inmutable de escritura (conocido en Oracle como redo log) antes de que un proceso actualice asincrónicamente los datos en los archivos de datos.
¿Qué impacto tiene la inmutabilidad en nuestros modelos dimensionales? Es posible que recuerde el concepto de Slowly Changing Dimensions (SCDs) de su curso de modelado dimensional. Las SCDs opcionalmente preservan la historia de los cambios en los atributos. Nos permiten informar de las métricas con respecto al valor de un atributo en un momento dado. Sin embargo, este no es el comportamiento por defecto. Por defecto, actualizamos las tablas de dimensiones con los últimos valores. ¿Cuáles son nuestras opciones en Hadoop? Recuerde. No podemos actualizar los datos. Podemos simplemente hacer que SCD sea el comportamiento por defecto y auditar cualquier cambio. Si queremos ejecutar informes con los valores actuales, podemos crear una vista sobre el SCD que sólo recupere el último valor. Esto puede hacerse fácilmente utilizando funciones de ventana. Alternativamente, podemos ejecutar un servicio llamado de compactación que crea físicamente una versión separada de la tabla de dimensiones con sólo los últimos valores.
Evolución del almacenamiento en Hadoop
Estas limitaciones de Hadoop no han pasado desapercibidas para los vendedores de las plataformas Hadoop. En Hive ahora tenemos transacciones ACID y tablas actualizables. Basándome en el número de problemas importantes abiertos y en mi propia experiencia, esta característica no parece estar lista para la producción todavía. Cloudera ha adoptado un enfoque diferente. Con Kudu han creado un nuevo formato de almacenamiento actualizable que no se encuentra en HDFS sino en el sistema de archivos local del sistema operativo. Se deshace de las limitaciones de Hadoop por completo y es similar a la capa de almacenamiento tradicional en un MPP columnar. En general, es mejor ejecutar cualquier caso de uso de BI y cuadros de mando en un MPP, por ejemplo, Impala + Kudu que en Hadoop. Dicho esto, los MPP tienen sus propias limitaciones en cuanto a resiliencia, concurrencia y escalabilidad. Cuando te encuentras con estas limitaciones, Hadoop y su primo cercano Spark son buenas opciones para las cargas de trabajo de BI. Cubrimos todas estas limitaciones en nuestro curso de formación Big Data for Data Warehouse Professionals y hacemos recomendaciones sobre cuándo usar un RDBMS y cuándo usar SQL en Hadoop/Spark.
El veredicto. ¿Son obsoletos los modelos dimensionales y los esquemas en estrella?
Todos sabemos que Ralph Kimball se ha retirado. Pero sus ideas y conceptos principales siguen siendo válidos y perduran. Tenemos que adaptarlos a las nuevas tecnologías y tipos de almacenamiento, pero siguen aportando valor.
Enseñame Big Data para avanzar en mi carrera
Lectura complementaria sobre el modelado dimensional en la era del Big Data
Tom Breur: El pasado y el futuro del modelado dimensional
Edosa Odaro: 5 consejos radicales para agilizar la integración de Big Data – El patrón anti almacén de datos