Método 1, malo: ORDER BY NEWID()
Fácil de escribir, pero funciona como basura caliente, porque escanea todo el índice agrupado, calculando NEWID() en cada fila:
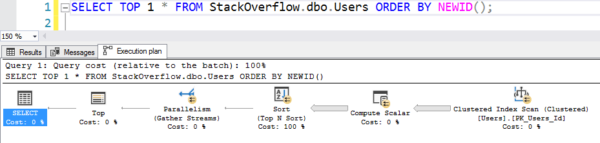
El plan con el escaneo
Eso tomó 6 segundos en mi máquina, yendo en paralelo a través de múltiples hilos, usando decenas de segundos de CPU para todo ese cálculo y ordenamiento. (Y la tabla de usuarios no tiene ni siquiera 1GB.)
Método 2, mejor pero extraño: TABLESAMPLE
Esto salió en 2005, y tiene un montón de gotchas. Se trata de elegir una página al azar, y luego devolver un montón de filas de esa página. La primera fila es un poco al azar, pero el resto no.
Transact-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
El plan parece que está haciendo un escaneo de la tabla, pero sólo está haciendo 7 lecturas lógicas:
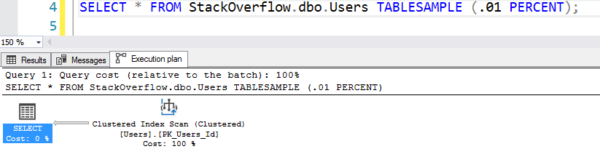
El plan con el falso escaneo
Pero aquí están los resultados – puedes ver que salta a una página aleatoria de 8K y luego empieza a leer filas en orden. No son realmente filas al azar.
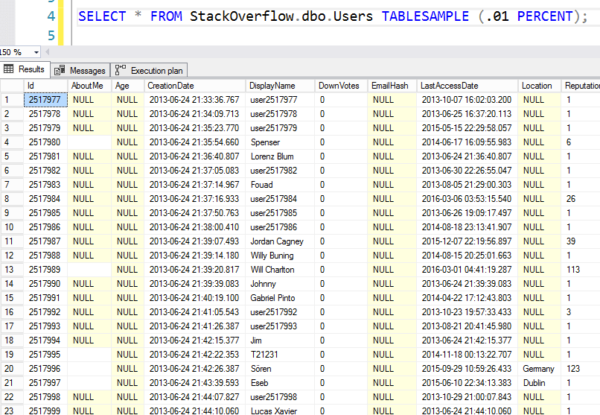
Al azar como los números de la lotería de la mafia
Puede utilizar el tamaño de la muestra ROWS en su lugar, pero tiene algunos resultados bastante extraños. Por ejemplo, en la tabla de usuarios de Stack Overflow, cuando dije TABLESAMPLE (50 ROWS), en realidad obtuve 75 filas. Eso es porque SQL Server convierte el tamaño de las filas a un porcentaje en su lugar.
Método 3, mejor pero requiere código: Clave primaria aleatoria
Obtenga el campo ID superior de la tabla, genere un número aleatorio y busque ese ID. Aquí, estamos ordenando por el ID porque queremos encontrar el registro superior que realmente existe (mientras que un número aleatorio podría haber sido eliminado.) Bastante rápido, pero sólo sirve para una sola fila aleatoria. Si quisieras 10 filas, tendrías que llamar a un código como este 10 veces (o generar 10 números aleatorios y usar una cláusula IN.)
El plan de ejecución muestra un escaneo de índice agrupado, pero sólo toma una fila – sólo estamos hablando de 6 lecturas lógicas para todo lo que se ve aquí, y termina casi instantáneamente:

El plan que puede
Hay un problema: si el Id tiene números negativos, no funcionará como se espera. (Por ejemplo, digamos que empiezas tu campo de identidad en -1 y pasas a -1, dirigiéndote siempre hacia abajo, como mi moral.)
Método 4, OFFSET-FETCH (2012+)
Daniel Hutmacher añadió esto en los comentarios:
Y dijo: «Pero sólo funciona correctamente con un índice agrupado. Supongo que es porque escaneará las filas (@rows) en un montón en lugar de hacer una búsqueda de índice»
Bonus Track #1: Míranos discutir esto
¿Te has preguntado alguna vez cómo es estar en la sala de chat de nuestra empresa? Esta discusión de 10 minutos en Slack te dará una buena idea:
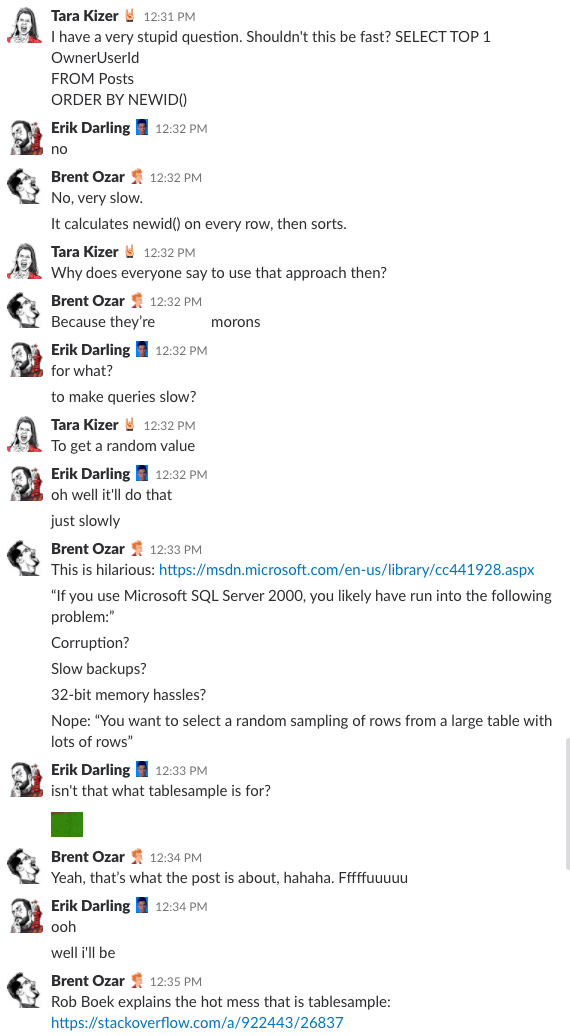
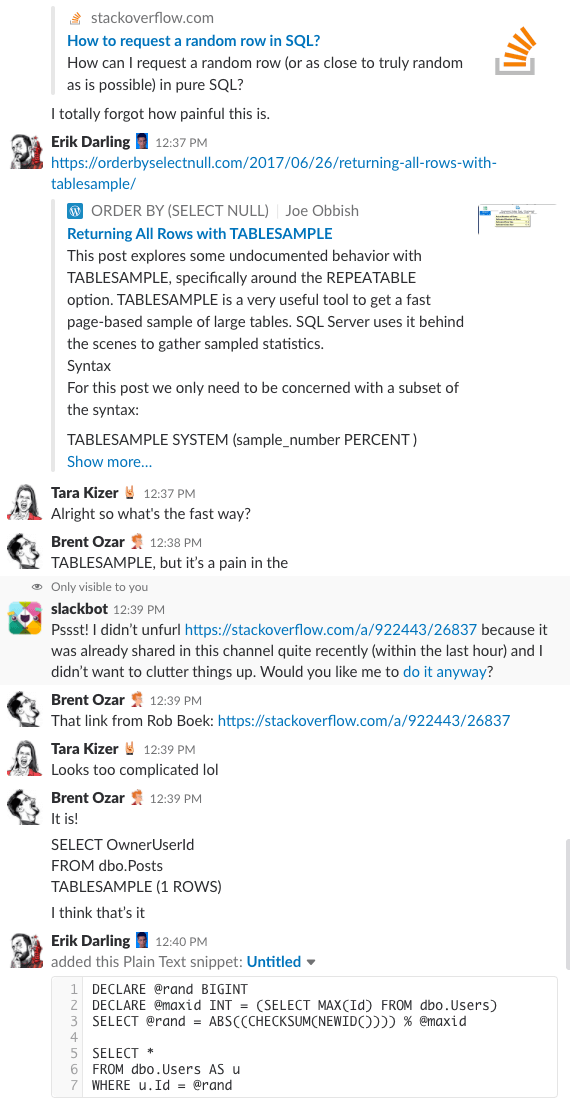
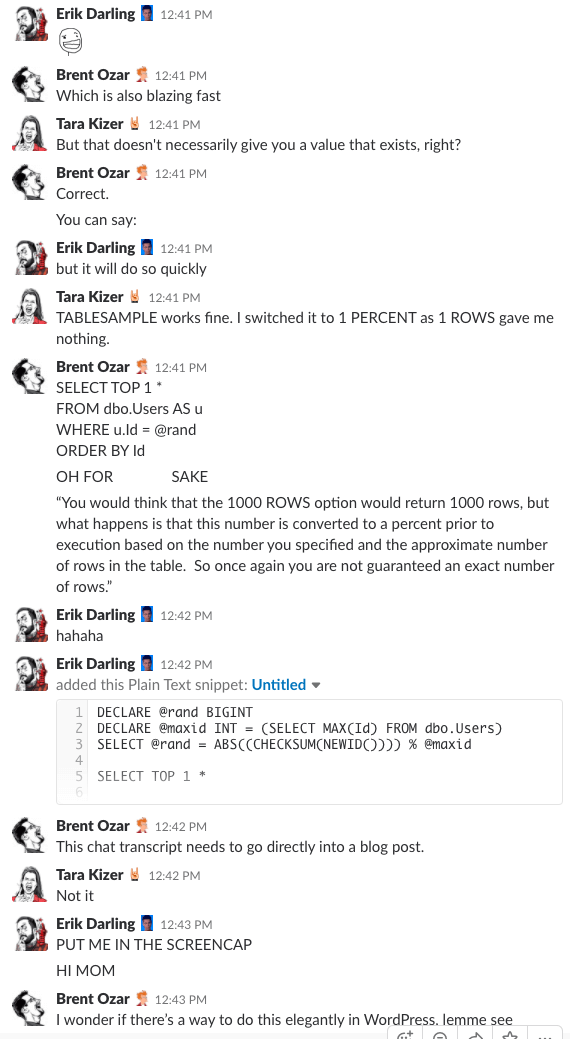
Alerta de spoiler: no lo hubo. Sólo hice capturas de pantalla.
Pista de bonificación nº 2: Mitch Wheat profundiza
¿Quieres un análisis en profundidad de la aleatoriedad de varias técnicas diferentes? Mitch Wheat se sumerge en profundidad, con gráficos completos.