Revisado: 11 de diciembre de 2020
¿Dicen los sujetos la verdad?
La fiabilidad de los datos de autoinforme es un talón de Aquiles de la investigación con encuestas. Por ejemplo, los sondeos de opinión indican que más del 40% de los estadounidenses asisten a la iglesia cada semana. Sin embargo, al examinar los registros de asistencia a la iglesia, Hadaway y Marlar (2005) concluyeron que la asistencia real era inferior al 22%. En su obra seminal «Todo el mundo miente», Seth Stephens-Davidowitz (2017) encontró amplias pruebas para demostrar que la mayoría de la gente no hace lo que dice y no dice lo que hace. Por ejemplo, en respuesta a las encuestas, la mayoría de los votantes declaran que la etnia del candidato no es importante. Sin embargo, al comprobar los términos de búsqueda en Google, Sephens-Davidowitz descubrió lo contrario. En concreto, cuando los usuarios de Google introducían la palabra «Obama», siempre asociaban su nombre con algunas palabras relacionadas con la raza.
Para la investigación sobre la instrucción basada en la web, los datos de uso de la web pueden obtenerse analizando el registro de acceso del usuario, configurando cookies o cargando la caché. Sin embargo, estas opciones pueden tener una aplicabilidad limitada. Por ejemplo, el registro de acceso del usuario no puede rastrear a los usuarios que siguen enlaces a otros sitios web. Además, los enfoques de cookies o caché pueden plantear problemas de privacidad. En estas situaciones, se utilizan datos autodeclarados recogidos mediante encuestas. Esto da lugar a la pregunta: ¿Cuál es la precisión de los datos autodeclarados? Cook y Campbell (1979) han señalado que los sujetos (a) tienden a informar de lo que creen que el investigador espera ver, o (b) informan de lo que refleja positivamente sus propias habilidades, conocimientos, creencias u opiniones. Otra preocupación sobre estos datos se centra en si los sujetos son capaces de recordar con precisión comportamientos pasados. Los psicólogos han advertido que la memoria humana es falible (Loftus, 2016; Schacter, 1999). A veces las personas «recuerdan» hechos que nunca ocurrieron. Por lo tanto, la fiabilidad de los datos autodeclarados es tenue.Aunque los paquetes de software estadístico son capaces de calcular números de hasta 16-32 decimales, esta precisión no tiene sentido si los datos no pueden ser exactos ni siquiera a nivel de enteros. Algunos estudiosos han advertido a los investigadores de que el error de medición puede paralizar el análisis estadístico (Blalock, 1974) y han sugerido que las buenas prácticas de investigación requieren el examen de la calidad de los datos recogidos (Fetter, Stowe, & Owings, 1984).
Sesgo y varianza
Los errores de medición incluyen dos componentes, a saber, el sesgo y el error variable. Por ejemplo, se ha descubierto que varias versiones de los tests de CI tienen un sesgo contra los no blancos. Esto significa que los negros y los hispanos tienden a recibir puntuaciones más bajas, independientemente de su inteligencia real. Un error variable, también conocido como varianza, tiende a ser aleatorio. En otras palabras, las puntuaciones comunicadas podrían estar por encima o por debajo de las puntuaciones reales (Salvucci, Walter, Conley, Fink, & Saba, 1997).
Los resultados de estos dos tipos de errores de medición tienen implicaciones diferentes. Por ejemplo, en un estudio en el que se compararon los datos autodeclarados de altura y peso con los datos medidos directamente (Hart & Tomazic, 1999), se descubrió que los sujetos tienden a sobredeclarar su altura pero a infravalorar su peso. Obviamente, este tipo de patrón de error es un sesgo más que una varianza. Una posible explicación de este sesgo es que la mayoría de la gente quiere presentar una mejor imagen física a los demás. Sin embargo, si el error de medición es aleatorio, la explicación puede ser más complicada.
Uno puede argumentar que los errores variables, que son de naturaleza aleatoria, se anularían entre sí y, por lo tanto, podrían no ser una amenaza para el estudio. Por ejemplo, el primer usuario puede sobrestimar sus actividades en Internet en un 10%, pero el segundo usuario puede subestimar las suyas en un 10%. En este caso, la media podría seguir siendo correcta. Sin embargo, la sobreestimación y la subestimación aumentan la variabilidad de la distribución. En muchas pruebas paramétricas, la variabilidad dentro del grupo se utiliza como término de error. Una variabilidad inflada afectaría sin duda a la significación de la prueba. Algunos textos pueden reforzar esta idea errónea. Por ejemplo, Deese (1972) dijo:
La teoría estadística nos dice que la fiabilidad de las observaciones es proporcional a la raíz cuadrada de su número. Cuantas más observaciones haya, más influencias aleatorias habrá. Y la teoría estadística sostiene que cuantos más errores aleatorios haya, más probabilidades habrá de que se anulen unos a otros y produzcan una distribución normal (p.55).
En primer lugar, es cierto que a medida que aumenta el tamaño de la muestra disminuye la varianza de la distribución, pero esto no garantiza que la forma de la distribución se aproxime a la normalidad. En segundo lugar, la fiabilidad (la calidad de los datos) debería estar vinculada a la medición y no a la determinación del tamaño de la muestra. Un tamaño de muestra grande con muchos errores de medición, incluso errores aleatorios, inflaría el término de error para las pruebas paramétricas.
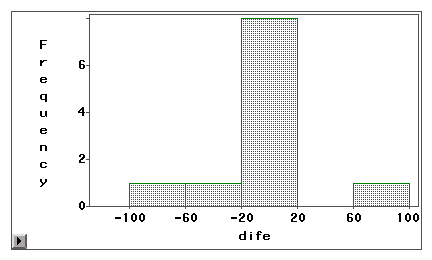
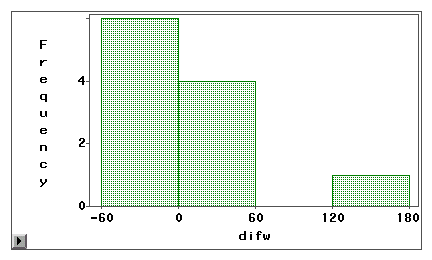
Se puede utilizar un gráfico de tallo y hoja o un histograma para examinar visualmente si un error de medición se debe a un sesgo sistemático o a una varianza aleatoria. En el siguiente ejemplo, se miden dos tipos de acceso a Internet (navegación por la web y correo electrónico) mediante una encuesta autodeclarada y un libro de registro. Las puntuaciones de diferencia (medición 1 – medición 2) se representan en los siguientes histogramas.
El primer gráfico revela que la mayoría de las puntuaciones de diferencia se centran en torno a cero. La infradeclaración y la sobredeclaración que aparecen cerca de ambos extremos sugieren que el error de medición es un error aleatorio más que un sesgo sistemático.
El segundo gráfico indica claramente que hay un alto grado de errores de medición porque muy pocas puntuaciones de diferencia están centradas en torno a cero. Además, la distribución está sesgada negativamente y, por tanto, el error es el sesgo en lugar de la varianza.
¿Cómo de fiable es nuestra memoria?
Schacter (1999) advirtió que la memoria humana es falible. Hay siete defectos de nuestra memoria:
- Transitoriedad: Disminución de la accesibilidad de la información a lo largo del tiempo.
- Ausencia de atención: Procesamiento desatento o superficial que contribuye a la debilidad de los recuerdos.
- Bloqueo: La inaccesibilidad temporal de la información que se almacena en la memoria.
- Atribución errónea Atribuir un recuerdo o idea a la fuente equivocada.
- Sugestionabilidad: Recuerdos que se implantan como resultado de preguntas o expectativas dirigidas.
- Sesgo: Distorsiones retrospectivas e influencias inconscientes que están relacionadas con los conocimientos y creencias actuales.
- Persistencia: Recuerdos patológicos: información o acontecimientos que no podemos olvidar, aunque deseemos hacerlo.
 |
«No tengo recuerdos de esto. No recuerdo que haya firmado el documento paraWhitewater. No recuerdo por qué el documento desapareció pero reapareció después. No recuerdo nada» «Recuerdo haber aterrizado (en Bosnia) bajo el fuego de los francotiradores. Se suponía que iba a haber una especie de ceremonia de bienvenida en el aeropuerto, pero en su lugar sólo corrimos con la cabeza gacha para entrar en los vehículos y llegar a nuestra base». Durante la investigación sobre el envío de información clasificada a través de un servidor de correo electrónico personal, Clinton dijo al FBI que no podía «recordar» o «recordar» nada 39 veces. Precaución: Se ha descubierto un nuevo virus informático llamado «Clinton». Si el ordenador está infectado, aparecerá con frecuencia este mensaje ‘out of memory’ (sin memoria), incluso si tiene suficienteRAM. |
| P: «Si Vernon Jordon nos ha dicho que usted tiene una memoria extraordinaria, una de las más grandes que ha visto en un político, ¿le importaría rebatir esto?»
A: «Sí tengo buena memoria… Pero no recuerdo si estuve a solas con Monica Lewinsky o no. ¿Cómo podría llevar la cuenta de tantas mujeres en mi vida?» Por qué Clinton recomendó a Lewinsky para un trabajo en Revlon? A: Él sabía que ella sería buena inventando cosas. |
 |
Es importante señalar que a veces la fiabilidad de nuestra memoria está ligada a la conveniencia del resultado. Por ejemplo, cuando un investigador médico intenta recoger datos relevantes de madres cuyos bebés están sanos y de madres cuyos hijos tienen malformaciones, los datos de las segundas suelen ser más precisos que los de las primeras. Esto se debe a que las madres de bebés con malformaciones han revisado cuidadosamente todas las enfermedades que se produjeron durante el embarazo, todos los medicamentos que se tomaron y todos los detalles relacionados directa o remotamente con la tragedia, en un intento de encontrar una explicación. Por el contrario, las madres de bebés sanos no prestan mucha atención a la información anterior (Aschengrau & SeageIII, 2008). Inflar el promedio es otro ejemplo de cómo la deseabilidad afecta a la precisión de la memoria y a la integridad de los datos. En algunas situaciones hay una diferencia de género en la inflación de la GPA. Un estudio realizado por Caskie etal. (2014) descubrió que dentro del grupo de estudiantes universitarios con un GPA más bajo, las mujeres eran más propensas a informar de un GPA más alto que el real que los hombres.
Para contrarrestar el problema de los errores de memoria, algunos investigadoressugirieron recoger datos relacionados con el pensamiento o sentimiento momentáneo del participante, en lugar de pedirle que recuerde eventos remotos (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Los siguientes ejemplos son ítems de encuestas del Programme forInternational Student Assessment de 2018: «¿Te trataron con respeto todo el día de ayer?». «¿Sonrió o se rió mucho ayer?». «¿Aprendiste o hiciste algo interesante ayer?». (Organización para la Cooperación y el Desarrollo Económico, 2017). Sin embargo, la respuesta depende de lo que le haya sucedido al participante en torno a ese momento concreto, que puede no ser típico. En concreto, aunque el encuestado no sonriera o se riera mucho ayer, no implica necesariamente que el encuestado sea siempre infeliz.
¿Qué hacemos?
Algunos investigadores rechazan el uso de datos autoinformados debido a su supuesta mala calidad. Por ejemplo, cuando un grupo de investigadores investigó si la alta religiosidad conducía a una menor adhesión a las directivas de refugio en los EE.UU. durante la pandemia de COVID19, utilizaron el número de congregaciones por cada 10.000 residentes como una medida aproximada de la religiosidad de la región, en lugar de la religiosidad autodeclarada, que tiende a reflejar la deseabilidad social (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Sin embargo, Chan (2009) argumentó que la supuesta mala calidad de los datos autodeclarados no es más que una leyenda urbana. Impulsados por la deseabilidad social, los encuestados pueden proporcionar a los investigadores datos inexactos en algunas ocasiones, pero no ocurre siempre. Por ejemplo, es poco probable que los encuestados mientan sobre sus datos demográficos, como el sexo y la etnia. En segundo lugar, si bien es cierto que los encuestados tienden a falsear sus respuestas en los estudios experimentales, este problema es menos grave en las medidas utilizadas en los estudios de campo y en los entornos naturalistas. Además, existen numerosas medidas autodeclaradas bien establecidas de diferentes constructos psicológicos, que han obtenido pruebas de validez de constructo a través de la validación convergente y discriminante. Por ejemplo, los cinco grandes rasgos de personalidad, la personalidad proactiva, la disposición afectiva, la autoeficacia, las orientaciones de objetivos, el apoyo organizativo percibido y muchos otros.En el campo de la epidemiología, Khoury, James y Erickson (1994) afirmaron que el efecto del sesgo de recuerdo está sobrevalorado. A pesar de la amenaza de inexactitud de los datos, es imposible que el investigador siga a todos los sujetos con una videocámara y grabe todo lo que hacen. No obstante, el investigador puede utilizar un subconjunto de sujetos para obtener datos observados, como el registro de acceso de los usuarios o el registro diario de acceso a la web. Los resultados se compararían con el resultado de los datos autodeclarados por todos los sujetos para estimar el error de medición.Por ejemplo,
- Cuando el investigador disponga del registro de acceso del usuario, puede pedir a los sujetos que informen de la frecuencia de su acceso al servidor web.Los sujetos no deben ser informados de que sus actividades en Internet han sido registradas por el webmaster, ya que esto puede afectar al comportamiento de los participantes.
- El investigador puede pedir a un subconjunto de usuarios que lleven un diario de sus actividades en Internet durante un mes. Después, se pide a los mismos usuarios que rellenen una encuesta sobre su uso de la web.
Alguien puede argumentar que el enfoque del libro de registro es demasiado exigente. De hecho, en muchos estudios de investigación científica, se pide a los sujetos mucho más que eso. Por ejemplo, cuando los científicos estudiaron cómo el sueño profundo durante los viajes espaciales de largo alcance afectaría a la salud humana, se pidió a los participantes que permanecieran en la cama durante un mes. En un estudio sobre cómo un entorno cerrado afecta a la psicología humana durante los viajes espaciales, también se encerró a los sujetos en una habitación de forma individual durante un mes. Después de recopilar diferentes fuentes de datos, se puede analizar la discrepancia entre los datos registrados y los autodeclarados para estimar la fiabilidad de los datos. A primera vista, este enfoque parece una fiabilidad test-retest, pero no lo es. En primer lugar, en la fiabilidad test-retest el instrumento utilizado en dos o más situaciones debe ser el mismo. En segundo lugar, cuando la fiabilidad test-retest es baja, la fuente de errores está dentro del instrumento. Sin embargo, cuando la fuente de errores es externa al instrumento, como los errores humanos, la fiabilidad entre evaluadores es más apropiada.
El procedimiento sugerido anteriormente puede conceptualizarse como una medición de la fiabilidad entre datos, que se asemeja a la fiabilidad entre evaluadores y a las medidas repetidas. Existen cuatro formas de estimar la fiabilidad entre evaluadores, a saber, el coeficiente Kappa, el índice de inconsistencia, el ANOVA de medidas repetidas y el análisis de regresión. La siguiente sección describe cómo estas medidas de fiabilidad entre evaluadores pueden utilizarse como medidas de fiabilidad entre datos.
Coeficiente Kappa
En la investigación psicológica y educativa, no es inusual emplear dos o más evaluadores en el proceso de medición cuando la evaluación implica juicios subjetivos (por ejemplo, la calificación de ensayos). La fiabilidad entre evaluadores, que se mide mediante el coeficiente Kappa, se utiliza para indicar la fiabilidad de los datos; por ejemplo, el rendimiento de los participantes es calificado por dos o más evaluadores como «maestro» o «no maestro» (1 o 0). Por lo tanto, esta medida suele calcularse en procedimientos de análisis de datos categóricos como PROC FREQ en SAS, la «medida de acuerdo» en SPSS o una calculadora Kappa en línea (Lowry, 2016). La imagen de abajo es una captura de pantalla de la calculadora en línea de Vassarstats.
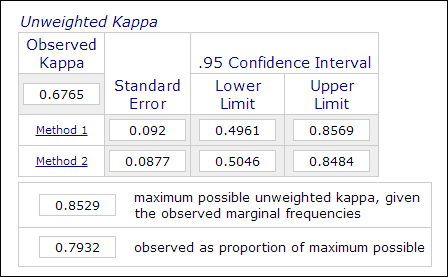
Es importante tener en cuenta que incluso si el 60 por ciento de dos conjuntos de datos coinciden entre sí, no significa que las mediciones sean fiables.Dado que el resultado es dicotómico, hay un 50 por ciento de posibilidades de que las dos mediciones coincidan. El coeficiente Kappa tiene esto en cuenta y exige un mayor grado de coincidencia para alcanzar la coherencia.
En el contexto de la instrucción basada en la web, cada categoría de uso del sitio web autodeclarado puede recodificarse como una variable binaria. Por ejemplo, cuando la primera pregunta es «¿con qué frecuencia utiliza telnet?», las posibles respuestas categóricas son «a: a diario», «b: de tres a cinco veces por semana», «c: de tres a cinco veces por mes», «d: rara vez» y «e: nunca». En este caso, las cinco categorías pueden recodificarse en cinco variables: Q1A, Q1B, Q1C, Q1D y Q1E. Con esta estructura de datos, las respuestas pueden codificarse como «1» o «0» y, por tanto, es posible medir la concordancia de la clasificación. La concordancia puede calcularse mediante el coeficiente Kappa y, por tanto, puede estimarse la fiabilidad de los datos.
Sujetos Datos del libro de registro Datos dedatos del informe Sujeto 1 1 1 Sujeto 2 0 0 Sujeto 3 1 0 Sujeto 4 0 1 Índice de inconsistencia
Otra forma de calcular los datos categóricos mencionados es el Índice de inconsistencia (IOI). En el ejemplo anterior, debido a que hay dos mediciones (datos de registro y autoinforme) y cinco opciones en la respuesta, se forma una tabla de 4 x 4. El primer paso para calcular el IOI es dividir la tabla RXC en varias sub-tablas 2X2. Por ejemplo, la última opción «nunca» se trata como una categoría y todas las demás se agrupan en otra categoría como «no nunca», como se muestra en la siguiente tabla.
Autodatosdatos Log Nunca Nunca Total Nunca a b a+b Nunca c d c+d Total a+c b+d n=Suma(a-d) El porcentaje de IOI se calcula mediante la siguiente fórmula:
Porcentaje de IOI = 100*(b+c)/ donde p = (a+c)/n
Una vez calculado el IOI para cada subtabla 2X2, se utiliza una media de todos los índices como indicador de la inconsistencia de la medida. El criterio para juzgar si los datos son coherentes es el siguiente:
- Un IOI inferior a 20 es una varianza baja
- Un IOI entre 20 y 50 es una varianza moderada
- Un IOI superior a 50 es una varianza alta
La fiabilidad de los datos se expresa en esta ecuación: r = 1 – IOI
Coeficiente de correlación intraclase
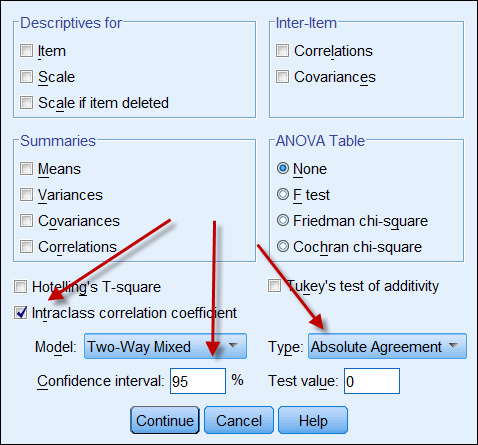
Si ambas fuentes de datos producen datos continuos, entonces se puede calcular el coeficiente de correlación intraclase para indicar la fiabilidad de los datos. La siguiente es una captura de pantalla de las opciones de CCI de SPSS. En el tipohay dos opciones: «consistencia» y «acuerdo absoluto». Si se elige «consistencia», aunque un conjunto de números tenga una consistencia alta (por ejemplo, 9, 8, 9, 8, 7…) y el otro tenga una consistencia baja (por ejemplo, 4,3, 4, 3, 2…), su fuerte correlación da a entender que los datos están alineados entre sí. Por lo tanto, es aconsejable elegir «acuerdo absoluto».
Medidas repetidas
La medición de la fiabilidad entre datos también puede conceptualizarse y procederse como un ANOVA de medidas repetidas. En un ANOVA de medidas repetidas, las mediciones se dan a los mismos sujetos varias veces, como la prueba previa, la prueba intermedia y la prueba posterior. En este contexto, los sujetos también se miden repetidamente mediante el registro de usuarios de la web, el libro de registro y la encuesta autoinformada. El siguiente es el código SAS para un ANOVA de medidas repetidas:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
En el programa anterior, el número de sitios web visitados por nueve voluntarios se registra en el registro de acceso del usuario, el libro de registro personal y la encuesta autodeclarada. Los usuarios se tratan como un factor entre sujetos, mientras que las tres medidas se consideran un factor entre medidas. El siguiente es un resultado condensado:
Fuente de variación DF Cuadrado medio Entre sujetos (usuario) 8 10442.50 Entre-medida (tiempo) 2 488,93 Residual 16 454.80 A partir de la información anterior, el coeficiente de fiabilidad puede calcularse mediante esta fórmula (Fisher, 1946; Horst, 1949):
r = MS entre medidas – MSresidual ————————————————————– MSentre medidas + (dfentre personas X MSresidual) Introduzcamos el número en la fórmula:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) La fiabilidad es de aproximadamente 0,0008, que es extremadamente baja. Por lo tanto, podemos irnos a casa y olvidarnos de los datos. Afortunadamente, sólo se trata de un conjunto de datos hipotéticos. Pero, ¿y si se trata de un conjunto de datos reales? Hay que ser lo suficientemente duro como para renunciar a unos datos deficientes en lugar de publicar unos resultados que no son en absoluto fiables.
Análisis correlacional y de regresión
El análisis correlacional, que utiliza el coeficiente de producto-momento de Pearson, es muy sencillo y especialmente útil cuando las escalas de dos mediciones no son las mismas. Por ejemplo, el registro del servidor web puede rastrear el número de accesos a páginas, mientras que los datos autodeclarados tienen una escala de tipo Likert (por ejemplo, ¿Con qué frecuencia navega por Internet? 5=muy a menudo, 4=a menudo, 3=algunas veces, 2=poco, 5=nunca). En este caso, las puntuaciones autodeclaradas pueden utilizarse como predictor para hacer una regresión con respecto al acceso a la página.
Un enfoque similar es el análisis de regresión, en el que un conjunto de puntuaciones (por ejemplo, los datos de la encuesta) se trata como el predictor, mientras que otro conjunto de puntuaciones (por ejemplo, el registro diario del usuario) se considera la variable dependiente. Si se emplean más de dos medidas, puede aplicarse un modelo de regresión múltiple, es decir, la que produce un resultado más preciso (por ejemplo, el registro de acceso de los usuarios de la web) se considera la variable dependiente y todas las demás medidas (por ejemplo, el registro diario de los usuarios, los datos de la encuesta) se tratan como variables independientes.
Referencia
- Aschengrau, A., & Seage III, G. (2008). Fundamentos de epidemiología en salud pública. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) Measurement in the social sciences: Theories and strategies. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Precisión del GPA universitario autoinformado: Diferencias moderadas por el género según el nivel de logro y la autoeficacia académica. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Entonces, ¿por qué preguntarme? Son los datos de autoinforme realmente tan malos? En Charles E. Lance y Robert J. Vandenberg (Eds.), Statistical and methodological myths and urban legends: Doctrina, verdad y fábula en las ciencias organizativas y sociales (pp309-335). Nueva York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-experimentation: Design and analysis issues. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validez y fiabilidad del método de muestreo de experiencias. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). La psicología como ciencia y arte. Nueva York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, 10 de agosto). La religión y la reacción a las directrices de COVID-19mitigation. American Psychologist. Publicación anticipada en línea. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., &Owings, J. (1984). High School and Beyond. A national longitudinal study for the 1980s, quality of responses of high school students to questionnaire items. (NCES 84-216).Washington, D. C.: Departamento de Educación de los Estados Unidos. Office of EducationalResearch and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). La validez incremental de los autoinformes de estado promedio sobre los autoinformes globales de personalidad. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statistical methods for research workers (10ª ed.). Edimburgo, Reino Unido: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). ¿Cuántos estadounidenses asisten al culto cada semana? ¿Un enfoque alternativo para la medición? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 agosto). Comparación de las distribuciones de percentiles para medidas antropométricas entre tres conjuntos de datos. Documento presentado en la Annual Joint Statistical Meeting, Baltimore, MD.
- Horst, P. (1949). A Generalized expression for the reliability of measures. Psychometrika, 14, 21-31.
- Khoury, M., James, L., &Erikson, J. (1994). On theuse of affected controls to address recall bias in case-control studiesof birth defects. Teratology, 49, 273-281.
- Loftus, E. (2016, abril). La ficción de la memoria. Ponencia presentada en la Convención de la Asociación de Psicología del Oeste. Long Beach, CA.
- Lowry, R. (2016). Kappa como medida de concordancia en la clasificación categórica. Recuperado de http://vassarstats.net/kappa.html
- Organización para la Cooperación y el Desarrollo Económico. (2017). Cuestionario de bienestar para PISA 2018. París: Autor. Recuperado de https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). Los siete pecados de la memoria: Insights from psychology and cognitive neuroscience. American Psychology, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Measurement error studies at the National Center for Education Statistics. Washington D. C.: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Todo el mundo miente: Big data, new data, and what the Internet can tell us about who we really are. New York, NY: Dey Street Books.
 Subir al menú principal
Subir al menú principal Otros cursosMotor de búsqueda
|

Contacta conmigo
|