- La función y su derivada son monótonas
- La salida es cero «céntrica»
- La optimización es más fácil
- La derivada/diferencial de la función Tanh (f'(x)) estará entre 0 y 1.
Cons:
- La derivada de la función Tanh sufre el «problema del gradiente desvanecido y del gradiente explosivo».
- Lenta convergencia- ya que es computacionalmente pesada.(Razón de uso de la función matemática exponencial )
«Se prefiere Tanh sobre la función sigmoidea ya que está centrada en el cero y los gradientes no están restringidos a moverse en una dirección determinada»
3. Función de activación ReLu(ReLu – Unidades lineales rectificadas):


ReLU es la función de activación no lineal que ha ganado popularidad en la IA. La función ReLu también se representa como f(x) = max(0,x).
- La función y su derivada son monotónicas.
- Principal ventaja de usar la función ReLU- No activa todas las neuronas al mismo tiempo.
- Computacionalmente eficiente
- La derivada/diferencial de la función Tanh (f'(x)) será 1 si f(x) > 0 sino 0.
- Converge muy rápido
Cons:
- La función ReLu en no «cero-céntrica».Esto hace que las actualizaciones del gradiente vayan demasiado lejos en diferentes direcciones. 0 < salida < 1, y hace la optimización más difícil.
- La neurona muerta es el mayor problema.Esto se debe a la no diferenciación en cero.
«Problema de la neurona moribunda/neurona muerta : Como la derivada de ReLu f'(x) no es 0 para los valores positivos de la neurona (f'(x)=1 para x ≥ 0), ReLu no se satura (explota) y no se reportan neuronas muertas (Vanishing neuron). La saturación y el gradiente de fuga sólo se producen para los valores negativos que, dados a ReLu, se convierten en 0- Esto se llama el problema de la neurona muerta.»
4. Función de activación de ReLu con fugas:
La función ReLU permeable no es más que una versión mejorada de la función ReLU con la introducción de la «pendiente constante»


- Se define ReLU Leaky para abordar el problema de la neurona moribunda/neurona muerta.
- El problema de la neurona moribunda/neurona muerta se aborda mediante la introducción de una pequeña pendiente que tiene los valores negativos escalados por α permite que sus neuronas correspondientes «permanezcan vivas».
- La función y su derivada son ambas monotónicas
- Permite el valor negativo durante la propagación hacia atrás
- Es eficiente y fácil para el cálculo.
- La derivada de Leaky es 1 cuando f(x) > 0 y oscila entre 0 y 1 cuando f(x) < 0.
Cons:
- Leaky ReLU no proporciona predicciones consistentes para valores de entrada negativos.
5. Función de activación ELU (unidades lineales exponenciales):

- ELU también se propone para resolver el problema de la neurona moribunda.
- Sin problemas de ReLU moribundo
- Centrado en cero
Cons:
- Computacionalmente intensivo.
- Similar a Leaky ReLU, aunque teóricamente mejor que ReLU, actualmente no hay buena evidencia en la práctica de que ELU sea siempre mejor que ReLU.
- f(x) es monótona sólo si alfa es mayor o igual a 0.
- f'(x) derivada de ELU es monótona sólo si alfa está entre 0 y 1.
- Lenta convergencia debido a la función exponencial.
6. P ReLu (ReLU paramétrico) Función de activación:

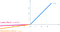
- La idea de ReLU con fugas puede ampliarse aún más.
- En lugar de multiplicar x con un término constante podemos multiplicarlo con un «hiperparámetro (parámetro a-entrenable)» que parece funcionar mejor el ReLU con fugas. Esta extensión de ReLU con fugas se conoce como ReLU paramétrico.
- El parámetro α es generalmente un número entre 0 y 1, y generalmente es relativamente pequeño.
- Tiene una ligera ventaja sobre Leaky Relu debido al parámetro entrenable.
- Maneja el problema de la neurona moribunda.
Cons:
- Igual que el Relu con fugas.
- f(x) es monótona cuando a> o =0 y f'(x) es monótona cuando a =1
7. Función de activación Swish (A Self-Gated):(Unidad lineal sigmoide)

- El equipo de Google Brain ha propuesto una nueva función de activación, denominada Swish, que es simplemente f(x) = x – sigmoide(x).
- Sus experimentos muestran que Swish tiende a funcionar mejor que ReLU en modelos más profundos a través de una serie de conjuntos de datos difíciles.
- La curva de la función Swish es suave y la función es diferenciable en todos los puntos. Esto es útil durante el proceso de optimización del modelo y se considera una de las razones por las que Swish supera a ReLU.
- La función Swish es «no monótona». Esto significa que el valor de la función puede disminuir incluso cuando los valores de entrada son crecientes.
- La función es no acotada por arriba y acotada por abajo.
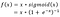
«Swish tiende a igualar o superar continuamente la ReLu»
Nótese que la salida de la función swish puede disminuir incluso cuando la entrada aumenta. Esta es una característica interesante y específica de swish.(Debido al carácter no monotónico)
f(x)=2x*sigmoide(beta*x)
Si pensamos que beta=0 es una versión simple de Swish, que es un parámetro aprendible, entonces la parte sigmoide es siempre 1/2 y f (x) es lineal. En cambio, si la beta es un valor muy grande, la sigmoide se convierte en una función casi de dos dígitos (0 para x<0,1 para x>0). Así, f (x) converge a la función ReLU. Por lo tanto, la función Swish estándar se selecciona como beta = 1. De esta manera, se proporciona una interpolación suave (asociando los conjuntos de valores variables con una función en el rango dado y la precisión deseada). ¡Excelente! Se ha encontrado una solución al problema de la desaparición de los gradientes.
8.Softplus
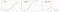
La función softplus es similar a la función ReLU, pero es relativamente más suave.Función de Softplus o SmoothRelu f(x) = ln(1+exp x).
La derivada de la función Softplus es f'(x) es una función logística (1/(1+exp x)).
El valor de la función oscila entre (0, + inf).Tanto f(x) como f'(x) son monotónicas.
9.Softmax o función exponencial normalizada:

La función «softmax» es también un tipo de función sigmoidea pero es muy útil para manejar problemas de clasificación multiclase.
«Softmax puede describirse como la combinación de múltiples funciones sigmoidales.»
«La función Softmax devuelve la probabilidad de que un punto de datos pertenezca a cada clase individual.»
Al construir una red para un problema multiclase, la capa de salida tendría tantas neuronas como el número de clases en el objetivo.
Por ejemplo, si tiene tres clases, habría tres neuronas en la capa de salida. Supongamos que obtuvimos la salida de las neuronas como .Aplicando la función softmax sobre estos valores, obtendremos el siguiente resultado – . Estos representan la probabilidad de que el punto de datos pertenezca a cada clase. A partir del resultado podemos que la entrada pertenece a la clase A.
«Observe que la suma de todos los valores es 1.»
¿Cuál es mejor usar? ¿Cómo elegir la correcta?
Para ser honestos, no hay una regla dura y rápida para elegir la función de activación.No podemos diferenciar entre la función de activación.Cada función de activación como sus propios pros y contras.Todo lo bueno y lo malo se decidirá sobre la base de la pista.
Pero sobre la base de las propiedades del problema que podría ser capaz de hacer una mejor elección para la convergencia fácil y más rápido de la red.
- Las funciones sigmoides y sus combinaciones suelen funcionar mejor en el caso de los problemas de clasificación
- Los sigmoides y las funciones tanh se evitan a veces debido al problema del gradiente de fuga
- La función de activación ReLU es muy utilizada en la era moderna.
- En caso de que haya neuronas muertas en nuestras redes debido a ReLu, la función ReLU con fugas es la mejor opción
- La función ReLU sólo debe utilizarse en las capas ocultas
«Como regla general, se puede empezar utilizando la función ReLU y luego pasar a otras funciones de activación en caso de que ReLU no proporcione resultados óptimos»
.