Cuando hablamos de la predicción de un modelo, es importante entender los errores de predicción (sesgo y varianza). Existe un compromiso entre la capacidad de un modelo para minimizar el sesgo y la varianza. Comprender adecuadamente estos errores nos ayudará no sólo a construir modelos precisos, sino también a evitar el error de sobreajuste y de infraajuste.
Así que empecemos con los fundamentos y veamos cómo marcan la diferencia en nuestros modelos de aprendizaje automático.
¿Qué es el sesgo?
El sesgo es la diferencia entre la predicción media de nuestro modelo y el valor correcto que intentamos predecir. Un modelo con un sesgo elevado presta muy poca atención a los datos de entrenamiento y simplifica en exceso el modelo. Siempre conduce a un alto error en los datos de entrenamiento y de prueba.
¿Qué es la varianza?
La varianza es la variabilidad de la predicción del modelo para un punto de datos dado o un valor que nos indica la dispersión de nuestros datos. Los modelos con alta varianza prestan mucha atención a los datos de entrenamiento y no generalizan en los datos que no han visto antes. Como resultado, tales modelos funcionan muy bien en los datos de entrenamiento pero tienen altas tasas de error en los datos de prueba.
Matemáticamente
Dejemos la variable que estamos tratando de predecir como Y y otras covariables como X. Suponemos que existe una relación entre ambas tal que
Y=f(X) + e
Donde e es el término de error y se distribuye normalmente con una media de 0.
Haremos un modelo f^(X) de f(X) utilizando la regresión lineal o cualquier otra técnica de modelización.
Así que el error cuadrático esperado en un punto x es
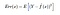
El Err(x) puede descomponerse además como

Err(x) es la suma de Bias², la varianza y el error irreducible.
El error irreducible es el error que no se puede reducir creando buenos modelos. Es una medida de la cantidad de ruido en nuestros datos. Aquí es importante entender que no importa lo bueno que hagamos nuestro modelo, nuestros datos tendrán cierta cantidad de ruido o error irreducible que no puede ser eliminado.
Bias y varianza utilizando el diagrama de la diana

En el diagrama anterior, el centro de la diana es un modelo que predice perfectamente los valores correctos. A medida que nos alejamos de la diana, nuestras predicciones son cada vez peores. Podemos repetir nuestro proceso de construcción de modelos para obtener otros aciertos en la diana.
En el aprendizaje supervisado, el infraajuste se produce cuando un modelo es incapaz de capturar el patrón subyacente de los datos. Estos modelos suelen tener un sesgo alto y una varianza baja. Ocurre cuando tenemos muy pocos datos para construir un modelo preciso o cuando intentamos construir un modelo lineal con datos no lineales. Además, este tipo de modelos son muy sencillos para capturar los patrones complejos de los datos, como la regresión lineal y logística.
En el aprendizaje supervisado, el sobreajuste se produce cuando nuestro modelo captura el ruido junto con el patrón subyacente de los datos. Ocurre cuando entrenamos mucho nuestro modelo sobre un conjunto de datos ruidosos. Estos modelos tienen un sesgo bajo y una varianza alta. Estos modelos son muy complejos, como los árboles de decisión, que son propensos a la sobreadaptación.

¿Por qué hay un equilibrio entre sesgo y varianza?
Si nuestro modelo es demasiado simple y tiene muy pocos parámetros, puede tener un sesgo alto y una varianza baja. Por otro lado, si nuestro modelo tiene un gran número de parámetros, entonces va a tener una alta varianza y un bajo sesgo. Así que tenemos que encontrar el equilibrio correcto/bueno sin sobreajustar e infraajustar los datos.
Esta compensación en la complejidad es la razón por la que hay una compensación entre el sesgo y la varianza. Un algoritmo no puede ser más complejo y menos complejo al mismo tiempo.
Error total
Para construir un buen modelo, necesitamos encontrar un buen equilibrio entre sesgo y varianza tal que minimice el error total.


Un equilibrio óptimo entre el sesgo y la varianza nunca sobreajustará ni subajustará el modelo.
Por lo tanto, comprender el sesgo y la varianza es fundamental para entender el comportamiento de los modelos de predicción.
¡Gracias por leer!